Redis Array数据类型详解:18个新命令与WASM在线实验场
Redis新增Array数据类型,带来18个新命令,支持O(1)随机访问和服务端正则搜索。
Redis创始人antirez提交PR为Redis新增原生Array数据类型,包含18个新命令,提供O(1)随机访问能力,弥补了List链表结构在索引访问上的不足。其中ARGREP命令集成TRE正则库支持服务端近似匹配搜索。Simon Willison用Claude Code构建了基于WebAssembly的浏览器端Playground供开发者零安装体验。该项目展示了AI辅助系统级编程与工具链快速构建两种实践模式。
概述
Redis 创始人 Salvatore Sanfilippo(antirez)近日向 Redis 提交了一个重要的 PR,为 Redis 新增了一种全新的数据类型——Array(数组),一口气带来了 18 个全新命令。话说回来,Simon Willison 用 Claude Code 构建了一个基于 WebAssembly 的浏览器端交互式实验场(Playground),开发者无需安装任何环境就能在线体验这些新命令。
Redis 数据类型演进背景
Redis 自 2009 年发布以来,其核心数据类型经历了多次扩展。最初仅支持 String、List、Set、Sorted Set 和 Hash 五种基础类型,后来陆续加入了 HyperLogLog(2014,用于基数估算)、Bitmap 和 Bitfield(严格来说是 String 类型的位操作扩展)、Geo(2015,基于 Sorted Set 实现的地理空间索引)、Stream(2018,用于消息队列和事件溯源)等。
Redis 的数据模型设计遵循一个核心哲学:每种数据类型都必须提供明确的时间复杂度保证,并针对特定访问模式进行内存效率优化。例如,当 Hash 中的字段数量较少时,Redis 会自动使用 listpack(早期为 ziplist)这种紧凑编码来节省内存,只有当元素数量超过阈值时才切换为真正的哈希表。这种「小数据用紧凑编码,大数据用高效结构」的双层设计贯穿了 Redis 的所有数据类型。
值得注意的是,Redis 在 4.0 版本(2017)引入了模块系统(Modules API),允许第三方通过动态加载的方式扩展自定义数据类型,如 RedisJSON、RedisGraph、RedisTimeSeries 等。但此次 Array 类型是直接加入 Redis 核心代码库的原生类型,这意味着它将获得与 String、List 等同等级别的优化和维护保障,不依赖额外的模块加载。这是 Redis 时隔多年再次在核心层面引入全新的基础数据结构,标志着 Redis 在数据模型丰富度上的又一次重要演进。
Redis Array 数据类型:18 个新命令全面解析
此次 PR 引入了一整套围绕 Array 类型的操作命令,共计 18 个。按功能划分如下:
- 基础操作:
ARSET、ARGET、ARLEN、ARINFO - 批量操作:
ARMGET、ARMSET - 范围操作:
ARGETRANGE、ARDELRANGE - 插入与删除:
ARINSERT、ARDEL - 遍历与搜索:
ARSCAN、ARSEEK、ARNEXT、ARGREP - 其他:
ARCOUNT、AROP、ARRING、ARLASTITEMS
这套命令覆盖了数组数据结构的增删改查、范围操作、遍历和模式匹配等核心场景。
Array 与 List 的底层结构差异
Redis 已有的 List 类型底层采用 quicklist 实现(早期版本使用 ziplist + linkedlist 的混合结构)。quicklist 本质上是一个由多个 listpack(Redis 7.0 之前为 ziplist)节点组成的双向链表。每个 listpack 节点是一块连续内存,内部存储若干个元素;节点之间通过指针链接。Redis 通过 list-max-listpack-size 配置项控制每个节点的最大大小,并可通过 list-compress-depth 对中间节点进行 LZF 压缩以节省内存。
这种设计的核心权衡在于:头尾操作(LPUSH/RPUSH/LPOP/RPOP)是 O(1) 的,但按索引访问元素(LINDEX)的时间复杂度为 O(N),需要从头或尾逐步遍历到目标位置。虽然 quicklist 通过分块减少了遍历步数,但本质上仍是线性查找。
而 Array 类型预期采用连续内存布局的数组结构,支持 O(1) 的随机访问。连续内存布局还带来了一个重要的性能优势:CPU 缓存友好性。现代 CPU 的 L1/L2/L3 缓存以缓存行(通常 64 字节)为单位加载数据,连续内存布局意味着访问一个元素时,相邻元素大概率已经被预取到缓存中,后续访问几乎零延迟。相比之下,链表结构的节点分散在内存各处,每次跳转都可能触发缓存未命中(cache miss),在大数据量下性能差异可达数倍。
两者的时间复杂度对比:
| 操作 | List (quicklist) | Array |
|---|---|---|
| 头尾插入/删除 | O(1) | O(N)(需移动元素) |
| 按索引访问 | O(N) | O(1) |
| 按索引插入 | O(N) | O(N)(需移动元素) |
| 范围查询 | O(S+N) | O(N)(连续内存拷贝) |
这种底层差异决定了两者适用场景的根本不同:List 适合队列/栈等头尾操作场景,Array 适合需要频繁按位置读写的场景。因此,Array 提供了更强大的随机访问和按索引操作能力,为 Redis 的数据模型增添了更灵活的序列化存储选项。
ARGREP:服务端正则搜索命令
在 18 个新命令中,ARGREP 最值得关注。它允许用户在服务端直接对数组中的值执行 grep 操作,支持正则表达式匹配。底层集成了 TRE 正则表达式库,这是一个支持近似匹配(approximate matching)的轻量级正则引擎。
TRE 正则库的技术特性
TRE(Tre Regular Expressions)是由 Ville Laurikari 开发的 POSIX 兼容正则表达式库,其最大特色是支持近似匹配——即允许在指定的编辑距离(插入、删除、替换操作次数)内进行模糊匹配。这与传统正则引擎只支持精确模式匹配有本质区别。例如,搜索模式 "redis" 在允许编辑距离为 1 的情况下,可以匹配到 "rediS"、"redis1"、"redis" 的各种拼写变体,这在处理用户输入的模糊搜索、日志中的近似文本匹配等场景中极具价值。
TRE 使用基于标记化 NFA(tagged NFA)的算法,保证了线性时间复杂度 O(M×N) 的匹配性能(M 为模式长度,N 为文本长度),不会出现某些正则引擎中的灾难性回溯(catastrophic backtracking)问题。灾难性回溯是指当正则表达式包含嵌套量词(如 (a+)+b)时,回溯型引擎(如 PCRE、Java regex)在不匹配的输入上可能产生指数级的时间复杂度,极端情况下一个短短的正则表达式就能让 CPU 卡死数分钟。这种问题曾导致多起生产事故,包括 2019 年 Cloudflare 的全球宕机事件。
在正则引擎的选择谱系中,常见的替代方案包括:PCRE2(功能最丰富,支持反向引用等高级特性,但存在回溯风险)、Google RE2(保证线性时间但不支持近似匹配)、Intel Hyperscan(面向高吞吐网络场景的 SIMD 加速引擎)。在 Redis 这种对延迟极度敏感的单线程系统中,选择 TRE 而非 PCRE 等更重量级的正则库,体现了对性能和安全性的双重考量——既避免了回溯风险,又获得了近似匹配这一独特能力。
ARGREP 支持的选项组合
ARGREP 支持多种选项组合:
MATCH:指定匹配模式AND/OR:多条件逻辑组合LIMIT:限制返回结果数量WITHVALUES:返回匹配的具体值NOCASE:忽略大小写
服务端过滤 vs 客户端过滤的架构权衡
有了 ARGREP,开发者可以直接在 Redis 层面完成复杂的文本搜索,不用再把数据全部拉到客户端做过滤。这种设计体现了分布式系统中一个经典的架构决策:数据过滤位置的选择。
客户端过滤意味着将全量数据通过网络传输到应用层再做筛选,当数据量大时会造成严重的带宽浪费和延迟增加。假设一个数组包含 10 万个元素,但只有 100 个匹配目标模式,客户端过滤需要传输全部 10 万个元素的数据,而服务端过滤只需返回 100 个结果。在典型的微服务架构中,Redis 与应用服务器之间的网络往返时间(RTT)通常在 0.1-1ms 之间,但大数据量传输的序列化/反序列化开销和带宽占用往往是更大的瓶颈。
服务端过滤将计算下推到数据存储层,只返回符合条件的结果集,显著减少网络 I/O。这与数据库领域的「谓词下推」(predicate pushdown)优化思想一脉相承。类似的设计在现代数据系统中广泛存在:Apache Parquet 的列裁剪和行组过滤、ClickHouse 的 PREWHERE 子句、Amazon S3 Select 允许在对象存储层面执行 SQL 过滤、甚至 Linux 内核的 eBPF 也是将数据包过滤逻辑下推到内核空间以避免用户态拷贝。
不过服务端过滤也有代价:复杂的正则匹配会占用 Redis 主线程的 CPU 时间,可能影响其他命令的响应延迟。Redis 的单线程事件循环模型意味着任何一个命令的执行时间过长都会阻塞所有后续命令——这就是为什么 Redis 官方文档一直警告 KEYS * 命令在生产环境中的危险性。因此 LIMIT 参数的存在不仅是功能需要,也是性能保护机制,它确保即使匹配结果很多,命令也能在扫描到足够数量后提前返回。ARSCAN 和游标机制(ARSEEK/ARNEXT)的设计也遵循了同样的思路——将大范围扫描拆分为多次小批量操作,避免长时间阻塞。
在存储日志、标签列表、文本记录等场景下,合理使用 ARGREP 能显著减少网络传输开销,提升查询效率。
浏览器端 WASM 实验场:零安装体验 Redis Array
技术实现
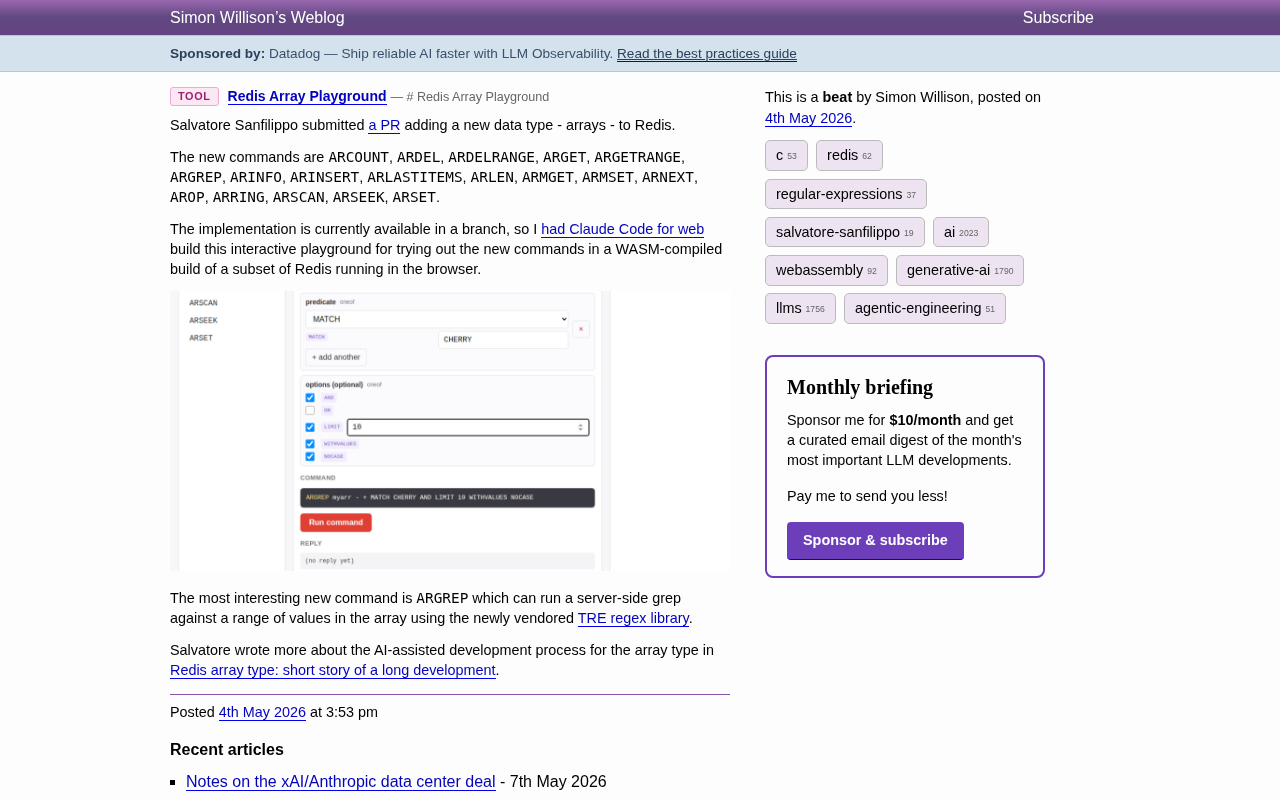
Simon Willison 用 Claude Code for Web 构建了一个完整的 Redis Array Playground。这个工具将 Redis 的一个子集编译为 WebAssembly(WASM),直接在浏览器中运行一个真实的 Redis 实例。打开网页就能开始测试,完全不需要搭建本地环境或连接远程服务器。
WebAssembly 在开发者工具中的应用
WebAssembly 是一种低级字节码格式,最初设计目标是让 C/C++/Rust 等语言编写的程序能在浏览器中以接近原生的速度运行。WASM 的发展经历了几个关键阶段:2013 年 Mozilla 提出 asm.js(JavaScript 的严格子集,可被 AOT 编译优化);2015 年 Google、Mozilla、Microsoft、Apple 四大浏览器厂商联合启动 WebAssembly 项目;2017 年 WASM 1.0 在所有主流浏览器中实现支持;此后陆续加入了多线程(SharedArrayBuffer + Atomics)、SIMD 指令、异常处理、GC(垃圾回收)等提案。
将 Redis 编译为 WASM 需要解决几个关键技术挑战:
系统调用模拟:Redis 依赖的网络 I/O、文件系统、时间函数等操作需要通过适配层来桥接。目前主要有两种路径:一是使用 Emscripten 工具链,它提供了一套完整的 POSIX API 模拟层,将文件操作映射到浏览器的内存文件系统(MEMFS),将网络操作映射到 WebSocket;二是使用 WASI(WebAssembly System Interface),这是一套标准化的系统接口规范,旨在让 WASM 程序能以统一的方式访问操作系统能力,不局限于浏览器环境。对于 Redis Playground 这种场景,由于不需要真正的网络通信(所有操作都在本地完成),主要需要模拟的是内存分配和命令解析/执行的核心路径。
内存管理:WASM 运行在沙箱环境中,拥有一块线性内存空间(默认起始大小可配置,最大可达 4GB),程序通过偏移量访问内存。Redis 的 jemalloc 或 libc malloc 需要在这块线性内存上工作,且内存增长需要显式调用 memory.grow 指令。
类似的技术路线已被多个项目成功验证:SQLite 编译为 WASM(sql.js 和官方的 sqlite3.wasm)、Python 运行在浏览器中(Pyodide 项目,基于 Emscripten 编译 CPython 解释器)、PostgreSQL 的浏览器版本(PGlite)、甚至完整的 Linux 内核(v86 项目)。这些案例证明了将服务端软件搬到浏览器运行的可行性,也催生了「本地优先」(local-first)开发工具的新趋势。
交互设计
这个 WASM 实验场提供了直观的命令构建器界面:
- 左侧边栏列出所有可用的 Array 命令
- 主面板提供可视化的参数配置界面,包括下拉选择、复选框等交互元素
- 底部实时显示构建出的完整命令字符串
- 点击 "Run command" 即可执行并查看返回结果
这种设计把学习新命令的门槛降到了最低——不用记语法,不用翻文档,通过界面点选就能探索每个命令的参数组合和实际行为。这种交互式文档的理念与 Jupyter Notebook、Observable、Swagger UI 等工具一脉相承:最好的文档不是静态的文字描述,而是可以直接运行和实验的活文档。
AI 辅助开发的两个实践案例
antirez 用 AI 开发 Array 类型
Salvatore 在博客文章 Redis array type: short story of a long development 中详细记录了 Array 类型的开发过程。作为 Redis 的创始人,他分享了在复杂系统级 C 语言编程中如何有效利用 AI 工具的经验——哪些环节适合交给 AI,哪些仍然需要人工把控。
在系统级编程中,AI 辅助面临的挑战与应用层开发有本质不同:内存管理需要精确控制(Redis 中一个 off-by-one 错误就可能导致数据损坏)、并发模型需要深入理解事件循环的语义、性能优化需要对 CPU 缓存层级和内存访问模式有直觉性认知。antirez 的经验表明,AI 在生成样板代码、实现已有明确规范的算法、编写测试用例等方面效率很高,但在架构决策、边界条件处理、性能关键路径的优化等方面仍需要资深工程师的判断力。
Simon Willison 用 Claude Code 构建 WASM 工具
Simon Willison 展示了 AI 辅助开发的另一个方向:用 Claude Code 快速构建开发者工具。Claude Code 是 Anthropic 推出的命令行 AI 编程代理工具,与传统的代码补全助手(如 GitHub Copilot 的 inline suggestion 模式)有本质区别:它不是在光标位置提供下一行代码建议,而是能够自主规划任务、读写文件、执行 shell 命令、观察输出结果并迭代修复错误,形成一个完整的「感知-规划-行动-反馈」循环。
Agentic Engineering(代理工程)是当前 AI 辅助编程领域最前沿的范式,指利用这类 AI 代理完成端到端的软件工程任务,而非仅在单个代码片段层面提供建议。与之相关的工具生态正在快速发展:除 Claude Code 外,还有 Cursor 的 Agent 模式、Devin(Cognition Labs)、OpenAI 的 Codex CLI、Aider 等。这些工具的共同特征是具备多步推理能力、工具调用能力(读写文件、执行命令、浏览网页)和自我纠错能力。
在这个案例中,Claude Code 需要理解 Redis 源码结构、配置 Emscripten/WASI 编译工具链、生成交互式前端界面,并确保各环节正确衔接——这种跨多个技术栈(C 语言系统编程 → WASM 编译工具链 → JavaScript/HTML 前端)的协调能力正是 Agentic Engineering 的核心价值所在。传统开发中,这种跨栈任务往往需要开发者在多个文档之间来回切换、反复调试编译配置,而 AI 代理可以将这些碎片化的知识整合为连贯的执行流程。从 PR 记录来看,整个 WASM 编译配置和交互式 UI 的搭建过程高度自动化,体现了 AI 代理在工具链开发中的实际效率。
两种 AI 辅助模式的对比
这两个案例分别代表了 AI 辅助开发的两种典型模式:
| 维度 | antirez 模式(AI 作为助手) | Simon 模式(AI 作为代理) |
|---|---|---|
| 人类角色 | 架构师 + 决策者 | 需求定义者 + 验收者 |
| AI 自主权 | 低(逐步指导) | 高(端到端执行) |
| 适用场景 | 核心系统代码、性能关键路径 | 工具/原型/一次性脚本 |
| 容错空间 | 极低(bug 影响所有用户) | 较高(可快速迭代修复) |
| 代码审查需求 | 逐行审查 | 功能验收为主 |
两种模式的选择取决于代码的关键程度和容错空间。对于 Redis 核心数据结构这种将被数百万生产系统依赖的代码,每一行都需要经过严格审查;而对于一个演示用的 Playground 工具,快速交付和可用性比代码完美性更重要。理解这种区分,是在实际工作中有效利用 AI 编程工具的关键。
Redis Array 的定位与未来展望
Redis Array 类型的引入填补了 Redis 在有序、可索引序列数据结构方面的空白。虽然 Redis 已有 List 类型,但 List 本质上是链表结构,随机访问和范围查询的性能有限。Array 提供了更高效的随机访问、范围查询和服务端正则搜索能力,更适合需要频繁按索引读写的场景。
从应用场景来看,Array 类型可能在以下领域发挥独特价值:
- 时序数据滑动窗口:存储最近 N 个数据点,通过索引快速访问任意时间位置的值,配合
ARRING(环形缓冲区语义)实现固定大小的滚动窗口 - 排行榜快照:与 Sorted Set 不同,Array 可以存储某一时刻的完整排名快照,支持 O(1) 查询「第 K 名是谁」
- 特征向量存储:机器学习场景中,将用户/物品的特征向量存储为 Array,支持快速的按维度访问
- 分页数据缓存:预计算的分页结果直接存储为 Array,通过
ARGETRANGE实现 O(1) 的分页查询 - 配置序列:有序的配置项列表,需要按位置精确读写
值得思考的是 Array 类型与 Redis 模块生态的关系。此前,类似的需求可以通过 RedisJSON(存储 JSON 数组并支持 JSONPath 查询)或自定义模块来满足。但原生类型的优势在于:无需额外部署模块、享受 Redis 核心团队的长期维护和优化、与 RDB/AOF 持久化和主从复制等基础设施无缝集成、以及所有 Redis 客户端库的自动支持。
目前该实现仍在分支阶段,尚未合并到 Redis 主线。不过从 PR 的完整度(18 个命令、完善的测试用例)和配套工具(WASM Playground)来看,这一特性有望在未来的 Redis 版本中正式发布。需要注意的是,Redis 在 2024 年将许可证从 BSD 变更为 RSALv2 + SSPLv1 双许可,这一变化催生了 Valkey(Linux Foundation 主导的 Redis 分支)等替代项目。Array 类型作为许可证变更后的新特性,其在 Valkey 等分支中的可用性取决于各项目的独立开发决策。
如果你的项目需要在 Redis 中存储和查询结构化序列数据,Array 类型值得持续关注。建议先通过 在线 Playground 动手体验,提前熟悉这些新命令的用法。
核心要点
- Redis 创始人 Salvatore Sanfilippo 提交 PR 为 Redis 新增 Array 数据类型,包含 18 个新命令
- ARGREP 命令支持服务端正则搜索,集成 TRE 正则库,可执行近似匹配
- Simon Willison 利用 Claude Code 构建了基于 WASM 的浏览器端交互式实验场,无需安装即可体验
- 该项目同时展示了 AI 辅助系统级编程和工具链快速构建两个方向的实践价值
- Array 类型目前仍在开发分支,提供了比 List 更丰富的随机访问和范围查询能力
相关推荐
 产品体验
产品体验Qoder vs Cursor实测对比:同样20美金谁更强?
实测对比Qoder和Cursor两款AI IDE,从Agent自主修复能力、人工沟通次数、架构决策等维度评测。Qoder仅需2次沟通完成任务,Cursor需8次。详细分析两者差异,帮你选择最适合的AI编程工具。
 产品体验
产品体验Cursor云Agent演示:打通软件开发全链路瓶颈
深度解析Cursor云Agent最新Demo,展示如何通过云端虚拟机、自动测试产物和全链路控制平面,系统性消除软件开发生命周期中的人类瓶颈,让Agent自主运行、人按需介入。
 产品体验
产品体验Cursor 3.0深度解析:多Agent并行、Design Mode与Best-of-N模型对比
Cursor 3.0正式发布,从AI辅助编程工具进化为Agent舰队指挥中心。本文详解多智能体并行、Design Mode可视化编辑、Best-of-N多模型择优等核心功能,解读AI编程新范式。