Qoder 1.0深度实测:AI自主编程平台到底好不好用?

编程范式从辅助编程转向可托管执行单元,Qoder 1.0展现国产AI IDE新高度。
三大巨头相继推出长任务执行能力,标志着编程范式从同步辅助转向可托管执行单元。阿里发布的Qoder 1.0以Quest任务单元为核心,采用三栏式交互和Multi-Agent专家团队协作模式,支持多任务并行自主运行。实测显示其Spec机制有效防止目标漂移,专家团队分工协作产出的研究报告质量超越传统Deep Research,Knowledge知识引擎则为长线项目提供持久化知识支撑。
编程范式正在转变:从辅助编程到可托管执行单元
短短11天内,三大巨头相继推出了类似功能——Codex、Claude Code、Gemini Agent都上线了名为「Goal」的长任务执行能力。这件事本身就说明了一个趋势:编程的下一步不是辅助编程,而是可托管的执行单元。
所谓「可托管执行单元」,其技术根源来自软件工程中的异步任务调度思想。传统AI编程助手(如早期的GitHub Copilot)本质上是同步的「请求-响应」模式:开发者提问,模型回答,人类审查后继续。而「可托管执行单元」则借鉴了云计算中无服务器函数(Serverless Function)和容器化任务的设计哲学——任务被封装为独立单元,可以在后台自主运行、暂停、恢复,并在完成后返回结果。这种范式转变的技术基础是大语言模型上下文窗口的大幅扩展(从4K到200K+ tokens)、工具调用(Function Calling)能力的成熟,以及ReAct(Reasoning + Acting)框架的工程化落地。当模型能够自主规划步骤、调用外部工具、处理中间错误并持续推进目标时,「托管」才真正成为可能。
在这波浪潮中,阿里最近发布的Qoder 1.0(通义灵码旗下产品)把长任务的「省约与介入」做到了一个新高度。经过两天的深度实测(消耗了一整个Pro账号的积分),我认为这可能是目前体验最好的国产AI IDE,尤其在Agent团队协作和交互设计方面有不少亮点。

核心架构:Quest任务单元与三栏式交互
Qoder 1.0的核心概念是Quest(任务单元),每个Quest代表一个独立的长任务,支持多任务并行执行。整体界面采用三栏式布局:
- 左栏(导航管理):任务列表,可同时并行多个Quest
- 中栏(会话流):实时查看任务推进过程
- 右栏(产物区):查看知识、记忆和最终产物
这种设计的好处在于,你不需要盯着Agent干活。可以同时启动多个任务,每个任务自主运行20到40分钟不等,期间随时切换查看进度,也可以去忙别的事情。这正是「可托管执行单元」理念落地后的样子。
实战测试:用Qoder做一次Readme最佳实践研究
为什么选这个任务?
做开源项目、发布产品或工具的人都会遇到一个问题:Readme怎么写、官网怎么呈现、如何在第一眼就建立用户信任。这是一个实实在在的需求,也适合用来检验AI自主开发平台的研究能力。
我选择了Expo专家团队模式来完成这个任务,并启用了**Spec(任务计划书)**功能。
值得一提的是,Spec机制在工程上解决的是长任务执行中的「目标漂移」问题。在没有明确规划的情况下,Agent在多步推理中容易偏离原始意图,产生「幻觉性执行」(Hallucinated Execution)。Spec机制强制Agent在执行前生成结构化计划,包括任务分解、资源分配、验收标准等,相当于为Agent提供了「执行合同」——这与软件工程中「测试驱动开发」(TDD)的思路异曲同工:先定义预期结果,再驱动执行过程。从用户体验角度,Spec也提供了人类介入和修正的自然节点,避免Agent在错误方向上长时间空转。
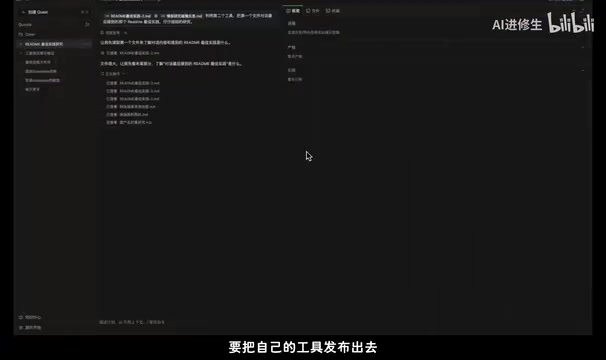
专家团队的分工设计
点击Spec运行后,系统自动创建了多个子Agent并开始并行工作。在专家全景图中可以看到每个子Agent的状态。专家团总共有四个成员,分工相当考究:
- 调研员A:分析GitHub高星Readme,进行对标采样
- 调研员B:搜索行业文章及指南,收集最佳实践
- 调研员C:直接去社交平台找经验帖,获取一线实践
- 全栈工程师:负责整合信息并输出最终产物
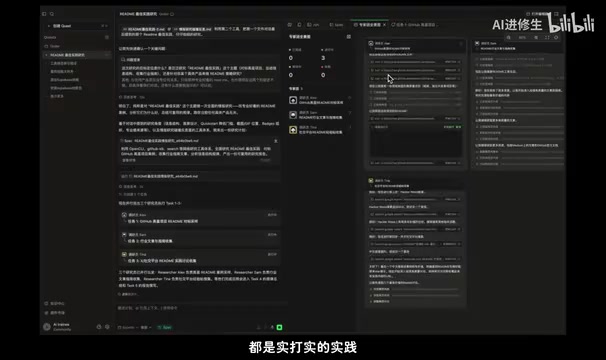
这种专家团队模式属于Multi-Agent系统(MAS)的工程实现。Multi-Agent系统起源于分布式人工智能研究,核心思想是将复杂任务分解给多个具有不同专长的智能体并行处理,再由协调者整合结果。在大语言模型时代,每个子Agent本质上是一个带有特定系统提示(System Prompt)和工具权限的模型实例。三调研员+工程师的模式对应了经典的「分工-整合」范式:调研员负责信息采集(对应MapReduce中的Map阶段),全栈工程师负责综合输出(对应Reduce阶段)。相比单Agent顺序执行,Multi-Agent并行架构的优势在于减少单点瓶颈、降低上下文污染风险、通过角色专业化提升各子任务质量。
三个调研员从不同维度切入同一主题——学术研究、行业标准、社区实践——这种组合让研究结果远比单一视角深入。右侧还有可视化的画布卡片,可以切换不同视图查看文件和最终成果,方便审查整个任务执行的中间过程。
研究成果质量怎么样?
可以很负责任地说:最终的研究报告比我用过的任何模型的Deep Research功能都要好。它和大语言模型直接生成的内容有明显区别——信息更扎实、结构更合理、实操性更强。
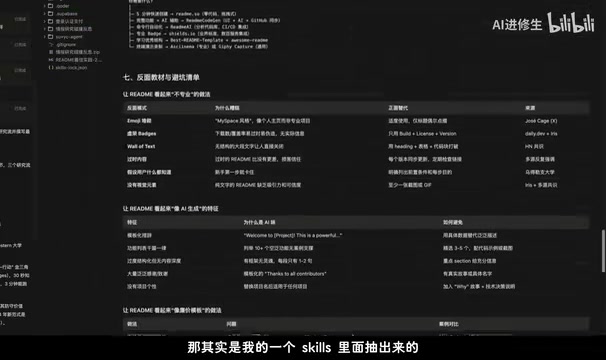
不过需要说明的是,这份高质量成果并非仅靠Qoder的Agent框架。在最初的提示词中,我提供了一份自己过往做各种主题研究的MD文档(从个人Skills库中抽取),这份「种子知识」为Agent指明了研究方向和质量标准。好的提示词 + 强大的Agent框架 = 超预期的产出,这个公式依然成立。
知识引擎:为长线工作而生
Qoder 1.0中有一个值得单独拿出来说的功能——Knowledge(知识引擎)。打开Knowledge面板,系统会自动生成知识架构、规范和技术栈信息。
在技术层面,Knowledge引擎与RAG(Retrieval-Augmented Generation,检索增强生成)密切相关。RAG由Meta AI在2020年提出,核心思路是将外部知识库与生成模型结合:先从知识库中检索相关内容,再将其注入模型上下文以提升回答质量。传统AI编程工具的局限在于依赖有限的上下文窗口——每次对话结束,积累的项目理解便随之消失。Knowledge引擎通过持久化存储项目的技术栈、架构规范、历史决策等结构化知识,
相关推荐
 产品体验
产品体验Qoder vs Cursor实测对比:同样20美金谁更强?
实测对比Qoder和Cursor两款AI IDE,从Agent自主修复能力、人工沟通次数、架构决策等维度评测。Qoder仅需2次沟通完成任务,Cursor需8次。详细分析两者差异,帮你选择最适合的AI编程工具。
 产品体验
产品体验Cursor云Agent演示:打通软件开发全链路瓶颈
深度解析Cursor云Agent最新Demo,展示如何通过云端虚拟机、自动测试产物和全链路控制平面,系统性消除软件开发生命周期中的人类瓶颈,让Agent自主运行、人按需介入。
 产品体验
产品体验Cursor 3.0深度解析:多Agent并行、Design Mode与Best-of-N模型对比
Cursor 3.0正式发布,从AI辅助编程工具进化为Agent舰队指挥中心。本文详解多智能体并行、Design Mode可视化编辑、Best-of-N多模型择优等核心功能,解读AI编程新范式。