Replit领域专用Agent:一键批量修复SEO和安全漏洞
Replit领域专用Agent引发开发者关注
近日,有开发者在社交媒体上分享了对Replit平台领域专用Agent(domain-specific agents)的使用体验,引发了技术社区的广泛讨论。这些专门化的AI Agent能够针对不同领域的问题进行自动检测和修复,标志着AI辅助开发正在从通用代码生成走向更精细化的垂直场景。
所谓领域专用Agent,是相对于通用AI助手而言的一种架构设计理念。在AI Agent的技术体系中,Agent指的是具备感知环境、自主决策和执行行动能力的智能体。通用Agent试图用一个模型解决所有问题,而领域专用Agent则通过限定任务边界、注入领域知识、定制评估标准来实现更高的专业精度。这种设计借鉴了微服务架构的思想——将复杂系统拆解为多个职责单一、高度专业化的服务单元,每个单元在自己的领域内做到极致。
两大核心Agent:Growth增长与Security安全
Growth Agent:自动扫描并发现SEO问题
Replit的Growth Agent(增长代理)专注于网站增长相关的技术优化。它能够自动扫描项目,主动发现潜在的SEO问题,例如缺失的meta标签、不规范的URL结构、页面加载性能瓶颈等。
SEO(Search Engine Optimization,搜索引擎优化)是指通过技术手段和内容策略提升网站在搜索引擎结果页中排名的实践。技术SEO涉及的要素非常广泛,包括meta标签(如title、description)的规范配置、结构化数据标记(Schema.org)、canonical URL去重、sitemap生成、robots.txt配置,以及Google近年来重点考核的Core Web Vitals性能指标——LCP(最大内容绘制)衡量页面主要内容的加载速度,FID(首次输入延迟)衡量页面交互响应性,CLS(累积布局偏移)衡量视觉稳定性。
对于独立开发者和小团队来说,SEO优化往往是一个容易被忽视但又至关重要的环节。传统做法需要借助Google Search Console(Google提供的免费站点管理工具,用于监控网站在搜索结果中的表现)、Lighthouse(Chrome内置的开源自动化审计工具,可评估页面性能、可访问性、SEO等多个维度)等多种工具逐一排查,而Growth Agent将这一流程直接集成到了开发环境中,大幅降低了优化门槛。
Security Agent:主动检测代码安全漏洞
Security Agent(安全代理)聚焦于代码安全层面,能够自动扫描并标记潜在的安全漏洞。检测范围涵盖常见的XSS攻击风险、SQL注入隐患、敏感信息泄露、不安全的依赖包等问题。
这里涉及的几类安全威胁值得展开说明:XSS(Cross-Site Scripting,跨站脚本攻击)是指攻击者将恶意脚本注入网页,当其他用户浏览时脚本被执行,可窃取Cookie或会话信息;SQL注入则是通过在输入字段中插入恶意SQL语句来操纵数据库查询,可能导致数据泄露或篡改。这两类漏洞长期位居OWASP(开放式Web应用安全项目)Top 10安全风险榜单。
安全审计通常需要专业的安全工程师或昂贵的第三方工具来完成。Snyk是一个专注于开源依赖安全扫描的商业平台,能自动检测项目依赖中的已知漏洞并提供修复建议;SonarQube则是一个代码质量和安全分析平台,支持静态代码分析(SAST),可检测代码中的安全热点、代码异味和技术债务。这些工具虽然功能强大,但配置和使用门槛较高,且通常需要额外的费用支出。Replit将安全检测能力以Agent的形式内嵌到开发流程中,让即使没有安全背景的开发者也能在编码阶段就发现并修复潜在风险,真正实现了"安全左移"的理念。
所谓安全左移(Shift Left Security),是DevSecOps领域的核心理念,主张将安全检测从传统的部署后阶段提前到编码和构建阶段。研究表明,在编码阶段修复一个安全漏洞的成本可能只是生产环境中修复成本的几十分之一,越早发现问题,修复的代价越低、风险越小。
杀手级功能:全选 + Agent一键批量修复
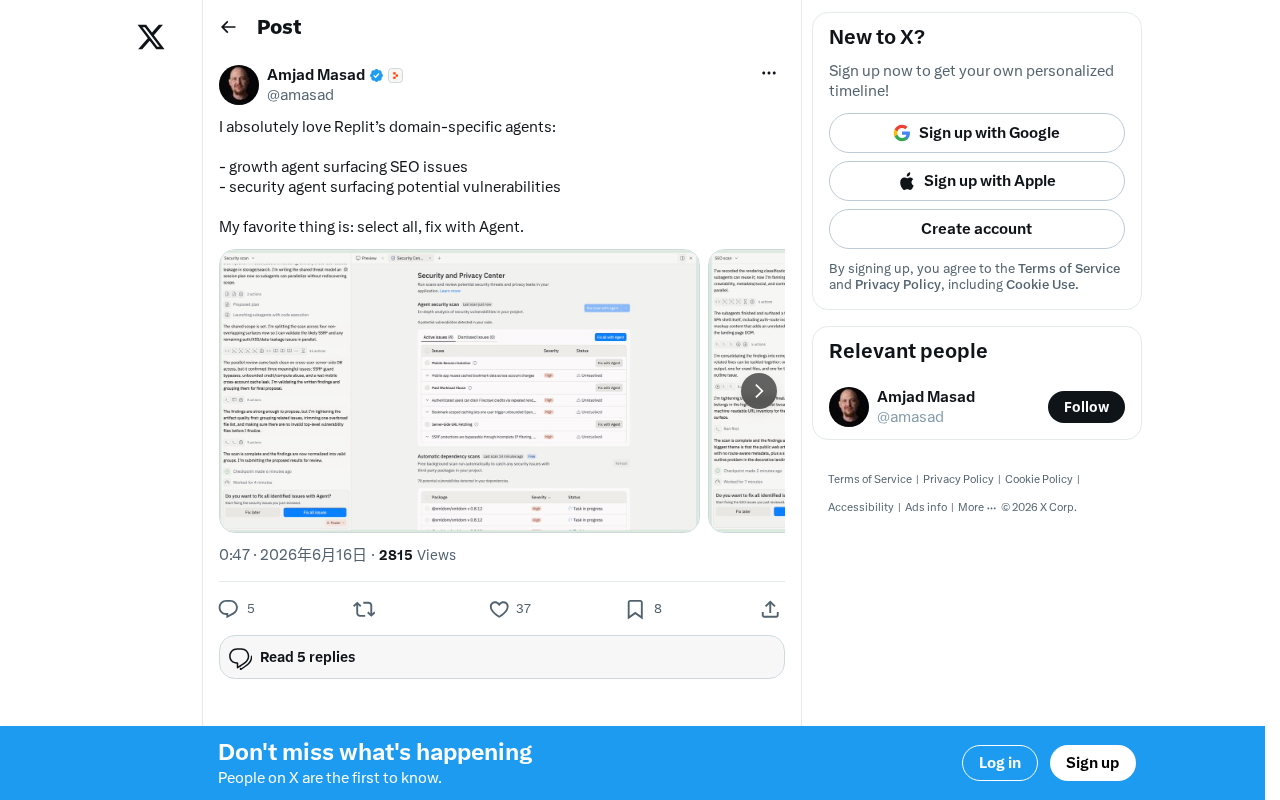
该开发者特别强调了一个令人兴奋的交互模式:"Select All, Fix with Agent"(全选,用Agent修复)。
当Agent扫描出一系列问题后,用户不需要逐个手动处理,而是可以一次性选中所有问题,交由AI Agent批量自动修复。这种工作流将开发者从繁琐的重复性修复工作中彻底解放出来。
举个实际例子:Security Agent扫描出15个安全隐患,你只需点击"全选",再点击"用Agent修复",几秒钟内所有问题就被自动处理完毕。这种体验对于快速迭代的项目来说,效率提升非常显著。
批量修复模式的价值不仅在于节省时间,更在于它改变了人机协作的交互范式。传统的代码修复工作流是串行的:发现问题→理解问题→编写修复→验证修复→处理下一个。而Agent批量修复将这一流程并行化和自动化,开发者的角色从"执行者"转变为"审核者"——只需在修复完成后进行代码审查(Code Review)确认即可。这种模式与自动化测试中的"批量运行、统一报告"理念一脉相承,本质上是将AI的规模化处理能力与人类的判断力进行了合理分工。
行业趋势:从通用AI助手到领域专用Agent
Replit的这一设计思路反映了AI开发工具领域的一个重要趋势——从通用型AI助手向领域专用Agent的演进。
AI辅助编程工具的发展经历了几个明显阶段。最早期是基于规则的代码补全(如IDE内置的IntelliSense),随后是基于统计模型的智能补全(如TabNine早期版本)。2021年GitHub Copilot的发布标志着大语言模型(LLM)正式进入编程辅助领域,它基于OpenAI Codex模型,能够根据上下文生成整段代码,属于通用型能力。此后,Cursor、Windsurf等工具进一步将AI能力从单纯的代码补全扩展到对话式编程和项目级理解。
Replit的Agent化策略则代表了又一次范式跳跃——AI不再等待开发者提问,而是主动巡检、主动发现问题并提供修复方案,从"响应式助手"进化为"主动式专家"。它的做法是将AI能力拆分为多个垂直领域的专用Agent,每个Agent都深耕特定领域,具备更强的专业判断力。
这种架构的优势在于:
- 专业性更强:每个Agent专注于一个领域,检测精度更高
- 可组合性好:不同Agent可以并行工作,覆盖开发全生命周期
- 用户体验更直观:问题按领域分类呈现,开发者可以有针对性地处理
未来我们可能会看到更多类型的领域Agent出现,例如性能优化Agent(自动分析运行时瓶颈和内存泄漏)、无障碍访问Agent(检测WCAG合规性,确保残障用户也能正常使用产品)、国际化Agent(检查硬编码文本、日期格式和字符编码问题)等,逐步构建起一个完整的AI开发助手生态。
对开发者的实际启示
Replit的领域专用Agent模式提供了一个值得关注的方向:AI工具的价值不仅在于"帮你写代码",更在于帮你发现你尚未意识到的问题,并自动解决它们。这种从被动辅助到主动发现的转变,很可能成为下一代AI开发工具的核心竞争力。
对于正在选择开发平台的团队来说,AI Agent的深度和广度正在成为一个越来越重要的评估维度。一个平台能否提供覆盖安全、性能、增长、合规等多个维度的专用Agent,以及这些Agent之间能否协同工作形成闭环,将直接影响团队的开发效率和产品质量。在AI能力日益同质化的今天,谁能在垂直场景中做得更深、更准、更易用,谁就更有可能赢得开发者的长期信赖。
核心要点
相关推荐
微软Build 2026:自研推理模型MAI Thinking-E及AI全家桶深度解析
微软Build 2026发布首款自研推理模型MAI Thinking-E,采用1T参数MoE架构,同步推出6款垂直AI模型。本文详解MAI Thinking-E性能表现、微软AI全家桶布局,以及OpenAI服务崩溃、千问开放生态等行业动态。
Claude Sonnet 4深度体验:两条指令复刻Lovable的实战测试
深度体验Claude Sonnet 4模型,展示如何用两条指令复刻Lovable平台、生成McKinsey级研究报告、开发2D游戏等实战案例,解析AI Agent积木经济新范式。
APImart体验:一站式低价调用GPT、Claude等主流大模型
实测APImart API聚合中转站,支持GPT-4o、Claude、Veo等主流AI大模型统一调用。GPT图像生成低至4分钱一张,详解注册使用流程、生成效果、价格对比及注意事项。