Qwen3.6 27B三大邪修量化模型实测:代码暴增15.8PP、40B蒸馏、16GB适配
三个基于Qwen3.6 27B的非常规量化模型在代码、写作和适配方面各有突破
文章介绍了三个基于通义千问Qwen3.6 27B的"邪修"量化模型:OmniMerge V4通过多模型权重融合将MBPP代码测试成绩提升15.8个百分点,速度快且支持100K上下文;40B OPUS蒸馏版将27B参数扩展至40B,注入Claude 4.6 OPUS推理蒸馏并去除安全审查,支持角色扮演和双语优化。这些模型通过模型融合、参数扩展、特化量化等非常规手段实现了显著的能力增强。
前言
通义千问Qwen3.6 27B稠密模型发布后,社区围绕它的二次创作层出不穷。今天介绍三个基于27B的"邪修"量化模型——它们通过模型融合、参数扩展、特化量化等非常规手段,在代码能力、创意写作、小显存适配等方面各有突破。虽然路子"野"了点,但实测效果确实管用。
OmniMerge V4:代码能力暴增15.8个百分点
模型概述
OmniMerge V4是一个融合模型,由三到四个27B模型通过权重混合"手搓"而成。它的核心卖点是代码能力的大幅增强,并且修复了Qwen3.6 27B在推理标签方面的一个脆弱性问题。
模型融合技术背景:模型融合(Model Merging)是近年来开源社区兴起的一种无需额外训练的模型增强技术。其核心原理是将多个独立训练模型的权重按照特定算法进行混合,常见方法包括SLERP(球面线性插值)、TIES-Merging(剪枝冲突权重后合并)和DARE(随机丢弃后缩放)等。这些方法的理论基础在于:不同模型在参数空间中各自占据不同的"能力区域",通过权重混合可以在同一模型中叠加多种能力。与传统微调相比,融合操作无需GPU算力和训练数据,普通研究者用CPU即可完成,极大降低了模型定制的门槛。
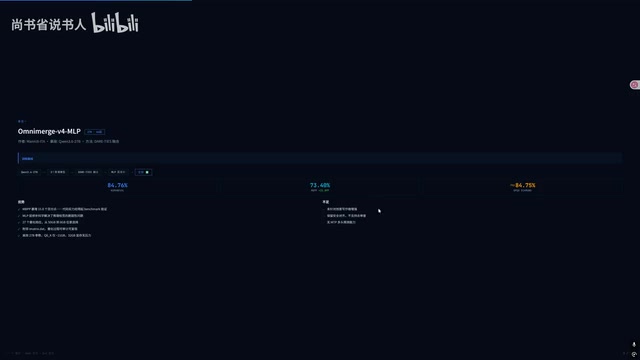
作者使用业界标准的MBPP(Mostly Basic Python Programming)基准进行了测评——这个测试连GPT-4.5、Claude和Gemini等顶尖模型都会跑,具有很高的参考价值。结果显示:
- MBPP代码测试:原版Q6K量化的成绩为56.2%,OmniMerge V4达到73.4%,提升了整整15.8个百分点
- HumanEval测试:84.76,与Q6K原版持平
- JPQA Diamond测试:84.75,表现同样稳健
MBPP与HumanEval基准测试解析:MBPP(Mostly Basic Python Programming)和HumanEval是评估大语言模型代码能力的两大主流基准。MBPP由Google Research发布,包含约500道Python编程题,覆盖字符串操作、数学计算、数据结构等基础场景,以pass@1(一次生成即通过单元测试)为核心指标。HumanEval则由OpenAI发布,包含164道手工编写的编程题,同样采用pass@1评估。两者的区别在于:MBPP更侧重实用性和多样性,HumanEval题目难度更均匀但数量较少。值得注意的是,MBPP的56%→73%提升幅度在业界属于显著跃升,通常需要专项代码数据微调才能实现,融合模型能达到此效果颇为罕见。
实测体验
实际使用中,这个模型给人最大的惊喜是速度极快。Q5版本在5090上运行时,无论是模型加载还是Token生成速度,都明显快于普通Q4量化版本。更惊人的是,Q5版本可以跑到100K的上下文长度,而普通Q4量化版可能只有几十K。
上下文长度与显存的关系:大语言模型的上下文长度(Context Length)与显存消耗之间存在非线性关系,核心瓶颈在于KV Cache(键值缓存)。在Transformer架构中,每个Token的注意力计算需要缓存所有历史Token的Key和Value向量,其显存占用与序列长度成正比。以27B模型为例,在Q5量化下模型权重约占18-20GB,但当上下文扩展到100K Token时,KV Cache可能额外消耗8-15GB显存,这正是为何100K上下文需要更大显存的原因。OmniMerge V4能在Q5量化下支持100K上下文,说明其可能采用了GQA(分组查询注意力)或滑动窗口注意力等KV Cache压缩技术,或者通过量化KV Cache本身来降低内存占用。
模型体积也控制得很好,Q5版本不到20GB。作者提供了多达27个量化档位,从12GB到大显存基本全覆盖。代码生成实测中,让它写一个打砖块游戏,桥梁结构、道具系统、可玩性都做得不错,代码能力确实名副其实。
不足之处
- 保留了安全对齐,存在话题限制
- 不支持MTP(多Token预测)投机解码
- 创意写作方面相比原版没有明显提升
40B OPUS蒸馏版:参数扩展的邪修大冒险
模型概述
这个模型堪称"纯邪修"——作者将27B模型扩展到了40B参数量,并注入了大量"料":
- 使用Claude 4.6 OPUS进行推理蒸馏,提升推理和代码能力
- 去除安全审查,没有话题限制
- 加入大量性格数据集,支持角色扮演场景
- 中英文双语优化
参数扩展(模型膨胀)技术:将27B模型"扩展"到40B并非凭空增加参数,而是通过"深度扩展"(Depth Upscaling)或"宽度扩展"技术实现。深度扩展的典型做法是复制原模型的部分Transformer层并插入其中,再通过少量微调让新增层学会有效工作——韩国SOLAR团队于2023年提出的"深度向上扩展"(Depth Up-Scaling)正是此类方法的代表,其10.7B模型即由两个7B模型层叠而成。宽度扩展则是增加注意力头数或FFN维度。这类扩展后的模型在初始阶段往往存在"能力断层",需要蒸馏或微调来弥合新旧层之间的表示差异。扩展后参数量增加但实际能力提升幅度通常小于等比例从头训练的同参数模型,因此被称为"邪修"路线。
知识蒸馏技术原理:知识蒸馏(Knowledge Distillation)最初由Hinton等人于2015年提出,核心思想是让小模型(学生)学习大模型(教师)的输出分布,而非直接学习硬标签。在大语言模型时代,"推理蒸馏
相关推荐
 产品体验
产品体验Qoder vs Cursor实测对比:同样20美金谁更强?
实测对比Qoder和Cursor两款AI IDE,从Agent自主修复能力、人工沟通次数、架构决策等维度评测。Qoder仅需2次沟通完成任务,Cursor需8次。详细分析两者差异,帮你选择最适合的AI编程工具。
 产品体验
产品体验Cursor云Agent演示:打通软件开发全链路瓶颈
深度解析Cursor云Agent最新Demo,展示如何通过云端虚拟机、自动测试产物和全链路控制平面,系统性消除软件开发生命周期中的人类瓶颈,让Agent自主运行、人按需介入。
 产品体验
产品体验Cursor 3.0深度解析:多Agent并行、Design Mode与Best-of-N模型对比
Cursor 3.0正式发布,从AI辅助编程工具进化为Agent舰队指挥中心。本文详解多智能体并行、Design Mode可视化编辑、Best-of-N多模型择优等核心功能,解读AI编程新范式。