Redis之父DS4引擎实测:128G Mac本地跑DeepSeek V4表现如何
引言
Redis之父Antirez最近推出了一个名为DS4的推理引擎项目,专门为DeepSeek V4 Flash模型在苹果电脑上的本地部署而设计。这个项目通过独特的量化策略,将原本需要284GB内存的模型压缩到80-85GB,使其能够在128GB的MacBook上运行。B站UP主对这一项目进行了深度实测,从前端小游戏到STM32嵌入式开发,全面检验了本地部署的量化模型在实际编程场景中的表现。
DS4引擎的核心技术亮点
非对称结构感知型量化:不是简单的"一刀切"
DS4引擎最大的技术特色在于其量化思路并非简单粗暴地统一压缩。模型量化是将神经网络中的浮点数权重从高精度(如FP16,每个参数占16位)压缩到低精度(如Q8占8位、Q4占4位、Q2占2位)的技术。精度越低,模型占用的内存越小、推理速度越快,但模型能力也会相应下降。传统量化方法通常对所有层采用统一精度,而DS4的创新在于根据MOE架构中不同组件的重要性分配不同精度——这种方法在学术界被称为混合精度量化(Mixed-Precision Quantization)。
与通常的量化模型不同,DS4专门针对DeepSeek V4 Flash的MOE(Mixture of Experts)架构做了非对称结构感知型量化。MOE架构是当前大规模语言模型的主流设计范式之一,其核心思想是将模型的前馈网络层拆分为多个"专家"子网络,每次推理时只激活其中一小部分专家来处理输入。DeepSeek V4 Flash采用的MOE架构包含数百个专家模块,但每个token只会被路由到少数几个专家进行计算,这使得模型虽然总参数量巨大(600B+),但实际推理时的计算量远小于同等规模的稠密模型。
具体量化策略如下:
- 共享专家、路由网络、投影矩阵及注意力层均保持Q8或FP16的高精度,确保模型的决策能力和工具调用可靠性不会大幅下降。路由网络(Router)负责决定每个token应该被分配给哪些专家,这个决策过程对模型输出质量至关重要,因此对其保持高精度量化是有充分技术依据的
- 基于MOE的使用频率、共线度、差异做了分层处理,对不同专家模块采用不同的量化精度
- 通过KV缓存磁盘持久化,保留了1M的超长上下文能力。KV缓存是Transformer模型推理时的核心机制——在自回归生成过程中,模型需要存储之前所有token的注意力键值对以避免重复计算。对于支持100万token超长上下文的模型,KV缓存的内存占用可能达到数十GB。DS4通过将KV缓存持久化到磁盘,利用苹果芯片高速NVMe存储的优势,在内存不足时将部分缓存卸载到磁盘,从而在128GB内存限制下仍能维持超长上下文能力
这种精细化的量化策略使得模型从284GB压缩到80-85GB,在128GB Mac上可以完美运行。苹果M系列芯片采用统一内存架构(Unified Memory Architecture),CPU和GPU共享同一块物理内存,无需像传统PC那样在系统内存和显存之间进行数据拷贝。128GB的Mac可以将全部内存用于模型加载和推理,虽然Mac GPU的算力不如专业显卡,但内存带宽(M4 Max可达546GB/s)足以支撑大模型的推理需求,这也是DS4专门针对Mac平台进行优化的原因。项目官方也明确表示,主要注重的是Coding方面的表现。
部署流程与使用方式
实测中,UP主使用Q2量化版本进行部署,整个模型约60GB,下载耗时两个多小时。Q2意味着每个参数仅用2位表示,信息损失非常大,这也解释了为何该版本在复杂任务中表现明显弱于满血版。你可能没注意到,终端下载需要手动配置代理端口(默认7890),因为代理工具的智能模式和全局模式都无法覆盖终端环境。
DS4提供三种使用方式:
- CLI交互模式 — 命令行直接对话
- HTTP服务器模式 — 可接入第三方工具
- 内置Code Agent — 编程助手,支持写代码和调试
UP主选择了HTTP服务器模式,将Mac作为推理服务器,在Windows电脑上通过Trae(字节跳动的AI IDE)进行调用和演示。
实测一:贪吃蛇小游戏开发
为了公平对比,UP主同时创建了两个项目:一个使用本地部署的DS4量化模型,另一个使用DeepSeek官网的满血版V4 Flash,执行相同的贪吃蛇游戏开发任务。
本地量化版表现
- 总共输出446行代码
- 意外地主动调用了技能(Skill),并输出了两个文档(PRD和架构设计)
- 游戏可以直接运行,没有明显bug
- 但每次对话的token转换耗时较长
线上满血版表现
- 输出161行代码,更加精简
- 游戏体验更流畅,速度更快
- 存在一个小bug:不会自动开始,需要刷新页面
有趣的是,本地量化版虽然速度慢,但在Skill调用和SOP遵循方面表现出色,甚至主动生成了技术文档。这说明DS4在Agent能力方面的量化保留做得不错——这与其对路由网络和注意力层保持高精度的策略直接相关,模型的"决策"能力(选择调用什么工具、遵循什么流程)得到了较好的保护。
实测二:STM32嵌入式开发
这是更具挑战性的测试场景。STM32是意法半导体推出的基于ARM Cortex-M内核的微控制器系列,广泛应用于工业控制、物联网设备和消费电子产品。与前端开发不同,嵌入式开发涉及硬件寄存器配置、交叉编译工具链(如ARM GCC)、Makefile构建系统、烧录调试(通过ST-Link等工具)以及外设驱动(如I2C/SPI协议驱动OLED屏幕)等多个环节。每个环节都可能出现与具体硬件版本、引脚配置相关的问题,这要求AI模型不仅能生成代码,还需要理解硬件抽象层和底层通信协议,对模型的知识深度和推理能力要求远高于常规Web开发。
UP主要求本地部署的模型完成一个STM32单片机项目:在OLED屏幕上显示"Hello World"跑马灯效果。
遇到的问题
整个过程暴露了量化模型在复杂编程场景中的多个短板:
- 编译阶段的Makefile问题 — 模型陷入长时间思考,虽然Skill中已经写明了解决方案,但模型花了约半小时才找到原因并解决
- 工具调用频繁出错 — 在整个测试过程中出现了三次工具调用错误,直接导致流程中断。这很可能与Q2量化对模型输出格式精确性的损害有关——工具调用需要模型生成严格符合JSON Schema的结构化输出,而极低精度量化会影响模型对格式约束的遵循能力
- Debug能力不足 — 烧录后屏幕不亮、串口无输出,模型尝试自行debug但效果不佳,等待一刻钟后再次报错
最终,UP主不得不切换到官方满血版V4 Flash来排查问题,并最终使用DeepSeek V4 Pro才将跑马灯效果完整调通。整个本地模型的测试流程耗时约75分钟,体验相当煎熬。
速度瓶颈分析
实测中,本地部署的平均输出速度约为23 tokens/秒(与官方测试数据基本一致),推理时内存占用飙升至110GB。在大模型推理中,token生成速度直接决定用户体验——一般认为30 tokens/秒以上可以实现流畅的对话体验(接近人类阅读速度),而编程场景由于需要生成大量代码,对速度要求更高。23 tokens/秒意味着生成100行代码(约500-800 tokens)需要20-35秒,这在简单任务中尚可接受。
但更关键的瓶颈在于"思考阶段"——DeepSeek V4 Flash采用了类似Chain-of-Thought的推理机制,模型在输出答案前会进行内部推理,这个阶段同样消耗token但对用户不可见,导致实际等待时间远超预期。83.8 tokens/秒的峰值出现在纯代码输出阶段,此时模型无需复杂推理,接近硬件的理论吞吐上限。虽然代码生成阶段的速度"将将能用",但在模型思考和上下文切换阶段等待时间过长,严重影响了开发效率。
总结与建议
DS4当前存在的三大核心问题
经过完整测试,DS4项目目前存在三个主要问题:
- 输出速度偏慢 — 总体约23 tokens/秒,复杂任务中的思考等待时间尤其漫长
- 工具调用不稳定 — 测试中出现3次调用错误,这很可能是模型量化后的"后遗症",极低精度量化损害了模型生成结构化输出的精确性
- 复杂编码能力下降 — 简单的前端开发(如贪吃蛇)可以一次通过,但涉及嵌入式开发的编码和debug就漏洞百出
DS4适合哪些使用场景
尽管存在不足,DS4仍有其独特价值:
- 适合做本地Agent — 在Skill调用和SOP遵循方面表现良好,适合搭建本地知识库管理和隐私内容处理
- 适合辅助编程 — 如果你自己负责核心编码,需要一个免费且相对好用的AI助手,本地部署是不错的选择
- 不适合作为主力编程工具 — 当前阶段,所有本地大模型只能作为提效工具和辅助补充
未来展望
DS4项目的想象空间很大。Salvatore Sanfilippo(网名Antirez)是开源内存数据库Redis的创始人,Redis是全球使用最广泛的键值存储系统之一,被Netflix、Twitter、GitHub等公司大规模采用。他以对系统底层优化的深刻理解和极简主义的工程哲学著称,在C语言系统编程方面有超过20年的经验。2020年从Redis项目退休后转向AI领域探索,DS4项目体现了他一贯的风格:用精巧的工程手段解决实际问题。
针对MOE架构的精细化量化思路代表了本地部署的一个重要方向。随着苹果芯片性能的持续提升(下一代M5系列预计将进一步提高内存带宽和GPU算力)和量化技术的进一步优化(如GPTQ、AWQ等更先进的量化算法持续演进),128GB Mac本地运行600B+参数模型的体验有望显著改善。但就当前而言,如果你追求生产力,满血版API仍然是更务实的选择。
核心要点
相关推荐
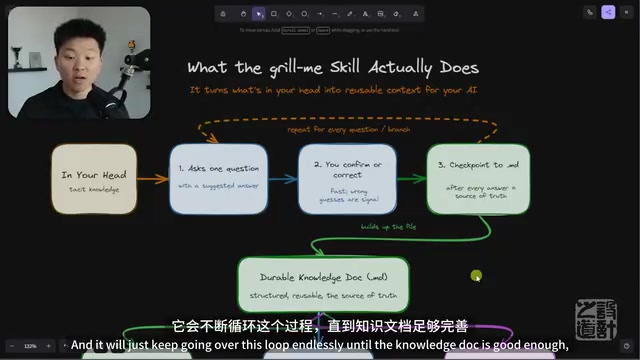
Grill Me技能:让AI拷问你,快速提取隐性知识提升项目效率
详解Grill Me拷问模式技能的核心逻辑与改进版工作流程。通过AI系统化提问提取隐性知识,配合检查点机制持续优化上下文质量,将项目首次迭代成功率从70%提升至90%。
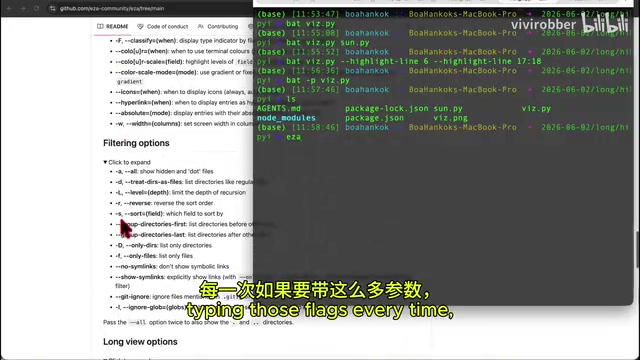
8款终端增强工具推荐:让Claude Code编程体验丝滑翻倍
推荐8款免费终端增强工具:Bat、Eza、Chafa、Zoxide、TLDR、Miru、Yazi、LazyGit,显著提升Claude Code等AI编程工具的使用效率,附安装命令和实用配置。
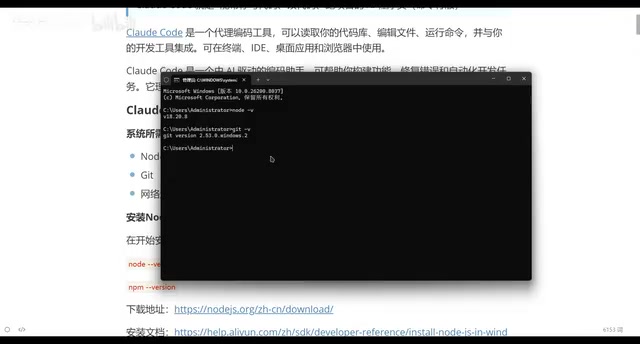
Claude Code安装部署指南:环境配置到成功运行全流程
详解Claude Code安装部署全流程,涵盖Node.js环境配置、NVM版本管理、网络代理设置、API供应商切换等关键步骤,帮助开发者快速上手这款AI编程助手。