Qwen3.7 Max深度解析:成本仅GPT十分之一,专为智能体而生
阿里千问Qwen3.7 Max以极低成本和超长续航定位智能体赛道,重新定义大模型竞争规则。
阿里发布的千问Qwen3.7 Max定位AI智能体,而非传统聊天机器人。它以1.3美元完成56%性能提升,远超Claude Opus 4的12美元/28%,性价比碾压对手。支持35小时连续执行、1200次工具调用,前端开发能力突出。但缺乏多模态能力、审美不稳定且依赖提示词质量。该模型标志着大模型竞争从"比智商"转向"比耐力和成本"的新阶段。
不是聊天机器人,而是「赛博包工头」
阿里最新发布的千问 Qwen3.7 Max,定位从一开始就和传统大模型不同——它不是用来陪你闲聊的,而是瞄准了**智能体(Agent)**这块最具商业价值的蛋糕。
所谓智能体,说人话就是:你不再需要一轮一轮地向AI提问,而是把一个复杂项目直接扔给它。它会像一个不需要睡觉的「赛博包工头」,自己调用工具、写代码、调试、改错,一条龙完成任务。对于普通人来说,这意味着搭建一个小工具、写一套自动化流程、做一个内部系统,不再需要排期等开发资源,先让AI把骨架和初版跑出来,成本几乎可以忽略不计。
智能体技术背景:AI Agent具备自主规划、工具调用和多步骤执行能力,其底层架构通常基于「ReAct」框架(Reasoning + Acting),让模型在每一步先推理再行动,形成「思考→工具调用→观察结果→再思考」的闭环。典型的工具调用包括:代码执行器、网络搜索、文件读写、API接口等。OpenAI的Function Calling、Anthropic的Tool Use以及阿里的Qwen Tool都是这一范式的具体实现。Agent的商业价值在于它能将人类的「意图」直接转化为「结果」,跳过中间繁琐的人工操作步骤,这也是为什么各大厂商都在将Agent能力作为下一阶段的核心竞争力。
这个定位的转变意义深远。过去我们评价大模型,看的是「谁更聪明」;而 Qwen3.7 Max 要回答的问题是:谁能更便宜、更持久、更稳定地把活干完?
Qwen3.7 Max 性价比碾压:1.3美元 vs 12美元
真正让人倒吸一口凉气的,是 Qwen3.7 Max 在成本控制上展现出的碾压级优势。
在一个长周期的智能体编程任务中,研究者让模型连续10轮迭代改进一个机器人程序,结果如下:
| 模型 | 性能提升 | 花费 |
|---|---|---|
| Qwen3.7 Max | 56% | 约1.30美元 |
| Claude Opus 4 | 28% | 约12美元 |
| GPT-5 | 7% | 未公开(预计更高) |
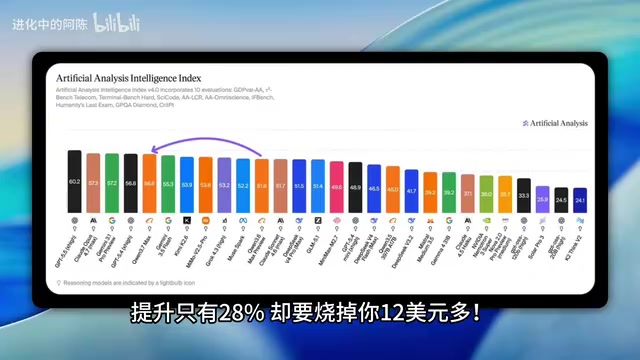
56%的提升只花了1.3美元,而 Claude Opus 4 花了近10倍的价格却只拿到一半的提升幅度,GPT-5更是仅有7%的改进。这不是简单的「便宜一点」,而是数量级上的成本差距。
大模型成本结构与Token经济学:大模型的计费单位是Token(词元),中文约1.5个汉字对应1个Token,英文约4个字符对应1个Token。在Agent场景中,每一轮工具调用都会产生大量的输入输出Token消耗——模型需要读取历史对话、工具返回结果、系统提示词等,导致上下文长度随任务推进呈指数级增长。以Claude Opus 4为例,其定价约为输入15美元/百万Token、输出75美元/百万Token,而Qwen3.7 Max的定价则大幅低于这一水平。在连续100轮迭代的真实工作流中,Token消耗量可能达到数百万,模型定价的差异会被成倍放大,最终形成数量级的成本鸿沟。
为什么成本如此重要?因为在真实的商业场景中,一个AI智能体不是跑一轮就结束的。当你把AI接入公司工作流,一个任务可能需要跑100轮、1000轮。模型再聪明,如果每跑一轮都在烧钱,普通团队早就破产了。成本,就是智能体落地的生死线。
35小时连续执行:AI智能体的耐力才是硬实力
除了便宜,Qwen3.7 Max 的另一个杀手锏是超长续航能力。
官方实测数据显示,它可以支撑长达35个小时的自主执行,连续调用1200次工具,不会干两步就失忆,也不会跑到一半就开始胡说八道。这意味着当你下班睡觉的时候,这个几毛钱成本的「数字员工」还在帮你修bug、跑测试、优化代码。
长上下文注意力衰减问题:「注意力衰减」是当前Transformer架构大模型的固有挑战。研究表明,模型对位于上下文中间位置的信息遗忘率最高,这一现象被称为「Lost in the Middle」效应。对于需要连续执行数十小时的Agent任务,这是致命弱点:前期设定的目标、约束条件和已完成的工作状态可能在数百轮对话后被「遗忘」,导致模型开始重复劳动甚至产生幻觉。Qwen3.7 Max声称能稳定支撑35小时、1200次工具调用,意味着其在长程注意力保持和上下文压缩技术上做了针对性优化,这对Agent场景的实用价值远超单纯的Benchmark分数。
这种耐力在当前大模型中是相当突出的。很多模型在长上下文任务中会出现「注意力衰减」——前面的指令逐渐被遗忘,输出质量急剧下降。Qwen3.7 Max 显然在这方面做了针对性优化,使其更适合作为长时间运行的自动化工作节点。
前端开发能力:不止写代码,还懂交互逻辑
Qwen3.7 Max 在前端开发领域的表现同样令人印象深刻。它不仅能生成网页原型,甚至能用代码手捏出一个带底部菜单、计算器、画图板等功能的完整桌面系统界面。

更值得关注的是它对物理逻辑和交互反馈的理解能力。在一个养鱼模拟的演示中,它能精确控制每条鱼的运动数据和位置,实现食物投放后鱼群聚集进食的自然交互效果,配合UI控件和实时渲染,呈现出相当专业的设计水准。
这说明 Qwen3.7 Max 不是在机械地拼凑代码片段,而是在尝试理解真实世界的空间关系和交互反馈逻辑,能够处理长流程的前端设计方案并保持视觉质量的一致性。
三个短板不容忽视:Qwen3.7 Max 的硬伤在哪
当然,Qwen3.7 Max 目前也有不可回避的硬伤:
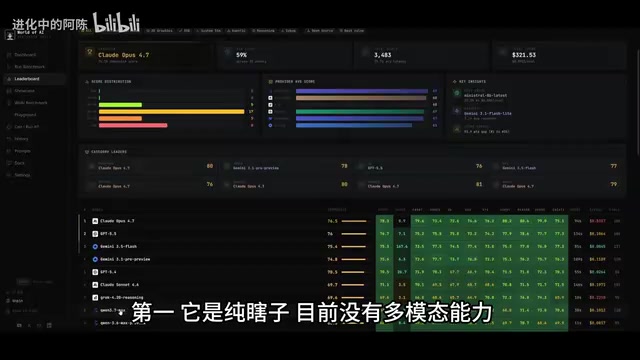
第一,没有多模态能力。 目前它是个「瞎子」,处理不了图片和视频。在多模态成为主流趋势的当下,这是一个显著的功能缺失。
多模态能力缺失的行业背景:多模态(Multimodal)能力指大模型同时处理文本、图像、音频、视频等多种数据类型的能力。GPT-4V、Claude 3系列、Gemini 1.5 Pro均已实现图文混合输入。在实际开发场景中,多模态能力的缺失意味着:无法通过截图描述UI需求、无法分析设计稿进行还原、无法处理包含图表的技术文档。阿里的Qwen-VL系列已具备多模态能力,Qwen3.7 Max作为专注Agent性能的版本暂时放弃多模态,是一种「专精换性能」的取舍策略,但随着多模态成为行业标配,这一缺口预计将在后续版本中补齐。
第二,审美偶尔翻车。 虽然代码能力强,但生成的网页设计有时候会「土掉渣」,视觉审美不够稳定。
第三,极度依赖提示词质量。 你给一句模糊的废话,它就糊弄你;你给细致的规则和交互逻辑,它就是顶级的工程助手。这意味着使用者的 prompt engineering 能力直接决定了输出质量的上限。
提示词工程(Prompt Engineering)的本质:提示词工程是指通过精心设计输入指令来最大化大模型输出质量的技术实践,包括:角色设定(System Prompt)、少样本示例(Few-shot Learning)、思维链引导(Chain-of-Thought)、约束条件声明和输出格式规范等。在Agent场景中,一个好的System Prompt需要明确定义任务边界、工具使用规则、错误处理策略和输出标准。研究表明,同一个模型在不同提示词下的性能差异可高达30%-50%。这也解释了为什么Qwen3.7 Max对提示词质量高度敏感:模型能力越强,提示词对其「上限释放」的影响就越显著。
简单来说,别把它当神笔马良,把它当成一个听话、便宜、能反复返工的苦力——定位对了,它的价值才能最大化。
大模型竞争进入「耐力赛」阶段
Qwen3.7 Max 的出现,标志着大模型竞争正在进入一个新阶段。
过去两年,行业的焦点是「谁更聪明」——比 Benchmark 分数、比推理能力、比知识广度。但当头部模型的智力水平逐渐趋同,真正决定商业价值的因素变成了耐力、价格和执行稳定性。
「帮我搭个demo」「写个自动化脚本」这类需求,正在被彻底重新定价。会聊天的AI当然有用,但真正能重构商业护城河的,是那种便宜、耐跑、能把任务死磕到底的AI工人。
阿里在这条路线上的押注逻辑很清晰:一旦廉价高并发的智能体路线跑通,大模型之争的游戏规则将被彻底改写。对于国内开发者和中小企业来说,Qwen3.7 Max 可能是目前性价比最高的AI生产力工具选择之一。
核心要点
- 千问 3.7 Max定位智能体赛道,支持35小时连续自主执行、1200次工具调用,具备超强续航能力
- 在智能体编程任务中,千问 3.7 Max以1.3美元成本实现56%性能提升,而Claude Opus 4花费12美元仅提升28%,性价比碾压级领先
- 前端开发能力突出,能理解物理逻辑和交互反馈,生成包含完整功能的桌面系统界面
- 目前存在三大硬伤:无多模态能力、审美不稳定、高度依赖提示词质量
- 大模型竞争正从「比智商」转向「比耐力、比价格、比执行稳定性」的新阶段
相关推荐
 产品体验
产品体验Qoder vs Cursor实测对比:同样20美金谁更强?
实测对比Qoder和Cursor两款AI IDE,从Agent自主修复能力、人工沟通次数、架构决策等维度评测。Qoder仅需2次沟通完成任务,Cursor需8次。详细分析两者差异,帮你选择最适合的AI编程工具。
 产品体验
产品体验Cursor云Agent演示:打通软件开发全链路瓶颈
深度解析Cursor云Agent最新Demo,展示如何通过云端虚拟机、自动测试产物和全链路控制平面,系统性消除软件开发生命周期中的人类瓶颈,让Agent自主运行、人按需介入。
 产品体验
产品体验Cursor 3.0深度解析:多Agent并行、Design Mode与Best-of-N模型对比
Cursor 3.0正式发布,从AI辅助编程工具进化为Agent舰队指挥中心。本文详解多智能体并行、Design Mode可视化编辑、Best-of-N多模型择优等核心功能,解读AI编程新范式。