GPT 5.5 vs Claude Code vs DeepSeek V4:三大编码模型实测对比
GPT 5.5、Opus 4.7与DeepSeek V4三大AI编码模型实战对比评测
YouTube博主通过3D飞行模拟器和WebGPU着色器登陆页两个高难度实战测试,对比了GPT 5.5+Codex、Opus 4.7+Claude Code和DeepSeek V4 Pro+OpenCode三大AI编码组合。结果显示GPT 5.5综合最强且token效率最高,Opus 4.7设计品味更佳但成本高3倍,DeepSeek V4虽便宜8倍但复杂任务表现最差,更适合简单场景。三者无供应商锁定,开发者可按需选择。
在过去24小时内,AI编码领域迎来了两个重磅更新:OpenAI发布了GPT 5.5,Anthropic的竞争对手DeepSeek也推出了V4版本。面对三大顶级编码模型——GPT 5.5(搭配Codex)、Opus 4.7(搭配Claude Code)和DeepSeek V4 Pro(搭配OpenCode),普通开发者该如何选择?YouTube博主Chase通过两个高难度实战测试,给出了详细的对比答案。
技术架构背景:这三种组合代表了当前AI编码工具的主流架构模式:大语言模型(LLM)+ 专用编码执行环境。Codex是OpenAI专为代码生成优化的执行层,能够在沙箱环境中运行代码并迭代修正;Claude Code则是Anthropic推出的终端原生编码代理,可直接操作文件系统、执行命令;OpenCode是面向DeepSeek模型的开源编码代理框架。这种"模型+代理"的组合架构,使得AI不再只是生成代码片段,而是能够完成完整的软件开发任务闭环。
价格与基准测试:DeepSeek便宜8倍,但性能如何?
在正式开测之前,先看看三款模型的硬指标。
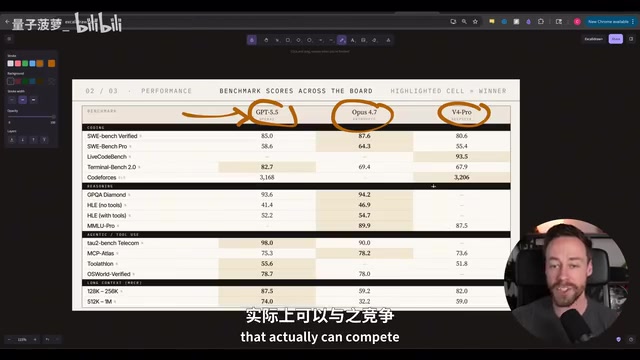
价格对比方面差异显著:每百万输出token,GPT 5.5收费30美元,Opus 4.7收费25美元,而DeepSeek V4 Pro仅需3.48美元。输入token方面,GPT 5.5和Opus 4.7均为5美元/百万,DeepSeek约1.70美元。DeepSeek的价格优势接近8倍,这是一个不可忽视的因素。
Token经济学:Token是大语言模型处理文本的基本单位,大致对应英文中的3/4个单词或中文的1-2个汉字。在AI编码场景中,token消耗来自多个维度:输入侧包括用户提示、代码上下文、错误信息反馈;输出侧包括生成的代码、解释说明和规划文本。本次测试中Opus 4.7在飞行模拟器任务消耗了约20万token,按$25/百万输出token计算约需5美元;而GPT 5.5仅用6.6万token完成同等任务,按$30/百万计算约2美元,实际成本反而更低。对于高频使用AI编码工具的开发团队,这种token效率差异在月度账单上会产生显著影响。
不过OpenAI声称,虽然5.5的单价是5.4的两倍,但由于模型更强大、使用的token更少,实际完成同一任务的成本仅增加约20%。
基准测试方面,三款模型在SweetBench Verified、SweetBench Pro和TerminalBench 2.0三个编码基准上都有报告数据:
- SweetBench Verified和SweetBench Pro:Opus 4.7胜出
- TerminalBench 2.0:GPT 5.5以87%的成绩大幅领先,甚至超过了Anthropic尚未发布的Mythos模型
基准测试解读:SweetBench(原名SWE-bench)是目前AI编码领域最权威的评测基准之一,由普林斯顿大学团队开发。它从GitHub真实Issue中提取任务,要求模型在实际代码仓库中定位并修复Bug,Verified版本经过人工验证确保任务可解,Pro版本则难度更高。TerminalBench 2.0是专门评测模型在终端环境中完成复杂多步骤任务能力的基准,更贴近真实开发场景中的命令行操作。值得注意的是,基准测试成绩与实际开发体验之间往往存在落差——基准测试通常针对标准化任务,而真实项目中的创意性、视觉审美和复杂系统集成能力很难被量化捕捉,这也是本文实战测试的价值所在。
你可能没注意到,DeepSeek V4 Pro虽然总是排在第三,但与第二名的差距并不大——在SweetBench Verified上仅差约5个百分点,考虑到8倍的价格差距,这个性价比相当可观。
另一个有趣的发现是,Opus 4.7在长上下文(50万-100万token)检索方面表现明显退步,远不如DeepSeek和GPT 5.5。
测试一:3D飞行模拟器——GPT 5.5完胜
第一个测试要求三个模型用Three.js创建一个浏览器内运行的飞行模拟器,要求飞行手感好、有重量感、视觉效果强。
为什么飞行模拟器是高难度测试:Three.js是基于WebGL的JavaScript 3D图形库,广泛用于浏览器端3D可视化开发。飞行模拟器之所以极具挑战性,在于它需要AI同时处理多个复杂子系统:物理引擎(升力、阻力、重力、失速模型)、3D场景渲染(地形、云层、光照)、仪表盘HUD(高度表、速度表、航向仪、垂直速度指示器)以及用户输入响应。这些系统之间存在紧密的数学耦合关系,例如AGL(Above Ground Level,离地高度)需要实时计算飞机与地形的相对位置,AOA(Angle of Attack,攻角)直接影响升力计算。任何一个子系统的逻辑错误都会导致整体体验崩溃,这正是为什么DeepSeek和Claude在首次尝试时都出现了严重问题。
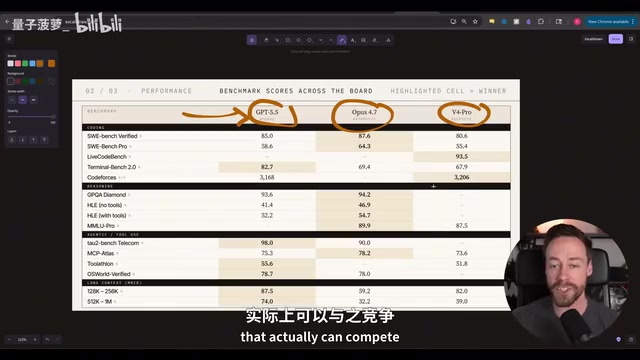
GPT 5.5 + Codex的表现
GPT 5.5约7分钟完成首次构建,使用63,000 token。第一版虽然有云层、AOA指示器、速度表等元素,但飞机根本无法起飞。经过两轮修改提示后(总计约66,000 token,15分钟),终于实现了可飞行的版本:有跑道、有云层、有完整的仪表盘(垂直速度、高度、航向、AGL等),虽然操控有些生硬,但整体完成度相当不错。
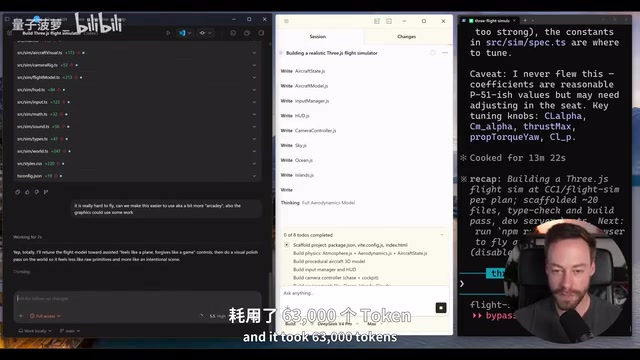
DeepSeek V4 Pro + OpenCode的表现
花了约10分钟、63,000 token(仅0.44美元),但结果令人失望。第一版完全无法辨认画面内容,第二版虽然能看到飞机,但图形渲染完全混乱。测试者坦言,即使再给更多提示,也需要从头开始用非常具体的指令重写,这已经不是"迭代优化"的范畴了。
Opus 4.7 + Claude Code的表现
计划阶段就花了5分钟(最详细的规划,涵盖飞行模型、失速蜂鸣器等细节),执行又花了13分钟,总计约200,000 token。但结果也不理想——加载后立即被弹射到空中并失速坠毁,经过两轮修改仍然存在控制问题和奇怪的雾效。不过至少有飞机、有跑道(虽然跑道上长了树),基本元素都在。
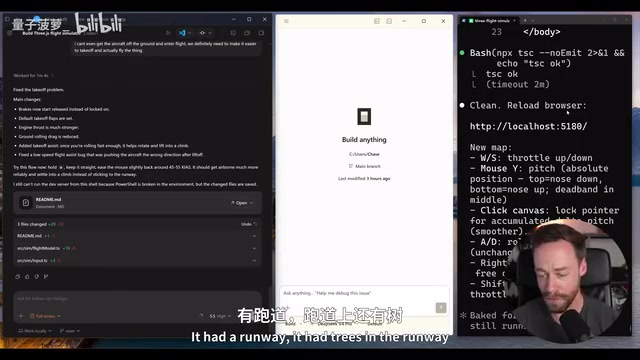
飞行模拟器测试结论:GPT 5.5完胜,用最少的token(66K vs 200K)、最短的时间,产出了最好的结果。Claude Code排第二,有潜力但需要更多迭代。DeepSeek完败。
测试二:WebGPU着色器登陆页——审美之争
第二个测试要求创建一个展示WebGPU着色器效果的登陆页面,要求现代感强、视觉冲击力大,类似Awwwards获奖网站的风格。三个模型都被提供了相同的技能文件。
WebGPU技术背景:WebGPU是W3C正在推进的下一代Web图形API标准,于2023年在Chrome中正式落地。相比沿用多年的WebGL(基于OpenGL ES),WebGPU直接对接现代GPU架构(如Vulkan、Metal、DirectX 12),提供更低的CPU开销、更强的计算着色器能力和更好的多线程支持。在粒子系统场景中,WebGPU的计算着色器(Compute Shader)可以将数十万粒子的物理模拟完全卸载到GPU并行计算,而WebGL在这方面能力有限。这也解释了为何三个模型都选择粒子系统作为核心视觉元素——粒子系统是展示WebGPU计算能力最直观的Demo场景,但同时也对模型理解GPU编程范式提出了较高要求。Awwwards是全球顶级网页设计奖项平台,获奖作品通常代表当年最前沿的Web视觉技术应用。
有趣的是,三个模型在规划阶段都不约而同地选择了粒子系统作为核心视觉元素。
各模型表现
GPT 5.5(107K token,约6分钟):创建了一个带有交互式粒子场的页面,支持鼠标吸引/排斥粒子。但粒子太亮,遮挡了文字。经过修改后有所改善,但整体设计被评价为"有点丑"。
Opus 4.7(175K token,略长于GPT 5.5):风格更加克制优雅,有微妙的胶片颗粒效果和从下到上的模糊过渡,使用了25万个粒子。虽然不够"闪亮",但整体品味更好。
DeepSeek V4(130K token,约1.43美元,耗时最长):产出了一个可能引发"癫痫"的粒子场,第二版加了一些视差效果和类似UFO的元素,但整体效果依然很粗糙。
登陆页测试结论:Opus 4.7在审美和设计品味上胜出,GPT 5.5完成了任务但不够美观,DeepSeek再次垫底。
综合评价:竞争格局下开发者如何选择
综合两个测试来看:
GPT 5.5 + Codex是当前最全面的选择。在飞行模拟器测试中大幅领先,在登陆页测试中虽然审美略逊,但功能完整。token使用效率高,速度快。
Opus 4.7 + Claude Code在设计品味和代码规划深度上有优势,但成本更高(约3-4倍token消耗)、速度更慢。适合对设计质量有更高要求的场景。
DeepSeek V4 Pro在两个高难度测试中都表现不佳,但价格优势巨大。它可能更适合简单任务——当你不需要Opus或GPT 5.5级别的能力时,8倍的价格差距确实值得考虑。正如测试者所说:"DeepSeek的登陆页确实不好看,但它真的比别人差8倍吗?这很难量化。"
最重要的一点是:这三个工具之间没有真正的供应商锁定。无论你学的是Claude Code还是Codex,核心技能都是AI基础能力和构建思维,这些在任何平台上都通用。更多的竞争,对开发者来说只有好处。
核心要点
- GPT 5.5在飞行模拟器测试中完胜,用最少token(66K)和最短时间产出最佳结果,Opus 4.7第二,DeepSeek V4完败
- DeepSeek V4价格仅为竞品的1/8(输出token $3.48 vs $25-30),但在两个高难度编码测试中均表现最差,更适合简单任务
- Opus 4.7在WebGPU登陆页测试中展现出更好的设计品味,但token消耗约为GPT 5.5的3倍,速度也更慢
- 三大模型在基准测试上差距不大(SweetBench差距约5分),但实际复杂任务中表现差异显著
- 三个编码工具之间没有供应商锁定,核心学习的是AI编程基础能力,可自由切换使用
相关推荐
 产品体验
产品体验Qoder vs Cursor实测对比:同样20美金谁更强?
实测对比Qoder和Cursor两款AI IDE,从Agent自主修复能力、人工沟通次数、架构决策等维度评测。Qoder仅需2次沟通完成任务,Cursor需8次。详细分析两者差异,帮你选择最适合的AI编程工具。
 产品体验
产品体验Cursor云Agent演示:打通软件开发全链路瓶颈
深度解析Cursor云Agent最新Demo,展示如何通过云端虚拟机、自动测试产物和全链路控制平面,系统性消除软件开发生命周期中的人类瓶颈,让Agent自主运行、人按需介入。
 产品体验
产品体验Cursor 3.0深度解析:多Agent并行、Design Mode与Best-of-N模型对比
Cursor 3.0正式发布,从AI辅助编程工具进化为Agent舰队指挥中心。本文详解多智能体并行、Design Mode可视化编辑、Best-of-N多模型择优等核心功能,解读AI编程新范式。