Qwen3.6量化版本地部署实测:NVFP4、APEX、Q4、Q6哪个最值得选
Qwen3.6各量化版本全面跑分,NVFP4表现最强
UP主对Qwen3.6系列7-8个量化模型进行了8大维度155项测试,结论是27B NVFP4表现最强(需50系显卡),其次是35B MOE APEX量化和35B NVFP4,OPUS蒸馏版暂不推荐。测试还揭示了蒸馏不一定提升性能、所有模型都存在确认偏误等有趣发现。
为什么要做这次Qwen3.6量化测评
Qwen3.6发布后,想在本地跑起来的用户越来越多。但面对27B、35B MOE等不同规格,以及NVFP4、APEX、Q4、Q6等一堆量化方案,到底该选哪个?
为了搞清楚这个问题,UP主花了好几天搭建BenchLocal测试环境,对Qwen3.6系列的7-8个模型做了全面跑分。每项成绩至少复测两遍,部分甚至三四遍,尽量保证结果靠谱。
本文会详细拆解各量化版本在工具调用、命令行操作、Bug修复、指令遵循、数学推理等8大维度的实际表现,帮你做出最合适的选择。
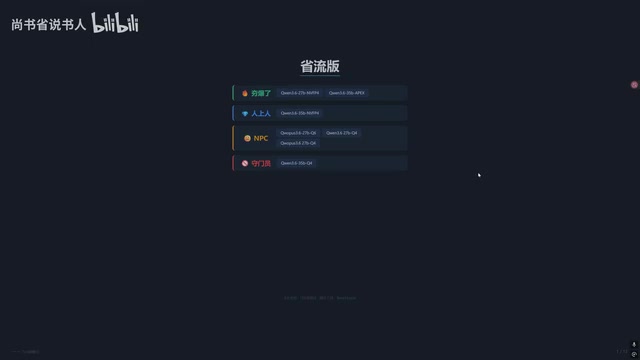
省流结论:从强到弱的推荐排序
先放结论,赶时间的朋友可以直接参考:
- Qwen3.6 27B NVFP4 — 最强推荐(需50系显卡)
- Qwen3.6 35B MOE APEX量化 — 次优选择(Q4体量,Q8体验)
- Qwen3.6 35B NVFP4 — 紧随其后
- OPUS蒸馏版Q6/Q4 — 暂不推荐,等正式版
- 原版27B Q4 / 原版35B MOE — 保底选择
这里要特别提一下之前广受好评的OPUS 4.6蒸馏版(来自Jacker社区大神)。这个版本在3.5时代表现很出色,但3.6的V1预览版测试成绩并不理想——即使Q6精度也比不上NVFP4,部分项目甚至不如原版。建议等正式版出来再考虑。
测试方法与评分体系
测试工具用的是GitHub上的BenchLocal。它的设计思路是从日常使用场景出发,而不是去探究模型的理论极限。
BenchLocal的设计哲学:BenchLocal是一个面向本地部署场景的LLM基准测试框架,其设计哲学与学术界常用的MMLU、HumanEval等基准有所不同。学术基准通常测试模型的知识边界和理论能力上限,而BenchLocal更关注模型在真实工作流中的可靠性——例如工具调用是否稳定、指令遵循是否严格、命令行操作是否实用。这种"以用户场景为中心"的评测思路,使其结论对本地部署用户更具参考价值,但也意味着其分数不能直接与学术排行榜横向比较。
举个例子:问天气时,模型是否正确调用了工具、是否根据工具返回的结果给出准确回答,而不是自己瞎编一个答案。
一共测了8个大类、155个测试项,包括:
- ToolCore(工具调用,15项)
- CLI40(命令行操作,40项)
- BugFind(Bug识别修复,15项)
- 指令遵循、Hermes Agent、结构化输出、数学推理、数据提取等
评分规则也很直观:满足所有条件得满分,部分解决得一半分,全部不通过则零分,满分100。
各量化版本8大维度详细测试分析
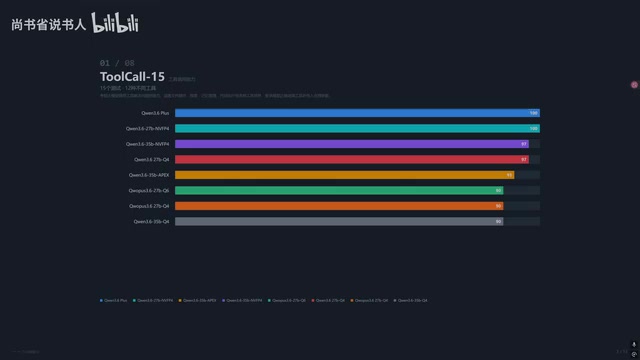
工具调用(ToolCore):NVFP4满分登顶
这项测试考验模型能否正确调用12种不同工具来完成任务,涵盖文件操作、搜索管理等场景。
- Qwen3.6 27B NVFP4:满分100
- Qwen3.6 35B NVFP4:97分
- 原版27B Q4:97分(没做任何量化蒸馏,反而表现不错)
- OPUS蒸馏版Q6:仅90分
一个值得注意的现象:原版27B Q4在工具调用上拿到97分,说明蒸馏并不总能提升性能,有时反而会导致某些能力退化。
关于知识蒸馏与量化的本质区别:模型量化(Quantization)是将模型权重从高精度浮点数(如FP16/BF16)压缩为低位宽整数或浮点数的过程,目的是减少显存占用和加速推理,原模型的权重结构得以保留。知识蒸馏(Knowledge Distillation)则是用大模型(教师模型)的输出来指导小模型(学生模型)重新训练,使小模型学习大模型的"软标签"分布,模型参数会发生实质性改变。两者目标不同,效果也因任务而异:蒸馏可能在某些维度提升表现,却在另一些维度引入退化,这正是本次测试中蒸馏版表现不稳定的根本原因。
命令行操作(CLI40):全场最难的一关
这是8项测试中难度最高的,共40个命令行测试场景。模型很容易耗尽上下文窗口,跑的时间也特别长。
即使是Qwen3.6 Plus(API版本)也只拿了76分,本地部署的模型基本在六七十分之间徘徊。具体来看:
- OPUS蒸馏版Q4和Q6反而表现不错,两者仅差1分
- APEX量化和35B NVFP4得分相同,再次印证了"APEX是Q4体量Q8体验"的说法
- 27B NVFP4紧随其后,仅差1分
- 原版7B和原版MOE 35B垫底
Bug识别修复(BugFind):所有模型都栽在陷阱上
15个场景中,第3和第10个场景是陷阱——代码本身完全正确,但题目暗示存在Bug。测试结果有点遗憾:所有模型无一通过陷阱考验,全部"无中生有"地修改了正确代码。包括DeepSeek和小米MIMO也同样在这两个陷阱上翻车。
这一现象揭示了当前LLM的一个系统性弱点:模型倾向于迎合提示词中的预设前提(即"确认偏误"),而非独立验证代码的正确性。这与模型训练时大量使用"找Bug并修复"类数据有关,导致模型形成了"题目问Bug就一定有Bug"的隐性假设。
表现最好的是APEX量化的35B MOE,其次是NVFP4。90分以上的仅有3个模型。
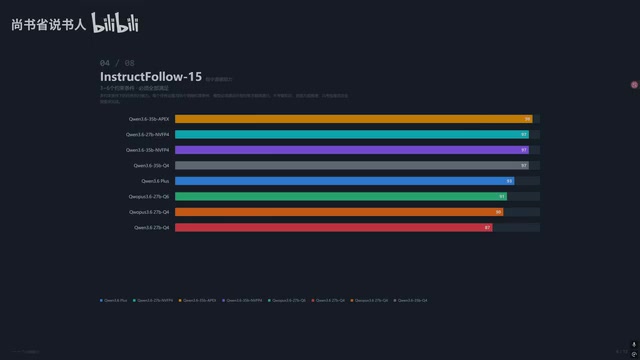
指令遵循:考验模型"听不听话"
这项测试不看推理能力、创造力或知识储备,只看模型能否严格按照3-6个约束条件输出结果。
有意思的是,Qwen3.6 Plus在这项上反而只跑到中游——**性能太强反而"想太多
相关推荐
 产品体验
产品体验Qoder vs Cursor实测对比:同样20美金谁更强?
实测对比Qoder和Cursor两款AI IDE,从Agent自主修复能力、人工沟通次数、架构决策等维度评测。Qoder仅需2次沟通完成任务,Cursor需8次。详细分析两者差异,帮你选择最适合的AI编程工具。
 产品体验
产品体验Cursor云Agent演示:打通软件开发全链路瓶颈
深度解析Cursor云Agent最新Demo,展示如何通过云端虚拟机、自动测试产物和全链路控制平面,系统性消除软件开发生命周期中的人类瓶颈,让Agent自主运行、人按需介入。
 产品体验
产品体验Cursor 3.0深度解析:多Agent并行、Design Mode与Best-of-N模型对比
Cursor 3.0正式发布,从AI辅助编程工具进化为Agent舰队指挥中心。本文详解多智能体并行、Design Mode可视化编辑、Best-of-N多模型择优等核心功能,解读AI编程新范式。