企业大模型选型指南:Llama3.1、Qwen2.5、DeepSeek深度对比

企业私有化部署开源大模型的选型指南与决策框架
本文从模型能力、硬件需求、业务场景三个维度,对Qwen 2.5、Llama 3.1、DeepSeek、Mistral等主流开源大模型进行横向对比。文章指出,企业选型应围绕三大核心问题展开:业务语言决定模型底座(中文选Qwen,英文选Llama),硬件资源决定参数规格(需考虑显存、量化技术等),运营能力决定部署方式。为技术决策者提供了系统化的选型框架。
企业为什么需要认真做大模型选型?
随着大模型技术的快速发展,越来越多的企业开始考虑私有化部署开源大模型,以满足数据安全、定制化和成本控制等需求。所谓私有化部署(On-Premise Deployment),是指企业将大模型完整运行在自有或托管的服务器上,数据不经过任何第三方云端API——这在金融、医疗、政务等对数据合规要求严格的行业尤为关键。相比调用云端API,私有化部署的优势在于数据主权完全掌握在企业手中、可根据业务数据进行深度定制、长期使用成本可控;但其挑战同样明显:需要自建GPU基础设施、具备专业的模型运维能力,并持续跟进开源社区的模型迭代。
然而,面对市场上琳琅满目的开源模型——Llama 3.1、Qwen 2.5、DeepSeek、Mistral等——企业该如何做出正确的选型决策?
本文将从模型能力、硬件需求、业务场景三个维度,对主流开源大模型进行深度对比分析,帮助技术决策者快速锁定最适合自身业务的模型方案。
主流开源大模型能力横向对比
目前企业级应用中,有几款开源模型值得重点关注。从参数量、编程能力、中文支持、多语言能力等多个维度来看,各模型各有所长。
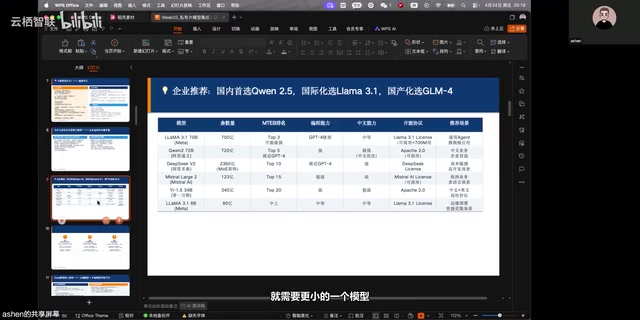
Qwen 2.5(千问):中文业务场景首选
对于国内企业而言,Qwen 2.5(千问2.5)是当前中文业务的首推模型。它在中文理解和生成方面表现优异,72B版本的能力尤为突出。在实际部署中,7B版本可以用于推理运行,而微调训练时可以选择更小的1.5B版本以降低资源消耗。这种灵活的参数规格设计,让不同规模的企业都能找到适合自己的方案。
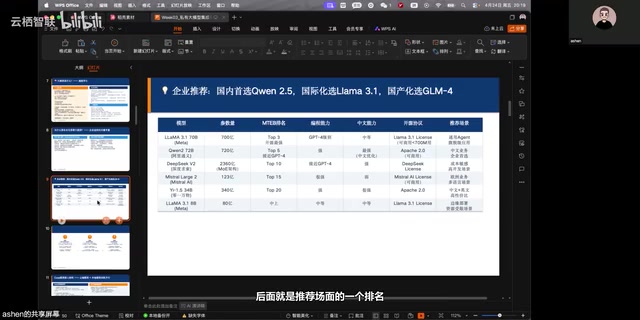
Llama 3.1:通用Agent旗舰级应用
Meta推出的Llama 3.1定位为通用Agent的旗舰级模型,在英文场景下表现卓越。它拥有从8B到405B的多个参数版本,覆盖了从边缘部署到数据中心的全场景需求。其中405B版本需要约640GB显存才能完整加载运行,对硬件要求较高,但在综合能力上确实达到了开源模型的顶级水平。
DeepSeek:高并发企业场景的利器
DeepSeek采用了MOE(Mixture of Experts,混合专家)架构,这使得它在企业级高并发场景中具有独特优势。MOE是一种稀疏激活的神经网络设计范式,其核心思想是将模型拆分为多个"专家"子网络,每次推理时只激活其中一小部分专家,而非像密集模型那样激活全部参数。以DeepSeek-V2为例,其总参数量达236B,但每次推理仅激活约21B参数,在保持模型容量的同时大幅降低了单次推理的计算量——这正是其在高并发场景下实现更高吞吐效率的根本原因。虽然整体部署成本相对较高,但MOE架构的特性使其在处理大量并发请求时效率更高。DeepSeek团队在技术报告中非常坦诚地分析了自身的优势和不足,这种务实的态度也让开发者社区对其评价颇高。
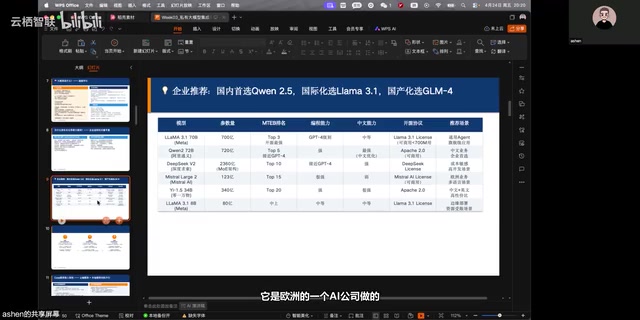
Mistral:多语言国际化场景的选择
Mistral是来自欧洲的AI公司,其模型在多语言支持方面表现不错。早期的对话能力相当出色,但在多模态、Skills、Agent等能力快速迭代的阶段,Mistral的发展节奏相对放缓。不过对于有多语言需求的欧洲或国际化业务场景,它仍然是一个值得考虑的选项。
其他值得关注的开源模型
- 智谱清言GLM:国产模型中综合能力不错的选择
- 01万物:中英双语支持,部署成本较低
- Llama 3.3 8B:适合边缘部署和资源受限场景的轻量方案
企业大模型选型的三大核心问题
企业在进行大模型选型时,需要系统性地考虑以下三个关键问题:
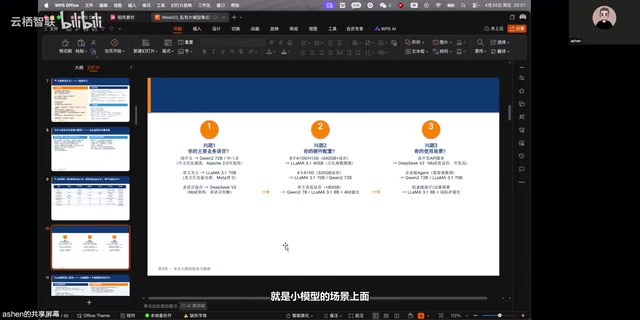
业务语言决定模型底座
语言需求是选型的首要考量因素:
| 语言需求 | 推荐模型 |
|---|---|
| 纯中文 | Qwen 2.5(千问) |
| 纯英文 | Llama 3.1 |
| 多语言混合 | DeepSeek / Mistral |
这一判断标准简单直接——模型在哪种语言上训练数据最充分,就在哪种语言上表现最好。Qwen在中文语料上的积累使其成为中文场景的不二之选,而Llama 3.1在英文能力上则明显领先。
硬件资源决定参数规格
硬件配置直接决定了能部署多大参数量的模型。以企业常用的A100/H100显卡为例:
- 单卡A100(80GB显存):可运行7B-13B级别模型
- 4卡A100(320GB显存):可运行70B级别模型
- 8卡A100(640GB显存):可运行Llama 3.1 405B等超大模型
模型参数量与显存的换算关系是企业必须掌握的基础知识。一般来说,FP16精度下每10亿参数约需2GB显存。值得注意的是,推理阶段还需为KV Cache预留额外显存——KV Cache是Transformer架构的核心推理优化机制,它将历史token的注意力键值对缓存在显存中以避免重复计算,但其占用量会随序列长度和并发批次线性增长,在长文本或高并发场景下可能成为显存瓶颈。因此实际显存需求往往高于单纯按参数量估算的结果。
通过量化技术(如INT4/INT8),可以显著降低显存需求。量化是将模型权重从高精度浮点数(FP16)压缩为低精度整数的技术:INT4量化理论上可将显存占用压缩至FP16的四分之一,常用工具包括GPTQ、AWQ、GGUF等。量化的代价是模型精度的轻微下降,通常在可接受范围内,但对于数学推理、代码生成等高精度任务需谨慎评估。
运营能力决定部署方式
私有化部署不仅仅是"把模型跑起来
相关推荐
 行业洞察
行业洞察AI产品开发实战:模型选择、护城河构建与商业化路径
分享AI产品开发的实战策略,包括为什么不应从头训练模型、如何选择API调用与微调时机、构建产品护城河的关键要素,以及从评测体系搭建到商业化落地的完整执行路径。
 行业洞察
行业洞察没有想要的产品?自己做才是独立开发者的最佳起点
市面上找不到满意的产品怎么办?从个人痛点出发,自己动手开发,正是独立开发者最好的切入方式。本文分析为什么小众需求反而是理想的创业起点,以及AI工具如何让一个人也能快速把想法变成产品。
 行业洞察
行业洞察OpenAI Codex教程遭批量搬运,AI内容农场现象引关注
B站上至少9个账号批量发布相同的OpenAI Codex教程视频,暴露AI工具教程领域的内容农场问题。本文分析批量搬运的典型特征,探讨平台治理挑战,并提供辨别原创内容的实用建议。