FastAPI+Next.js+Supabase:全栈AI应用技术栈实战指南
FastAPI+Next.js+Supabase构建全栈AI应用的架构实践
本文以「Readme转网站」项目为例,介绍了一套全栈AI应用技术栈:Next.js作为BFF层处理前端交互,FastAPI配合Celery处理耗时AI任务,Supabase负责数据存储。该架构解决了Serverless时间限制、异步任务管理、实时进度反馈等AI应用典型难题,实现了各技术组件各取所长、独立扩缩容的目标。
为什么AI应用需要这套技术栈
做过AI应用开发的人大概都遇到过这个矛盾:Python在AI/ML处理上无可替代,但用它写前端体验实在一般;Next.js能构建出色的Web界面,但面对动辄几分钟的AI生成任务就显得捉襟见肘。
有没有一种架构能把两者的长处结合起来?
本文将拆解一套经过实战验证的全栈AI应用技术栈:FastAPI(Python后端)+ Next.js(前端/BFF层)+ Supabase(数据层)。我会以一个「Readme转网站」的真实项目为例,展示这套架构如何解决AI应用中的典型难题。
项目实例:Readme自动转网站
这个项目叫Readme2Site,功能很直观:用户提交一个GitHub仓库的README链接,AI将这份Markdown文件转化为一个精美的着陆页。用户可以预览效果,满意后一键发布。
需求看起来简单,但背后藏着不少技术挑战:
- AI生成完整HTML/CSS可能耗时数分钟
- 需要可靠的异步任务处理和状态管理
- 生成的产物需要持久化存储
- 前端要实时展示生成进度
这些需求叠加在一起,单靠Next.js或单靠Python都不够优雅。
Next.js为什么需要独立的Python后端
Next.js确实是全栈框架,但在AI应用场景下,搭配独立Python后端有几个绕不开的理由。
Serverless的时间限制
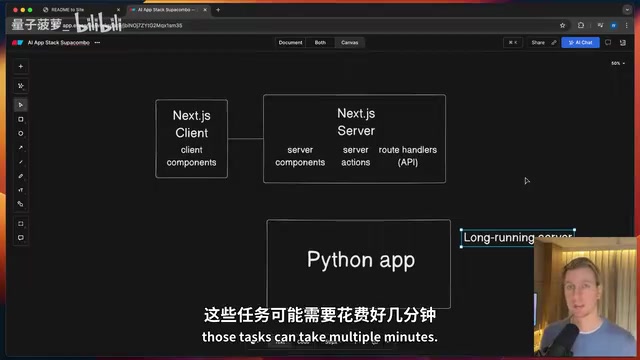
Next.js部署通常依赖Serverless Functions,这些函数有严格的执行时间上限(Vercel免费版10秒,Pro版60秒)。而AI任务动辄几分钟甚至20分钟以上,Python长运行服务器天然适合处理这类场景。
Serverless架构的时间限制源于其底层设计哲学。Serverless Functions(如AWS Lambda、Vercel Edge Functions)本质上是无状态的短生命周期容器,平台需要在全球数据中心动态分配和回收计算资源。为了保证资源利用率和防止单个任务独占计算资源,平台设置了严格的执行时间上限。Vercel免费版10秒、Pro版60秒的限制并非随意设定,而是基于「大多数Web请求应在秒级完成」的假设。超出限制的函数会被强制终止,导致请求失败。这对传统Web应用影响不大,但AI生成任务(如调用GPT-4生成完整HTML页面)往往需要30秒到数分钟,与Serverless的设计假设存在根本性冲突。解决方案有两类:一是使用长运行服务器(如本文的FastAPI方案);二是使用流式响应(Streaming)将长任务拆分为持续的小数据块输出,但后者对AI生成完整文件的场景并不总是适用。
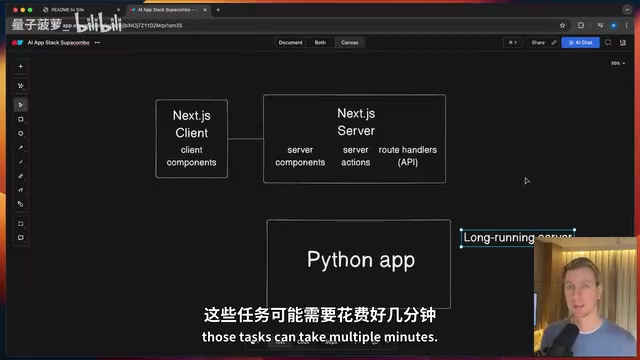
各取所长的技术生态
- Python端:丰富的AI/ML库生态、成熟的任务队列(Celery)、与OpenAI等API的原生集成
- Next.js端:静态页面生成(SSG)、Server Actions、流畅的前端开发体验
- 独立部署:两个服务可以分别扩缩容,互不影响
为什么选FastAPI而不是Django或Flask
在这个架构里,Python更多扮演「处理层」角色,不需要Django那套完整的ORM和Admin系统。FastAPI轻量、性能高、API优先的设计理念,与这种职责划分天然契合。加上它原生支持async和自动生成API文档,开发效率很高。
值得一提的是,Next.js在这套架构中实际上扮演了**BFF(Backend for Frontend,面向前端的后端)**的角色——这是由Sam Newman在2015年正式提出的微服务架构模式。其核心思想是为前端客户端提供专属的后端聚合层,而不是让前端直接调用多个微服务。Next.js接收浏览器请求,对数据进行验证和转换,然后调用FastAPI后端,最终将处理后的数据返回给前端。这种模式隐藏了后端服务的真实地址和内部架构,提升安全性;同时让Python后端专注于AI处理逻辑,职责分离更清晰。
数据流架构四阶段详解
整个应用的数据流分为四个阶段,每个阶段都有明确的技术选型考量。
阶段一:请求提交
用户在浏览器提交GitHub URL → Next.js Server Side接收 → 调用FastAPI端点。
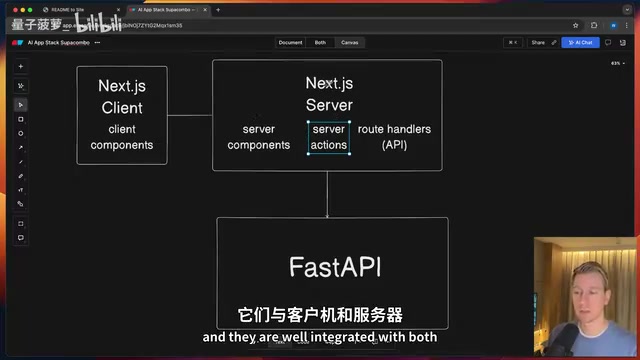
这里有个设计细节:请求先经过Next.js的API Route,再转发到Python后端。好处是可以利用Next.js的Server Actions做数据验证和预处理,同时对前端隐藏后端服务的真实地址。
阶段二:异步任务入队
FastAPI收到请求后,不会傻等AI生成完成,而是:
- 在Supabase数据库中创建项目记录
- 将生成任务提交到Celery任务队列
- 立即返回Job ID给前端
这是经典的异步任务模式——快速响应用户,耗时操作放后台。
Celery是Python生态中最成熟的分布式任务队列框架,其核心架构由三个组件构成:Producer(任务生产者,即FastAPI应用)、Broker(消息中间件,通常是Redis或RabbitMQ)和Worker(任务消费者)。当FastAPI调用.delay()方法时,任务被序列化后写入Redis队列,这个操作通常在1-5毫秒内完成,因此API可以立即返回响应。Celery Worker是独立运行的Python进程,持续监听Redis队列,一旦发现新任务就取出执行。这种生产者-消费者模式带来了关键优势:任务可以在多个Worker之间分发(水平扩展);Worker崩溃后任务不会丢失(消息持久化);可以设置任务优先级、重试策略和超时限制。在AI应用中,Celery内置的重试机制可以在OpenAI API限流时自动重试,避免任务永久失败。
阶段三:AI生成与结果存储
Celery Worker从队列中取出任务,调用OpenAI API生成HTML/CSS,然后将结果上传到Supabase Storage。
为什么用Storage而不是直接存PostgreSQL?三个原因:
- HTML产物是完整文件,只需整体读写,不需要字段级查询
- 文件可能很大(几十KB到几百KB),避免撑大
相关推荐
 教程攻略
教程攻略Cursor+Codex双IDE协同:开源项目二开实战方法论
基于实战经验总结的开源项目二次开发完整方法论,详解Cursor+Codex双IDE协同工作流,涵盖二开七环节、MVP验证、AI读源码技巧,帮助开发者三天跑通项目、两周完成业务集成。
 教程攻略
教程攻略Cursor多Agent实战:50分钟搭建Next.js全栈博客
使用Cursor IDE多Agent协作模式,50分钟内从零搭建全栈博客。涵盖Next.js、Clerk认证、Supabase数据库集成,详解4个AI Agent分阶段开发流程与关键避坑经验。
 教程攻略
教程攻略从零搭建AI软件工厂:Cursor工程师的多Agent协作实战经验
Cursor工程师Eric分享AI软件工厂构建实战:从自动化六层级、护栏设计、并行Agent管理到规模化扩展,详解如何用多Agent协作实现7×24小时高效软件开发。