PyTorch入门教程:张量操作与神经网络构建完全指南
PyTorch是Meta AI创建的开源深度学习框架,以动态计算图和GPU加速为核心特性。
PyTorch是Meta AI于2016年基于Lua版Torch库创建的开源深度学习框架,本质是张量编程库。其核心优势包括:动态计算图(Define-by-Run)通过有向无环图实现自动微分,支持运行时灵活调整网络结构;借助CUDA平台实现GPU并行加速,带来数十倍性能提升。开发者通过继承nn.Module定义网络结构和forward方法即可构建神经网络,已广泛应用于特斯拉自动驾驶、Stable Diffusion等顶级AI产品。
什么是PyTorch?
PyTorch是一个开源的深度学习框架,由Meta AI研究院(原Facebook AI研究实验室)于2016年创建。它的历史可以追溯到2002年基于Lua语言的Torch库——Torch由Ronan Collobert等研究者开发,底层C/CUDA实现性能优异,但Lua语言的小众性成为其推广的最大障碍。2016年,Facebook AI研究院(FAIR)团队决定将Torch的核心能力移植到Python生态,诞生了PyTorch。这一时机恰到好处:彼时Python已成为数据科学的事实标准语言,NumPy、SciPy等科学计算库构成了完善的生态基础,PyTorch得以快速崛起。
从本质上讲,PyTorch是一个张量编程库——张量即多维数组,用于表示深度神经网络中的数据和参数。
虽然听起来复杂,但PyTorch的设计哲学始终围绕「易用性」展开。只需几行Python代码,你就能训练一个机器学习模型。这也是它能被用于构建全球最知名AI产品的核心原因之一。
PyTorch的核心特性
动态计算图:灵活性的根基
PyTorch最受开发者青睐的特性之一是动态计算图(Dynamic Computational Graph)。理解它的价值,需要先了解其对立面——静态计算图。TensorFlow 1.x是静态图的典型代表:开发者必须先用符号化API「声明」整个计算流程,构建完整的计算图后再「编译」执行,类似于先画好完整施工蓝图再开工,调试时错误信息往往晦涩难懂,且无法使用Python原生的断点调试。
PyTorch的动态图(又称「Define-by-Run」)则完全不同:它通过构建一个由函数组成的**有向无环图(DAG)**来跟踪对张量执行的所有操作。在这个DAG中,节点代表张量操作(如加法、矩阵乘法),边代表数据流向。当你执行操作时,PyTorch不仅计算结果,还记录完整的计算历史链,为后续的自动微分(Autograd)提供基础——调用loss.backward()时,PyTorch沿DAG反向遍历,利用链式法则自动计算每个参数的梯度,无需手动推导偏导数。「无环」约束则确保反向传播不会陷入无限循环。
这意味着每次迭代后,你都可以根据需要灵活调整网络结构,而不必像静态图框架那样预先定义好整个计算流程。每一行Python代码的执行结果都可以立即检查,这种「所见即所得」的调试体验让研究者能够快速验证想法,大幅缩短从假设到实验结果的周期。正是这一差异,使PyTorch在学术研究社区迅速超越TensorFlow,成为顶级AI论文的首选框架。
GPU加速:借助CUDA实现高性能计算
借助英伟达的CUDA平台,PyTorch能够在GPU上实现高性能并行计算。CUDA(Compute Unified Device Architecture)是英伟达于2006年推出的并行计算平台,允许开发者直接编程控制GPU的数千个计算核心。GPU与CPU的架构差异决定了各自的适用场景:CPU拥有少量强大的核心,擅长复杂串行逻辑;GPU则拥有数千个相对简单的核心(如英伟达H100超过16000个CUDA核心),专为大规模并行计算设计。
深度学习中的矩阵乘法、卷积运算等操作天然具有高度并行性——计算一个1000×1000矩阵乘法时,每个输出元素的计算相互独立,可以同时进行。PyTorch通过.to(device)方法将张量和模型迁移到GPU内存,底层自动调用优化过的CUDA内核执行计算。对于大规模矩阵运算和深度学习训练而言,GPU加速往往能带来数十倍甚至上百倍的性能提升。
PyTorch的实际应用案例
PyTorch已被广泛应用于各类顶级AI产品的训练中:
- 计算机视觉:特斯拉自动驾驶仪(Tesla Autopilot)
- 图像生成:Stable Diffusion
- 语音识别:OpenAI的Whisper
这些案例充分证明了PyTorch在不同AI领域的通用性和强大能力。
从零开始:PyTorch张量操作基础
使用PyTorch的第一步是安装Python环境,如果需要GPU加速,还需安装对应版本的CUDA。将PyTorch导入Python文件后,就可以开始张量操作了。
张量本质上类似于多维数组。我们可以先用Python创建一个二维数组(矩阵),然后使用PyTorch将其转换为张量。在张量上,我们可以执行各种计算操作,例如将整数转换为随机浮点数,或者通过矩阵乘法进行线性代数运算。

这些基础操作看似简单,却是构建复杂神经网络的基石。理解张量的创建、变换和运算,是掌握PyTorch的第一道门槛。
用nn.Module构建你的第一个神经网络
nn.Module的设计哲学
nn.Module是PyTorch构建神经网络的基础抽象类,体现了面向对象编程与深度学习需求的深度融合。每个nn.Module实例维护两类核心状态:可学习的参数(Parameters,会被优化器自动追踪和更新)和子模块(嵌套的其他nn.Module实例)。这种层次化设计使得复杂网络可以像搭积木一样组合——一个ResNet可以由多个残差块组成,每个残差块又由卷积层、批归一化层等基础模块构成,而所有这些都是nn.Module的子类。此外,state_dict()和load_state_dict()方法使模型的保存与加载标准化,对模型部署和迁移学习至关重要。
定义网络结构
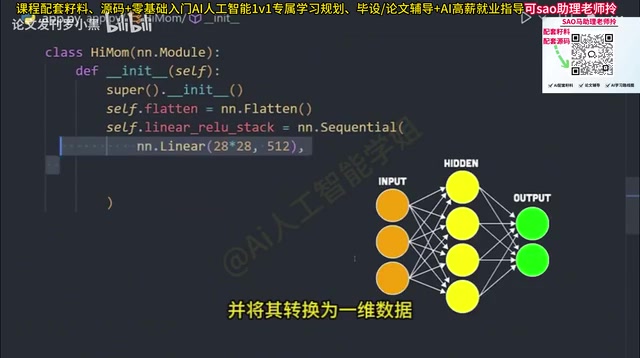
以图像分类器为例,我们需要定义一个继承自nn.Module的新类,在构造函数中逐层搭建网络:
- Flatten层:将多维输入(如图像)转换为一维数据
- Sequential容器:创建一个层容器,数据将依次流经其中的各层
- Linear全连接层:将28×28的扁平图像转换为512个输出,每个节点就像一个小型统计模型,在数据流经时不断猜测输出并更新权重
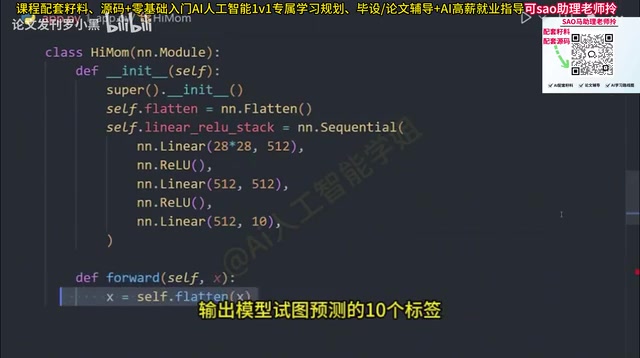
- ReLU激活函数:ReLU(Rectified Linear Unit)的数学定义为 f(x) = max(0, x),它引入非线性——没有激活函数,无论网络多深,多个线性变换的叠加仍是线性变换,网络将失去拟合复杂函数的能力。相比Sigmoid和Tanh,ReLU计算高效且有效缓解「梯度消失」问题,在正数区间梯度恒为1,信号可无衰减地反向传播。当特征被判定为重要时输出该节点的值,否则输出0
- 输出层:最终的全连接层,输出模型试图预测的10个类别标签
前向传播与模型运行
网络结构定义完成后,关键的一步是定义forward方法,用于描述数据在网络中的流动路径。forward方法定义了数据的前向流动路径,而反向传播则由Autograd引擎根据计算图自动处理,开发者无需在nn.Module中显式定义backward方法——这正是PyTorch动态图机制的优雅之处。
最后,将模型实例化并部署到GPU上,传入输入数据时会自动调用forward方法,完成训练和预测的全流程。
# 简化的代码逻辑
model = NeuralNetwork().to(device)
output = model(input_data) # 自动调用forward方法
PyTorch学习路径:从入门到实战
对于初学者而言,掌握PyTorch可以遵循以下渐进式路径:
- 基础阶段:理解张量概念和基本操作,熟悉NumPy与PyTorch张量的互转
- 核心阶段:掌握
nn.Module的使用、损失函数的选择、优化器的配置 - 实战阶段:从简单的图像分类任务入手,逐步尝试NLP、CV等不同领域的项目
- 进阶阶段:学习自定义数据集、模型调优、分布式训练等高级特性
PyTorch的生态系统非常完善,官方文档和社区教程资源丰富。关键在于动手实践——理论知识只有在实际编码中才能真正内化为能力。深度学习框架的学习从来不是一蹴而就的,但PyTorch的设计理念确实大大降低了入门门槛,让更多开发者能够快速上手并构建出有价值的AI应用。
核心要点
- PyTorch是Meta AI创建的开源深度学习框架,脱胎于2002年的Lua版Torch库,核心是张量编程,支持动态计算图和GPU加速
- 动态计算图基于有向无环图(DAG)实现自动微分,允许运行时修改网络结构,是PyTorch区别于静态图框架的关键优势
- CUDA平台使PyTorch能够调用GPU的数千个并行计算核心,对矩阵运算密集的深度学习训练带来数十倍性能提升
- PyTorch已被用于训练特斯拉自动驾驶、Stable Diffusion、OpenAI Whisper等知名AI产品
- 构建神经网络的核心步骤包括继承
nn.Module定义网络层结构、实现forward前向传播方法、部署到GPU进行训练 - 学习路径建议从张量操作基础出发,经过nn.Module核心概念,逐步过渡到实战项目
相关推荐
 教程攻略
教程攻略Cursor+Codex双IDE协同:开源项目二开实战方法论
基于实战经验总结的开源项目二次开发完整方法论,详解Cursor+Codex双IDE协同工作流,涵盖二开七环节、MVP验证、AI读源码技巧,帮助开发者三天跑通项目、两周完成业务集成。
 教程攻略
教程攻略Cursor多Agent实战:50分钟搭建Next.js全栈博客
使用Cursor IDE多Agent协作模式,50分钟内从零搭建全栈博客。涵盖Next.js、Clerk认证、Supabase数据库集成,详解4个AI Agent分阶段开发流程与关键避坑经验。
 教程攻略
教程攻略从零搭建AI软件工厂:Cursor工程师的多Agent协作实战经验
Cursor工程师Eric分享AI软件工厂构建实战:从自动化六层级、护栏设计、并行Agent管理到规模化扩展,详解如何用多Agent协作实现7×24小时高效软件开发。