RAG技术全链路解析:核心原理、企业落地与学习路径

RAG技术已成为连接企业数据与大模型的关键桥梁和AI应用刚需
RAG(检索增强生成)通过在大模型生成回答前检索外部知识库,解决了模型知识截止和幻觉两大缺陷,已成为企业AI应用落地的核心技术。当前RAG在医药、家居、航空等行业已有成熟案例,但企业落地常因缺乏系统性理解和迭代优化能力而失败。系统学习RAG需覆盖向量数据库、检索策略、Agent集成、知识图谱融合等技术栈,并注重动手实践。
为什么RAG技术已成为AI应用的刚需?
从ChatGPT问世至今不过两年,大模型领域已经发生了翻天覆地的变化。OpenAI的O1、O3,以及国产之光DeepSeek R1,这些性能强劲、推理高效、价格低廉的模型层出不穷,为AI应用的爆发提供了坚实基础。
当前,国内外大量企业已经或正在准备接入AI应用来赋能业务,企业对AI的需求正从通用型急剧转向场景型,催生出大量高度垂直的AI应用。能够建立起"场景→痛点→AI能力"快速匹配机制的企业,将在这波浪潮中获得压倒性优势。
在这个背景下,AI应用开发的两大基石——智能体(Agent)和知识库——成为核心竞争力。而RAG(检索增强生成)正是连接企业内部数据与大语言模型的关键桥梁。

什么是RAG?一个直观的类比
RAG(Retrieval-Augmented Generation,检索增强生成)由Meta AI研究团队于2020年在论文《Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks》中正式提出。其核心思想是将信息检索系统与生成式语言模型结合:在模型生成回答之前,先从外部知识库中检索相关文档片段,再将这些片段作为上下文(Context)一并输入模型,从而引导模型生成更准确、有据可查的回答。这一架构本质上弥补了纯参数化语言模型的两大先天缺陷——知识截止日期和幻觉问题。
理解RAG最好的方式是拿人类自身做类比:
- 大语言模型 = 人类的大脑中枢
- Agent = 人类的手,能够调用各种工具完成任务
- RAG = 人类依赖的外部知识
人类大脑的长期记忆容量有限,不可能记住所有知识,遇到问题时仍然需要查阅资料。同理,大语言模型受限于训练数据,对于未见过的知识也需要借助外部信息源。RAG就是大语言模型获取外部知识的核心机制。
RAG的三大核心价值
- 扩展认知边界:为大模型提供其训练数据之外的知识,使其能够回答特定领域的专业问题
- 减少幻觉:大语言模型的"幻觉"(Hallucination)是指模型生成看似合理但实际上不准确甚至完全错误的内容。这一现象源于语言模型的本质——它是基于统计概率的文本预测系统,优化目标是生成流畅连贯的文本,而非保证事实准确性。RAG通过将真实文档片段注入上下文,为模型提供可依赖的事实锚点,从机制上约束了模型的发散空间,是目前工业界减少幻觉最实用的方案之一。
- 知识实时更新:RAG提供的知识可以持续更新,维持与现实世界信息的同步,无需重新训练模型
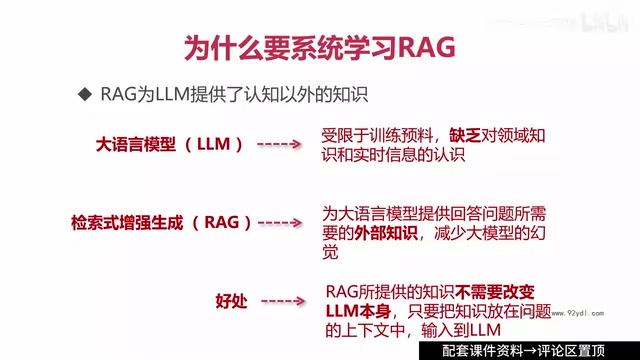
更重要的是,使用RAG不需要改变大语言模型本身——只需将检索到的知识放入问题的上下文中,输入给大模型即可。这种"即插即用"的特性大大降低了企业落地AI应用的门槛。
RAG在产业中的落地现状
行业应用案例
RAG正在与千行百业进行深度融合。在世界人工智能大会上,多个分享主题都涉及RAG的实际应用:
- 医药行业:云南白药的生产知识AI助理、白药RPS智能问答
- 家居行业:金牌家居开发的AI助理"小金"
- 航空行业:深圳航空构建的内部AI知识库——深航AI销售帮手
开源生态蓬勃发展
在开源领域,RAG相关项目不断涌现。除了LangChain和LlamaIndex等AI应用开发框架集成了RAG功能外,还有大量独立的RAG开源项目值得关注:RAGFlow、QAnything、FastGPT、MaxKB、Dify等,为开发者提供了丰富的选择。
人才市场需求旺盛
RAG技术在人才市场上受到各行各业的青睐。除了专门的RAG工程师岗位外,产品经理、后端工程师、项目经理、架构师等岗位也越来越多地要求具备RAG相关知识。行业分布上,除计算机服务领域外,新能源、媒体、证券等传统行业同样需要RAG来赋能业务。
企业对RAG人才的典型要求包括:检索优化、重排算法、全链路开发等系统性能力。
企业RAG落地的常见困境
构建一个高质量的RAG系统并不简单。在实际企业案例中,一个常见的场景是:团队利用开源RAG软件加上本地资料构建企业知识库,试用时却收到"回答效果不好""AI也就这样"的反馈,最终草草弃之不用,浪费人力物力。
问题的根源在于:RAG系统是一个典型的需要动态迭代的AI项目。它不仅需要开发者深刻理解RAG的体系结构、知识和能力边界,还需要掌握RAG的开发与迭代过程。只有这样,才能因地制宜地根据企业实际问题,采取RAG体系框架中的已有策略或研发新策略进行优化。
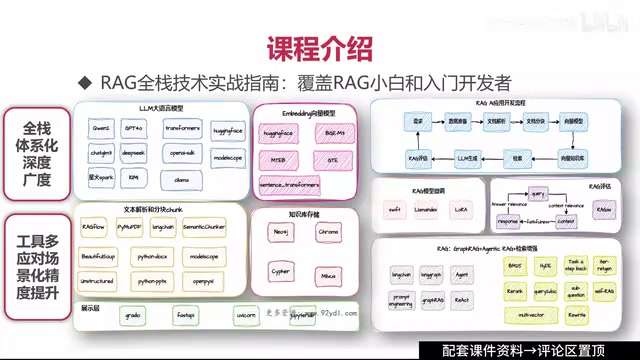
系统学习RAG的路径规划
学习中的三大挑战
- 技术面繁杂:RAG涉及的技术栈广泛,缺少结构化学习资料,容易迷失方向
- 实践资源不足:市面上讲原理的多,结合实际代码实现的少
- 精度提升困难:面对企业复杂数据和用户问题多样性,提升RAG精度是巨大挑战
推荐的学习路线
一个体系化的RAG学习路径应当遵循循序渐进的原则:
- 基础阶段:从RAG的三大组件(检索、增强、生成)入手,构建基本流程
- 优化阶段:采取迭代优化方式,验证和提升RAG系统性能
- 扩展阶段:将Agent和知识图谱引入RAG,丰富能力矩阵
- 进阶阶段:结合模型微调进一步提升RAG能力

关键技术栈一览
系统学习RAG需要覆盖以下核心技术领域:
-
向量数据库选型:向量数据库是RAG系统的核心存储组件。与传统关系型数据库按结构化字段检索不同,向量数据库通过高维向量的相似度计算(如余弦相似度、欧氏距离)实现语义级别的模糊匹配。文本经过Embedding模型编码后转化为数百至数千维的浮点向量,向量数据库利用ANN(近似最近邻)算法(如HNSW、IVF)在毫秒级完成亿级向量的检索。主流选项包括开源的Milvus、Qdrant、Weaviate,以及云服务Pinecone等,各自在性能、可扩展性和易用性上有所侧重。
-
文档解析与分块策略:针对PDF、Word、网页等不同类型的企业文档选择合适的处理方式。分块(Chunking)策略的优劣直接影响检索质量,常见方案包括固定长度分块、按语义段落分块以及基于文档结构的层级分块。
-
Embedding模型选择:根据业务场景选择合适的向量化模型。中文场景下BGE、M3E等本土化模型往往优于通用英文模型,多语言场景则可考虑multilingual-e5等跨语言模型。
-
检索策略优化:单纯的向量语义检索并非万能,对于包含专有名词、产品编号、精确数字等信息的查询,传统的BM25关键词检索往往更为精准。混合检索(Hybrid Search)将向量检索与关键词检索的结果通过RRF(倒数排名融合)等算法合并,兼顾语义理解与精确匹配。在此基础上,重排序(Rerank)模型(如Cohere Rerank、BGE-Reranker)对召回的候选文档进行二次精排,利用Cross-Encoder架构对查询与文档的相关性进行更精细的评分,显著提升最终送入LLM的上下文质量,是RAG精度优化的关键一环。
-
Agent集成:将RAG与智能体结合,实现更复杂的业务逻辑。Agent可以根据问题类型动态决策是否触发检索、检索哪个知识库,甚至编排多步检索流程。
-
知识图谱融合:知识图谱(Knowledge Graph)以"实体-关系-实体"三元组的形式组织结构化知识,擅长表达复杂的多跳推理关系。将知识图谱与RAG结合(即GraphRAG,由微软研究院于2024年提出并开源)可以弥补纯向量检索在处理跨文档关联推理时的不足。例如,当用户询问涉及多个实体之间复杂关联的问题时,图谱能够沿关系边进行多跳遍历,特别适合供应链管理、医药研发和法律合规等存在大量实体关联的企业场景。
写在最后:行动比观望更重要
RAG不仅是一项技术,更是AI应用开发最重要的落地方向之一。对于开发者而言,系统掌握RAG意味着能够将大语言模型与企业实际业务深度结合,打造真正有价值的AI应用。
值得强调的是,RAG作为AI应用,其开发本身存在很多不确定性,需要根据实际情况选择不同方法来应对。因此,学习RAG不能停留在理论层面,动手实践才是王道。只有在真实项目中不断迭代,才能真正理解每种策略的适用场景和优劣取舍。
在AI大浪潮时代,机会留给有准备的人。与其做犹豫的旁观者,不如积极躬身入局,从构建第一个RAG应用开始。
核心要点
- RAG(检索增强生成)是连接企业内部数据与大语言模型的关键技术,通过提供外部知识减少幻觉、扩展认知边界且支持实时更新
- 2025年企业AI需求从通用型转向场景型,RAG作为AI应用开发两大基石之一,在医药、家居、航空等行业已有成熟落地案例
- 企业RAG落地常见失败原因是缺乏系统性理解和迭代优化能力,RAG是需要动态迭代的AI项目而非一次性部署
- 系统学习RAG应遵循基础→优化→扩展→进阶的路径,覆盖向量库选型、检索策略、Agent集成、知识图谱融合等核心技术栈
- RAG人才需求旺盛,不仅限于专门岗位,产品经理、架构师等角色也越来越需要RAG相关能力
相关推荐
 教程攻略
教程攻略Cursor+Codex双IDE协同:开源项目二开实战方法论
基于实战经验总结的开源项目二次开发完整方法论,详解Cursor+Codex双IDE协同工作流,涵盖二开七环节、MVP验证、AI读源码技巧,帮助开发者三天跑通项目、两周完成业务集成。
 教程攻略
教程攻略Cursor多Agent实战:50分钟搭建Next.js全栈博客
使用Cursor IDE多Agent协作模式,50分钟内从零搭建全栈博客。涵盖Next.js、Clerk认证、Supabase数据库集成,详解4个AI Agent分阶段开发流程与关键避坑经验。
 教程攻略
教程攻略从零搭建AI软件工厂:Cursor工程师的多Agent协作实战经验
Cursor工程师Eric分享AI软件工厂构建实战:从自动化六层级、护栏设计、并行Agent管理到规模化扩展,详解如何用多Agent协作实现7×24小时高效软件开发。