QwenCoder本地部署实测:能否替代付费AI编程助手?

本地部署QwenCoder 80B编程模型测试:简单任务胜任,复杂任务仍不及付费云端模型。
一位20年经验的开发者在消费级硬件(RTX 4060)上本地部署QwenCoder 80B模型,通过LM Studio和局域网分布式架构进行编程能力测试。结果显示,该模型在简单编程任务上表现良好且响应迅速,但面对复杂任务(如生成六种排序算法可视化HTML)时失败,陷入上下文窗口退化导致的死循环,不及Gemini 3.1和Qwen 3.5等付费云端模型。
前言:为什么要测试本地编程模型?
在AI编程工具日益普及的今天,Claude、Gemini、GPT等付费模型虽然强大,但持续的订阅费用和token消耗让不少开发者感到压力。一位拥有20年开发经验的程序员Nick最近对QwenCoder进行了深度测试,试图回答一个关键问题:本地部署的专用编程模型,能在多大程度上替代付费AI编程助手?
此前他测试过Qwen 3.5通用模型,虽然整体表现不错,但在编程任务上表现平平——毕竟编程不是它的主要设计目标。而QwenCoder作为专门为代码生成设计的模型,官方基准测试显示其性能可媲美Claude Sonnet 4.5,同时体积更小,可以在消费级硬件上本地运行。
理解QwenCoder与Qwen通用模型的差异,需要了解AI模型"专业化微调"的核心逻辑。通用模型在预训练阶段使用多样化的互联网文本,代码只是其中一部分;而专用编程模型通常在通用基座之上,使用大规模高质量代码数据集进行继续预训练(Continued Pre-training)和指令微调(Instruction Fine-tuning)。训练数据来源包括GitHub开源代码、编程竞赛题解、技术文档、代码审查记录等。专用编程模型还会针对代码特有的评估指标进行优化,如HumanEval(函数级代码生成)、MBPP(基础编程问题)、SWE-bench(真实GitHub Issue修复)等基准测试。这种专业化训练使模型在理解代码语义、处理多文件上下文、生成符合语言规范的代码方面显著优于通用模型,但代价是在非编程任务上的表现会相应退化。
硬件配置与部署方案
测试硬件规格
本次测试使用的是一台Linux桌面主机,核心配置如下:
- CPU:AMD Ryzen 7
- 内存:128GB RAM
- 显卡:GeForce RTX 4060(关键是VRAM容量)
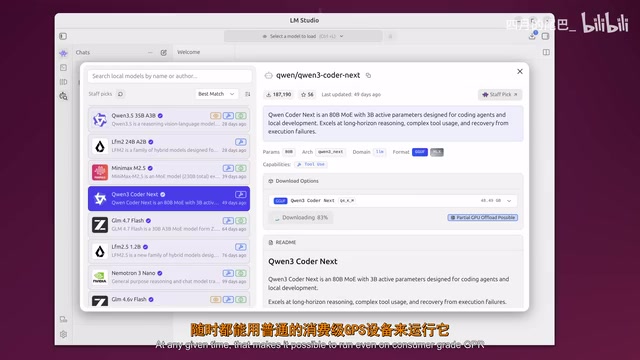
QwenCoder 80B参数版本(约50GB大小)之所以能在消费级GPU上运行,是因为它采用了混合专家架构(MoE,Mixture of Experts)。与传统密集型(Dense)模型在推理时需要激活全部参数不同,MoE架构引入了"路由机制"——模型由多个"专家"子网络组成,每次推理时路由器只选择其中少数几个专家(通常是2-8个)处理当前输入。这意味着一个标称800亿参数的MoE模型,实际每次推理时可能只激活约200亿参数,VRAM占用大幅降低。MoE架构最早由Google在2017年提出,后被Mistral的Mixtral系列、阿里的Qwen系列等广泛采用,代表了"用更少计算资源实现更大模型容量"的技术路线。此外,底层推理引擎llama.cpp支持的GGUF量化格式(如Q4_K_M)通过将权重精度从32位浮点压缩到4位整数,进一步将模型体积压缩数倍,通常只带来约1-5%的性能损失,是本地部署大模型的另一关键使能技术。
LM Studio部署与网络架构
Nick使用LM Studio作为本地模型运行工具(另一个常用选择是Ollama)。两者都是目前最主流的本地大模型运行框架,但定位略有差异:Ollama更偏向命令行和开发者工具链,支持Docker部署,API接口完全兼容OpenAI规范,适合集成到自动化脚本和CI/CD流程中;LM Studio则提供了图形化界面,内置模型下载市场(直接对接Hugging Face),并支持一键启动本地API服务器,对非技术背景用户更友好。两者底层均依赖llama.cpp作为推理引擎。
更巧妙的是,Nick采用了一种分布式工作方式:
- 模型运行在Linux桌面主机上
- 通过LM Studio内置的API服务暴露到局域网
- 日常使用MacBook通过网络连接到模型
- 在Zed编辑器中配置LLM providers,填入局域网地址和端口即可
这种架构的技术实现依赖于OpenAI兼容API规范——LM Studio、Ollama等工具暴露的HTTP接口与OpenAI API格式完全一致,这意味着任何支持自定义API端点的AI客户端(Zed、Continue.dev、Cursor等)都可以无缝切换到本地模型,无需修改代码。从安全角度看,局域网部署意味着代码和数据不会离开本地网络,对处理商业机密或敏感代码的开发者尤为重要。从成本角度看,一台RTX 4060主机的电费(满载约120W)远低于等效的云端API调用费用。这种架构还可以进一步扩展:通过Tailscale等零信任网络工具,甚至可以在外网安全访问家中的AI服务器。
QwenCoder实际编程能力测试
简单任务:轻松通过
首先是基础的Python函数编写测试,用于验证多机协作的setup是否正常。QwenCoder的响应速度令人印象深刻——考虑到模型体积约50GB,生成速度相当快,完全可以满足日常开发的交互需求。
复杂任务:力不从心
接下来是真正的挑战——要求模型生成一个HTML文件,可视化展示六种排序算法。这是Nick此前用来测试Gemini 3.1和Qwen 3.5的同一道题目。
结果如何?
- Gemini 3.1(付费云端):成功完成
- Qwen 3.5 400B(云端大版本):成功完成
- QwenCoder 80B(本地):失败
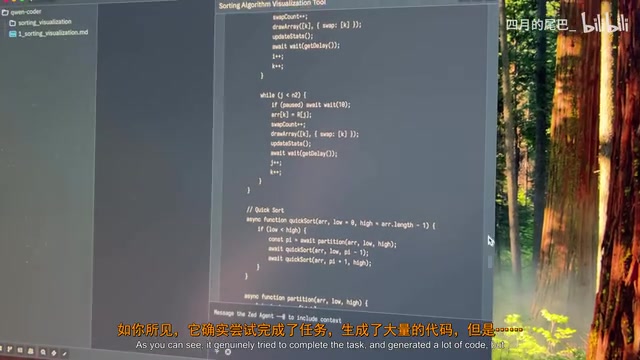
在长时间的生成过程中,模型多次发现自己的错误并尝试重写,最终陷入了死循环。这一现象在业界被称为"上下文窗口退化"——当生成内容超过模型有效处理长度时,模型对早期生成内容的"记忆"开始模糊,导致前后逻辑不一致,进而触发反复修正。虽然它确实生成了大量代码,展现出了"努力
相关推荐
 产品体验
产品体验Qoder vs Cursor实测对比:同样20美金谁更强?
实测对比Qoder和Cursor两款AI IDE,从Agent自主修复能力、人工沟通次数、架构决策等维度评测。Qoder仅需2次沟通完成任务,Cursor需8次。详细分析两者差异,帮你选择最适合的AI编程工具。
 产品体验
产品体验Cursor云Agent演示:打通软件开发全链路瓶颈
深度解析Cursor云Agent最新Demo,展示如何通过云端虚拟机、自动测试产物和全链路控制平面,系统性消除软件开发生命周期中的人类瓶颈,让Agent自主运行、人按需介入。
 产品体验
产品体验Cursor 3.0深度解析:多Agent并行、Design Mode与Best-of-N模型对比
Cursor 3.0正式发布,从AI辅助编程工具进化为Agent舰队指挥中心。本文详解多智能体并行、Design Mode可视化编辑、Best-of-N多模型择优等核心功能,解读AI编程新范式。