企业级Claude Code工作流:五大核心组件搞定百万行代码

企业级AI编程效率取决于模型周围的工程脚手架,而非模型本身。
Anthropic官方博客揭示,大型代码库中AI编程频频翻车的根因不是模型能力不足,而是缺乏完善的工程脚手架(Harness)。传统RAG因索引滞后在活跃代码库中失灵,Claude Code采用智能体搜索直接操作本地文件系统。围绕这一方法,需构建五大核心组件(分层CLAUDE.md、Hooks、Skills、Plugins、MCP服务器)和两个高级能力(LSP集成、Subagent),并通过精准配置、定期维护和组织专人负责三大模式实现成功部署。
面对百万行祖传代码,AI编程工具频频翻车——找不到上下文、引用已删除的函数、把好好的代码改烂。很多人把问题归咎于模型能力不足,期待下一代大模型来拯救。但Anthropic官方最近发布的一篇硬核博客揭示了一个扎心的真相:决定AI编程效率上限的,不只是模型本身,还有你围绕模型搭建的工程生态。
这套生态系统被称为"Harness"(脚手架),包含五个核心组件和两个高级能力。本文将基于B站UP主"为什么叫QQ"对该官方博客的深度解读,系统梳理如何在企业级代码库中让Claude Code真正发挥作用。
为什么传统RAG在大型代码库里失灵
大多数AI编程工具依赖RAG(检索增强生成)技术:将代码库向量化存入数据库,提问时搜索相关代码片段。这在小项目中没问题,但在大型团队协作中会遇到致命缺陷。
想象一个几千名工程师、每天几千个Commit的代码库——RAG的索引根本追不上代码变化的速度。你下午提问搜到的可能是两周前的旧代码,函数名一样但逻辑已经改了;更糟的是,搜到一个上个月就被删掉的函数,AI看不出它已经"死了",直接引用,代码一跑就报错。
这是RAG在活跃大型代码库里的核心问题:索引滞后导致信息过时。
Claude Code采用了完全不同的方法——Agentic Search(智能体搜索)。它不依赖任何中央索引,而是像一个真正的工程师一样直接在本地文件系统中操作:用grep搜索、顺着引用关系追踪、打开文件查看。这意味着AI看到的永远是最新的代码,没有延迟,没有过时的索引。
但这个方法有一个前提:AI必须有足够的上下文知道应该去哪里找。 如果信息太少,它就会漫无目的地搜索,直到上下文窗口爆掉。这正是五大核心组件要解决的问题。
五大核心组件:构建AI的导航系统
1. CLAUDE.md:分层的项目上下文配置
CLAUDE.md是Claude Code每次会话都会自动加载的项目上下文文件。聪明的团队不会把所有规则都堆在根目录,而是分层编写:

- 根目录CLAUDE.md:只写最核心的架构信息,比如"这是一个微服务系统,分为支付、订单、库存三个模块"
- 子目录CLAUDE.md:写局部规范和细节,如特定模块的编码约定、测试要求等
Claude会自动加载当前工作目录的CLAUDE.md,并向上遍历加载父目录的配置。关键原则是根目录保持精简,避免每次会话都加载一堆无关信息浪费宝贵的上下文窗口。
2. Hooks:从拦截器到自我进化引擎
很多人把Hooks当成简单的拦截器,用来阻止AI犯错。但真正的高级玩法是用Hooks驱动知识沉淀和自动化流程:
- Stop Hook:每次AI完成任务后触发,让AI自我反思——这次做了什么、踩了什么坑、有没有应该沉淀进CLAUDE.md的规则。官方强调这些建议应进入人工review,而非让AI无审核地修改团队规则。
- Start Hook:根据开发者的工作环境动态加载团队特定的上下文,实现个性化配置自动化。
- 自动化检查:让Hooks自动执行linting和格式化,比让AI记住一堆格式要求靠谱得多。
这种机制让团队的AI编程能力不断积累,每一次使用都在为下一次使用铺路。
3. Skills:按需加载的专业知识模块
大型项目的任务类型极其多样——安全审查、性能优化、文档更新、数据库迁移,每个都需要专门知识。如果全部塞给AI,上下文窗口会瞬间爆掉。
Skills采用按需加载的思路:做安全审查时加载安全Skill,做文档更新时加载文档Skill。更聪明的是,Skills可以绑定到特定目录——支付团队的部署Skill绑定到payment目录,AI在其他地方工作时永远不会加载它,进入支付模块时自动出现。
这种设计让AI在不同场景下都能获得精准的专业知识,而不会被无关信息干扰。
4. Plugins:团队知识分发的关键
大型公司的常见问题是:好的配置往往是某个小团队的秘密武器,其他团队不知道就各自瞎折腾,导致知识碎片化严重。
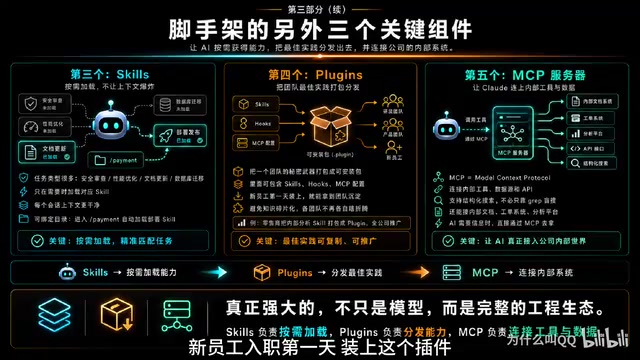
Plugins将一个团队的最佳实践打包成可安装的包——包括Skills、Hooks、MCP配置,所有东西都在一起。新员工入职第一天装上插件,就能拿到团队沉淀过的上下文和能力。
官方提到一个典型案例:某大型零售商构建了一个Skill连接Claude到内部分析平台,业务分析师可以直接在Claude里拉数据。他们把这个Skill打包成Plugin在全公司推广,效果显著提升了跨团队的数据分析效率。
5. MCP服务器:连接内部系统的桥梁
MCP(Model Context Protocol,模型上下文协议)让Claude Code连接到内部工具、数据源和API。最高级的团队甚至构建了MCP服务器来暴露结构化搜索能力,AI不用自己grep搜索,而是直接调用MCP工具精准检索。
还有团队连接Claude到内部文档系统、工单系统、分析平台,AI需要什么信息直接通过MCP获取。这种集成方式让AI编程不再是一个孤立的工具,而是融入企业整体技术栈的一部分。
两个高级能力:LSP集成与Subagent
LSP集成:大型代码库的精准导航
LSP(Language Server Protocol,语言服务器协议)解决的是大型代码库中的精准导航问题。在大型C++或Java项目里,同名函数可能有上百个,仅靠字符串搜索必然出错。有了LSP,AI就能像开发者按Ctrl+Click一样精准跳转到符号定义。
官方提到与一家大型企业软件公司合作,该公司在推广Claude Code之前,先在全公司部署了LSP集成配置,投入产出比非常高。
Subagent:探索与编辑的分离
Subagent是独立的Claude实例,拥有自己的上下文窗口。它可以接一个任务、完成工作、只把最终结果返回给主Agent。
典型用法是让Subagent去映射一个子系统,把发现写进文件,然后主Agent用这个文件作为上下文来编辑代码——实现探索与编辑的分离。这种架构有效避免了单一上下文窗口被大量探索性信息占满的问题。
三大成功部署模式
模式一:精准的可导航性配置
AI的能力上限取决于它能找到的上下文质量。太多上下文性能下降,太少上下文AI就瞎猜。平衡之道:
- CLAUDE.md保持精简和分层,避免信息过载
- 初始化时在子目录而非根目录启动(Claude会自动向上加载父级配置)
- 测试和lint命令按子目录配置,改了一个服务就只跑那个服务的测试
- 用ignore/deny规则排除生成文件、构建产物和第三方代码
模式二:随模型进化定期维护配置
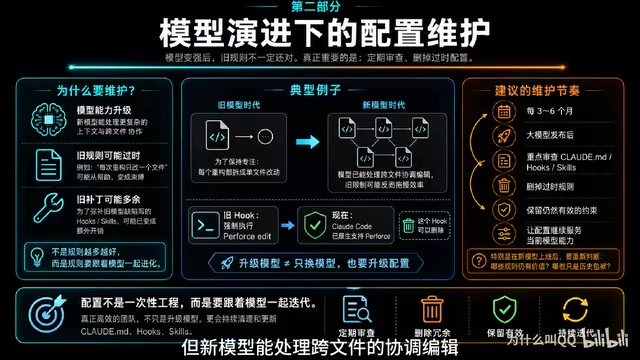
当新模型发布时,之前的规则可能就过时了。比如"每个重构都拆成单文件改动"这条规则,可能是为了帮助旧模型保持专注,但新模型能处理跨文件协调编辑时,它就变成了束缚。
官方建议每3-6个月做一次配置审查,特别是在大模型发布后。及时清理过时的限制性规则,才能充分释放新模型的能力。
模式三:组织层面的专人负责
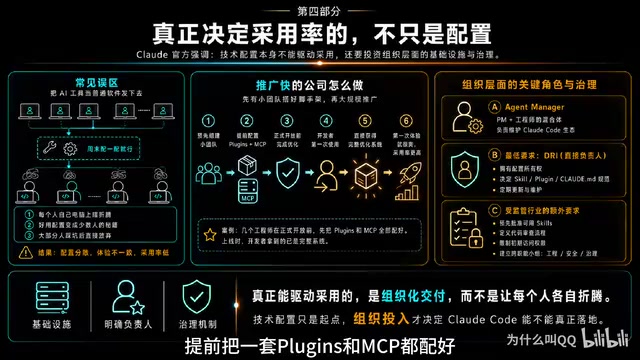
推广最快的公司都有一个共同点:在大规模推广之前,有专门的小团队提前搭好基础设施。有公司甚至组建了"Agent Manager"角色——PM和工程师的混合体,专门负责维护Claude Code的整个生态。
最低要求是有一个DRI(直接负责人),拥有Claude Code配置的所有权,定期更新和维护。在受监管行业,还需要提前定义哪些Skills被批准、代码审查流程怎么走、初期访问权限怎么限制。
写在最后
代码库越来越庞大,未来我们面对的核心挑战不再是"写代码",而是**"如何管理AI写代码"**。那些率先建立完善AI脚手架、把个人经验沉淀为组织插件的团队,会在采用速度、上下文复用和最佳实践传播上形成明显优势。
你可能没注意到,官方的这些建议主要面向常规软件工程环境——工程师是主要代码贡献者、仓库用Git、目录结构标准。如果你的场景涉及游戏引擎、大量二进制资产或非常规版本控制,则需要额外的判断和适配。
核心行动建议:别再无脑喂代码了。 用分层的CLAUDE.md、按需加载的Skills、精准的LSP给你的AI搭个企业级脚手架——最重要的是,找一个人或一个小团队负责维护这个脚手架,让好的配置变成全公司的财富。
相关推荐
 教程攻略
教程攻略Cursor+Codex双IDE协同:开源项目二开实战方法论
基于实战经验总结的开源项目二次开发完整方法论,详解Cursor+Codex双IDE协同工作流,涵盖二开七环节、MVP验证、AI读源码技巧,帮助开发者三天跑通项目、两周完成业务集成。
 教程攻略
教程攻略Cursor多Agent实战:50分钟搭建Next.js全栈博客
使用Cursor IDE多Agent协作模式,50分钟内从零搭建全栈博客。涵盖Next.js、Clerk认证、Supabase数据库集成,详解4个AI Agent分阶段开发流程与关键避坑经验。
 教程攻略
教程攻略从零搭建AI软件工厂:Cursor工程师的多Agent协作实战经验
Cursor工程师Eric分享AI软件工厂构建实战:从自动化六层级、护栏设计、并行Agent管理到规模化扩展,详解如何用多Agent协作实现7×24小时高效软件开发。