日均5亿Token:DeepSeek驱动UE5项目AI编程实战经验
UE5开发者日耗5亿Token,用多智能体架构实现AI深度辅助编程
一位UE5开发者分享了将DeepSeek API深度融入虚幻引擎开发的实战经验:日均消耗约5亿Token,通过模型分级使用(Pro处理复杂任务、Flash处理简单任务)和90%以上的KV缓存命中率,将日均成本控制在20-60元。项目采用Headerless多智能体架构,遵循文档先行原则,实现了从设计到编码到审查的完整AI工作流。
概述
DeepSeek V4 Pro近期宣布2.5折永久折扣,这对重度API用户来说无疑是重大利好。一位UE5(虚幻引擎5)开发者分享了他的实战经验——每天消耗约5亿Token,累计充值已超1000元,将AI编程深度融入虚幻引擎项目开发的全流程。本文将解析他的架构设计、成本控制策略以及实际工作流程。
关于虚幻引擎5的复杂度: UE5是Epic Games开发的次世代游戏引擎,以Nanite虚拟几何体、Lumen全局光照等技术著称。其代码库极为庞大,仅引擎核心C++代码就超过数百万行,游戏项目还需要处理蓝图脚本、材质系统、动画状态机、网络同步、物理模拟等高度耦合的子系统。这种复杂性使得UE5项目成为AI辅助编程的极端压力测试场景——AI不仅需要理解C++语法,还需要掌握UE5特有的宏系统(如UCLASS、UPROPERTY)、垃圾回收机制以及各子系统之间的依赖关系,因此也是验证AI编程能力上限的理想场景。
惊人的Token消耗与成本控制
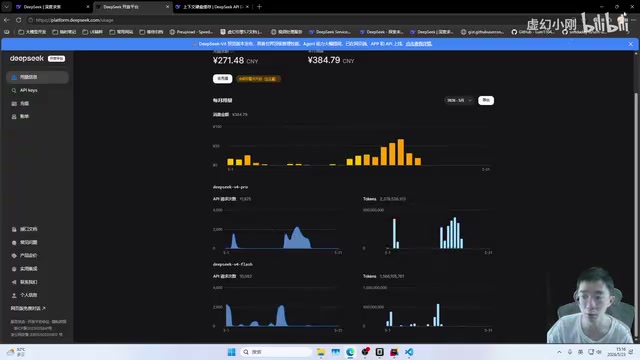
这位开发者从4月底DeepSeek发布以来就开始大规模使用API,基本上每天消耗数亿Token。已充值约1000元,用掉七八百元。看起来数字惊人,但实际日均成本控制在20-60元之间,这得益于两个关键策略:
模型分级使用: 复杂编程任务使用Pro版本(思考能力更强),简单的代码审查等任务使用Flash版本。开发者明确表示,Pro和Flash两个版本的能力差距"特别特别大",Pro在复杂任务上明显更强。
缓存命中率优化: 这是成本控制的核心。通过合理设计上下文结构,项目的缓存命中率保持在90%以上,最佳状态达到95%-98%。命中缓存的价格远低于首次计算的价格,这是DeepSeek API的KV缓存机制带来的巨大优势。
KV缓存机制原理: KV缓存(Key-Value Cache)是大语言模型推理优化的核心技术。在Transformer架构中,每个Token的注意力计算需要访问之前所有Token的Key和Value矩阵。KV缓存将这些中间计算结果存储起来,避免重复计算相同的上下文前缀。对于API服务商而言,当多个请求共享相同的上下文前缀时(如系统提示词、项目文档),服务端可以复用已缓存的KV状态,计算量大幅减少,因此对用户收取更低的价格。DeepSeek的缓存命中价格通常仅为首次计算价格的1/10甚至更低,这也是为什么90%以上的缓存命中率能将实际成本压缩到理论峰值的极小比例。要实现高缓存命中率,关键在于保持上下文前缀的稳定性——将不变的项目文档、系统提示词放在上下文最前面,将每次变化的用户输入放在最后。
Agentic架构:从Prompt到Headerless的演进
开发者提到了AI应用架构的演进路径:从Prompt(简单提示词)到Context(上下文工程)再到Headerless(无头架构)。他的项目已经采用了Headerless架构,这意味着AI系统能够自主管理上下文、调度任务,而不依赖单一的对话入口。
Headerless架构的演进逻辑: Headerless架构(无头架构)源自Web开发领域,原指前后端彻底解耦、后端只提供API接口的设计模式。在AI Agent语境下,这一概念被重新诠释:系统不再依赖单一的对话入口或固定的提示词模板,而是由AI系统自主管理上下文生命周期、动态调度子任务、协调多个Agent之间的信息流转。这与早期的Prompt Engineering(静态提示词设计)和Context Engineering(上下文窗口管理)有本质区别——后两者仍以人类为主导设计交互结构,而Headerless架构赋予AI系统更高的自治权,能够根据任务状态自主决定何时读取文档、何时调用哪个子Agent、何时终止任务链。这种架构更接近AutoGPT、LangGraph等Agentic框架所追求的目标,代表了AI工程从"工具使用"向"自主协作"的范式跃迁。
初始化流程设计
每次启动时,系统会按照项目约定的模式读取所需文档和上下文,消耗约5万Token进行初始化。但由于缓存机制,这部分几乎全部命中缓存,实际成本极低。整个项目支持100万Token的上下文窗口,初始化仅占5%的容量。
多智能体协作方案
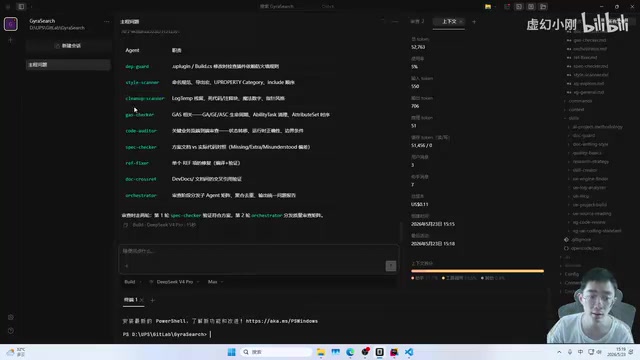
项目中部署了多个专用智能体(Agent),按不同领域组织:
- 编码Agent: 负责根据设计文档编写代码
- 审查Agent: 对代码进行质量审查
- 调研Agent: 进行技术调研
- 构建Agent: 处理项目构建相关任务
- 方法论Agent: 提供架构和方法论指导
简单的Agent(如审查)使用便宜的Flash模型,深度任务则使用Pro模型。在2.5折永久折扣后,开发者倾向于"能用Pro就用Pro"。
多智能体协作的工程价值: 多Agent系统将复杂工作流拆解为职责明确的子任务,其理论基础来自软件工程中的关注点分离原则(Separation of Concerns)。这种设计有几个关键工程优势:首先,专用Agent的系统提示词更短更精准,上下文前缀更稳定,缓存命中率因此更高;其次,不同复杂度的子任务可以路由到不同能力层级的模型,实现成本与质量的精细化平衡;第三,多Agent可以并行执行互不依赖的任务(如同时进行文档编写和代码审查),缩短整体完成时间。微软的AutoGen、Anthropic推荐的多Agent框架以及LangGraph都在探索这一方向,而该开发者的实践证明这套模式在真实生产环境中具备可行性,并非仅停留在实验室阶段。
文档先行的AI开发工作流
开发者强调了一个核心原则:必须让AI先写文档,再写代码。如果跳过文档直接编码,"所有设计都是飘的"。
完整的工作流程如下:
- 设计文档编写: AI根据需求生成详细的设计文档
- 代码实现: AI根据文档进行编码
- 文档-代码比对审查: AI对比文档和代码,检查一致性
- 自动化测试: AI执行测试验证
- 人工最终审查: 开发者做最后确认
- 提交代码
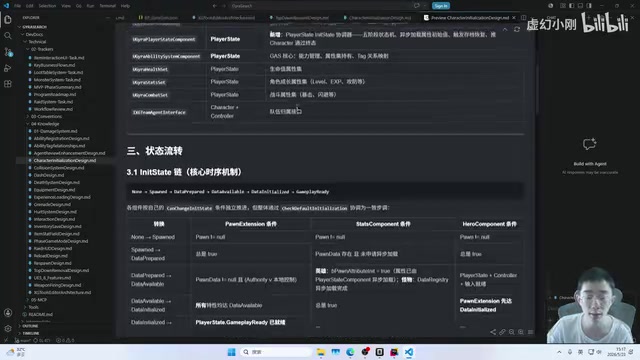
文档先行原则的深层原因: 这一原则在软件工程中并不新鲜——它对应的是"设计驱动开发"(Design-Driven Development)的思想。但在AI编程场景下,文档先行有额外的技术意义:大语言模型本质上是基于上下文的概率预测系统,当上下文中缺乏明确的设计约束时,模型会倾向于生成"合理但不一致"的代码——每次调用都可能做出不同的隐式设计决策,导致多个模块之间出现接口不兼容、命名不统一等问题。详细的设计文档将这些隐式决策显式化,为所有后续的AI调用提供稳定的"锚点
相关推荐
 教程攻略
教程攻略Cursor+Codex双IDE协同:开源项目二开实战方法论
基于实战经验总结的开源项目二次开发完整方法论,详解Cursor+Codex双IDE协同工作流,涵盖二开七环节、MVP验证、AI读源码技巧,帮助开发者三天跑通项目、两周完成业务集成。
 教程攻略
教程攻略Cursor多Agent实战:50分钟搭建Next.js全栈博客
使用Cursor IDE多Agent协作模式,50分钟内从零搭建全栈博客。涵盖Next.js、Clerk认证、Supabase数据库集成,详解4个AI Agent分阶段开发流程与关键避坑经验。
 教程攻略
教程攻略从零搭建AI软件工厂:Cursor工程师的多Agent协作实战经验
Cursor工程师Eric分享AI软件工厂构建实战:从自动化六层级、护栏设计、并行Agent管理到规模化扩展,详解如何用多Agent协作实现7×24小时高效软件开发。