Manus vs Google Deep Research vs Flowith:AI智能体课件生成实测对比
三款AI智能体对比实测,低调的Flowith表现最优
本文通过统一提示词,让Manus、Google Deep Research和Flowith三款AI智能体完成Kafka教学课件和解说稿的生成任务。结果显示:Flowith课件结构清晰、任务完成度最高,排名第一;Manus中规中矩,内容完整但缺乏视觉呈现;Google Deep Research表现最差,HTML格式混乱且遗漏解说稿。测试表明产品知名度不等于实际能力,选AI工具应以实际任务为准。
引言
随着AI智能体(Agent)产品的井喷式发展,越来越多的工具开始具备「自主调研 + 内容生成」的能力。AI智能体不同于传统的聊天机器人,它具备自主规划、工具调用和多步骤执行的能力。AI智能体(Agent)的概念源自人工智能领域的BDI(Belief-Desire-Intention)模型,强调自主性、反应性和社会性。与传统聊天机器人基于「输入-输出」的单轮或多轮对话模式不同,AI智能体引入了ReAct(Reasoning + Acting)范式——模型在每一步都先进行推理(Reasoning),再决定下一步行动(Acting),形成一个观察-思考-行动的循环。
一个典型的AI智能体架构包含四个核心模块:规划器(Planner) 负责将复杂任务拆解为可执行的子步骤;工具调用层(Tool Use) 负责调用搜索引擎、代码执行器、文件生成器等外部工具;记忆模块(Memory) 负责在多步骤执行过程中保持上下文一致性;输出层(Output) 负责将结果整合为用户需要的格式。其中,工具调用层的实现方式各有不同——OpenAI的Function Calling、Anthropic的Tool Use以及Google的Gemini Function Calling都是当前主流的技术方案。记忆模块则通常分为短期记忆(当前会话的上下文窗口)和长期记忆(通过向量数据库持久化存储的历史信息),两者的协同决定了智能体在长任务链中的一致性表现。正是这些模块的实现差异,决定了不同AI智能体在面对同一任务时的表现差距。
本文基于一位B站创作者的实测视频,对比了三款热门AI智能体产品——Manus、Google Deep Research 和 Flowith,用同一条提示词让它们完成「生成Kafka教学课件和解说稿」的任务,看看谁才是真正的效率之王。
测试设计:统一提示词,三款AI智能体公平对决
为了保证对比的公平性,测试者对三款产品使用了完全相同的提示词:
请帮我输出一篇关于Kafka的核心原理和应用实践的教程,并产出以下内容:
- 用HTML制作一份精美的教学课件,内容包含Kafka的核心原理和应用实践;
- 产出一份解说稿,以纯文本的形式输出。
为什么选择Kafka作为测试主题
Apache Kafka是由LinkedIn最初开发、后捐赠给Apache软件基金会的分布式事件流平台。它的核心设计理念是高吞吐量、低延迟的消息传递,广泛应用于实时数据管道、流处理和事件驱动架构中。Kafka采用发布-订阅模型,通过Topic(主题)、Partition(分区)、Broker(代理节点)和Consumer Group(消费者组)等核心概念实现消息的高效分发。
Kafka之所以是理想的测试选题,还在于其技术生态的纵深。除了核心的消息队列功能外,Kafka生态还包括Kafka Streams(流处理库)、Kafka Connect(数据集成框架)、Schema Registry(数据格式管理)以及ksqlDB(流式SQL引擎)。其底层存储机制基于分区日志(Partitioned Log),采用顺序写入和零拷贝(Zero-Copy)技术实现极高的I/O性能,单集群可支持每秒数百万条消息的吞吐。理解这些概念需要跨越分布式系统、操作系统、网络协议等多个知识领域,这对AI智能体的知识覆盖广度和深度都提出了很高的要求。
在大数据和微服务架构盛行的今天,Kafka已成为企业级数据基础设施的标配组件,被Netflix、Uber、LinkedIn等公司大规模使用。正因为Kafka的技术体系庞大且概念众多,它成为了测试AI智能体内容生成能力的理想选题——既需要准确理解技术原理,又需要清晰的结构化表达。
任务拆解
这个任务其实并不简单,它要求AI智能体完成以下几个步骤:
- 信息调研:从互联网搜索Kafka相关技术资料
- 内容整理:提炼核心原理和应用实践
- 格式化输出:生成结构化的HTML课件
- 二次创作:根据课件撰写配套解说稿
这是一个典型的复合型任务(Compound Task)——需要AI在单次交互中完成多个相互关联的子任务,且子任务之间存在依赖关系。与简单的问答不同,复合型任务要求AI具备任务分解能力(将大任务拆成小步骤)、上下文传递能力(前一步的输出作为后一步的输入)以及多格式输出能力(同时生成HTML、纯文本等不同格式)。这类任务之所以难,是因为任何一个环节的失误都会级联影响后续步骤的质量,非常考验AI智能体的规划能力和执行质量。
Manus实测:中规中矩,任务完成但缺乏亮点
Manus作为前段时间爆火的AI智能体产品,在这次测试中的表现可以用「及格」来形容。
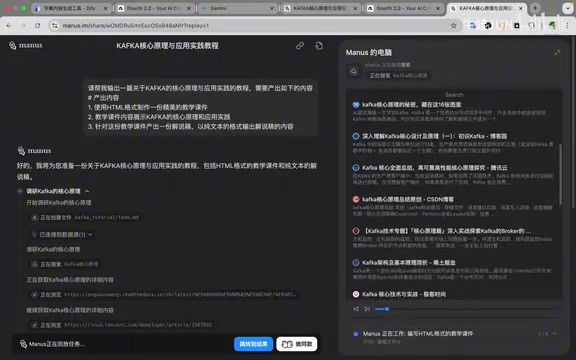
从回放功能可以看到,Manus的工作流程比较清晰:先调研国内网站上关于Kafka的技术文档,先看核心原理,再看应用实践,数据来源主要是国内的博客网站。之后生成HTML格式的教学课件,最后根据课件生成解说稿。
Manus课件质量评价
Manus生成的教学课件全部以文字形式展示,没有任何可视化元素。作为教学课件来说,这种纯文字的呈现方式并不友好——文字量过大,缺乏分块和视觉层次。
让AI生成可直接使用的HTML教学课件,实际上涉及内容组织和前端呈现两个维度的能力。在内容组织层面,AI需要将技术知识按照教学逻辑进行分层——从概念引入到原理讲解再到实践案例,形成循序渐进的知识结构。在前端呈现层面,AI需要生成语义正确的HTML标签、合理的CSS样式以及响应式布局,确保课件在浏览器中能够正常渲染且视觉效果良好。
从技术角度看,让AI生成高质量的HTML教学课件本质上是一个跨模态生成问题。模型需要同时处理三个层次的任务:语义层(HTML5语义标签如<section>、<article>、<figure>的正确使用)、样式层(CSS的Flexbox或Grid布局、响应式媒体查询、字体排版的垂直韵律)以及交互层(可能涉及的JavaScript动画或导航逻辑)。当前主流的大语言模型在代码生成基准测试(如HumanEval、MBPP)上表现优异,但这些测试主要评估逻辑正确性,而非视觉美学。像reveal.js、Slidev等专业演示框架的模板化方案可以部分解决这一问题,但要求AI智能体具备调用这些框架的工具链支持。Manus在内容组织上做到了基本覆盖,但在前端呈现上明显不足,导致课件虽然内容完整,但视觉体验欠佳。
Manus解说稿质量评价
解说稿的内容基本跟随课件结构,算是比较完整的输出。整体而言,Manus完成了任务,但输出结果没有什么亮点,属于「能用但不惊艳」的水平。
Google Deep Research实测:任务未完成,输出格式混乱
作为谷歌推出的深度研究工具,Google Deep Research在这次测试中的表现令人意外地差。
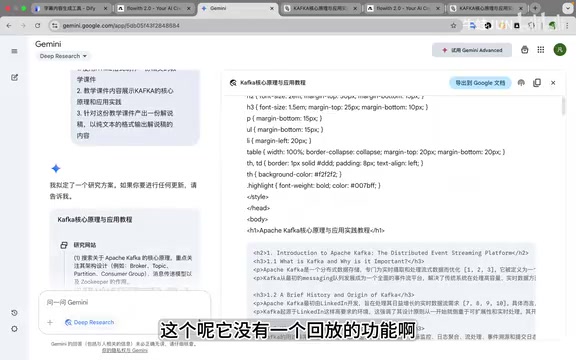
流程规划看似合理
Deep Research制定的流程看起来是合理的:搜索资料 → 整理资料 → 生成HTML课件 → 根据HTML生成解说稿。但实际执行效果与规划严重脱节。
三个致命问题
- HTML输出格式混乱:虽然输出中包含了一些HTML标签,但整体格式是乱的,根本无法作为正常的教学课件使用。
- 解说稿缺失:Deep Research直接遗漏了解说稿的输出,任务没有完成。这恰好印证了复合型任务的级联效应——当HTML生成环节出现问题后,后续依赖该输出的解说稿生成也随之失败。
- 数据来源偏差:所有采集的资料都来自国外网站,虽然搜索范围很广,但对于中文教学场景来说,这些英文资料的适用性存疑。
总结来说,Google Deep Research在这次测试中任务未完成、输出质量差,排名垫底。这也说明Deep Research更擅长深度调研报告类任务,而非这种需要格式化输出的复合型任务。Google Deep Research的核心优势在于其强大的搜索能力和信息综合能力,它能够在海量网页中提取关键信息并生成结构化的研究报告,但当任务要求从「理解内容」跨越到「精美呈现」时,它的工具链支撑明显不足。
Flowith实测:输出最优,课件结构清晰
Flowith是一款相对低调的AI智能体产品,测试者最初是在Manus爆火时发现的一个平替方案。但在这次对比中,它的表现反而最为出色。
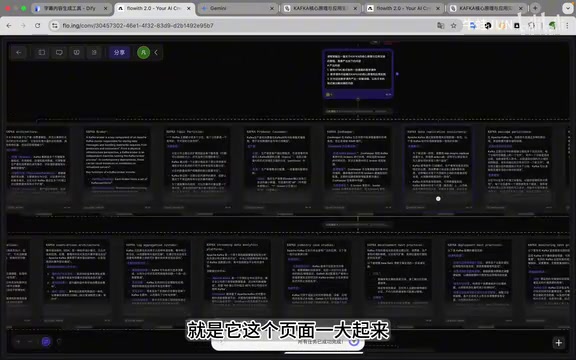
Flowith的工作流程
Flowith的执行逻辑非常清晰:
- 搜索Kafka核心原理相关资料
- 搜索Kafka应用实践相关资料
- 分析整理,生成HTML格式课件
- 根据课件生成解说文档
数据来源包括Kafka官网等国外权威网站,采集的资料内容非常详尽。值得注意的是,Flowith在数据采集策略上采用了国内外综合的方式,既获取了Apache Kafka官方文档等一手权威资料以确保技术准确性,又参考了国内技术社区的中文内容以保证表达的本地化。
三款产品在数据采集环节的差异,本质上反映了各自搜索增强生成(Retrieval-Augmented Generation, RAG) 策略的不同。RAG的核心思想是在生成前先检索相关文档,将检索到的内容作为上下文注入提示词中,从而减少模型的幻觉(Hallucination)并提升事实准确性。RAG流程通常包括查询改写(Query Rewriting)、文档检索(Document Retrieval)、相关性排序(Re-ranking)和上下文压缩(Context Compression)四个步骤。不同产品在查询改写策略(是否将原始问题拆分为多个子查询)、搜索引擎选择(Google、Bing还是专用API)、以及检索结果的融合方式上的差异,直接导致了最终内容质量的分化。Flowith这种平衡策略在很大程度上提升了最终输出的质量和适用性。
Flowith课件质量评价
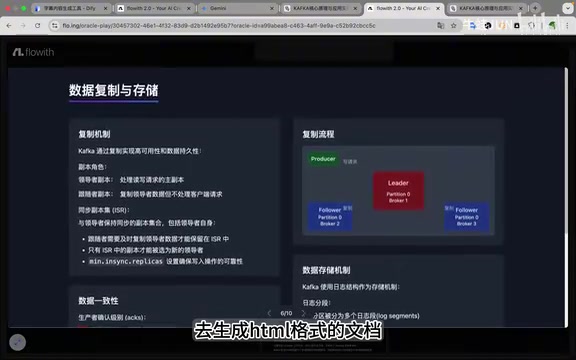
Flowith生成的教学课件是三款产品中最规范的。每个知识点、每个功能点都做了分块处理,结构层次分明,作为教学课件来说是比较理想的输出结果。
不过也存在一些小问题:排版上有些地方略显凌乱。测试者认为,如果换一个更擅长写前端代码的模型来生成HTML,效果应该会更好。当前大语言模型在代码生成方面已有显著进步,但将内容理解与前端美学结合仍是一个挑战——模型能够生成语法正确的HTML和CSS,但在视觉设计的审美判断、间距比例的微调、色彩搭配的协调等方面仍然依赖于训练数据中的模式,缺乏真正的设计直觉。
Flowith解说稿质量评价
解说稿同样做了分块处理,内容完整,与课件结构对应良好。
三款AI智能体综合对比总结
| 评价维度 | Manus | Google Deep Research | Flowith |
|---|---|---|---|
| 任务完成度 | ✅ 完成 | ❌ 未完成(缺解说稿) | ✅ 完成 |
| 课件质量 | 中等(纯文字) | 差(格式混乱) | 较好(分块清晰) |
| 解说稿质量 | 中等 | 缺失 | 较好 |
| 数据来源 | 国内博客 | 国外网站(范围广) | 国内外综合 |
| 流程透明度 | 有回放 | 无回放 | 有详细步骤 |
| 综合排名 | 🥈 第二名 | 🥉 第三名 | 🥇 第一名 |
数据来源策略的深层影响
AI智能体在执行调研任务时,数据来源的选择直接影响最终输出的质量和适用性。本次测试中,Manus主要采集国内博客内容,优势是贴近中文用户的表达习惯和使用场景,但博客质量参差不齐,可能引入不准确的信息;Google Deep Research主要采集国外网站,虽然能获取到Kafka官方文档等权威一手资料,但英文资料在中文教学场景中需要额外的翻译和本地化处理;Flowith综合采集国内外资料,兼顾了权威性和本地化。这种差异反映了不同产品在搜索策略和信息融合能力上的设计取向,也提醒用户在选择工具时需要考虑目标受众的语言和文化背景。
三个关键发现
第一,产品知名度≠实际能力。 Google Deep Research和Manus的知名度远高于Flowith,但在这个具体任务上,低调的Flowith反而表现最好。选择AI智能体时,不能只看品牌光环。
第二,复合型任务是AI智能体的试金石。 单纯的问答或搜索,大多数AI都能胜任。但当任务涉及多步骤规划、多格式输出时,产品之间的差距就会被放大。复合型任务要求AI智能体的规划器、工具调用层、记忆模块和输出层四个核心模块协同工作,任何一个模块的短板都会成为整体表现的瓶颈。
本文的测试方法虽然直观有效,但也引出了一个行业性问题:如何系统化地评估AI智能体的能力?目前学术界和工业界已提出多个评估基准,如GAIA(General AI Assistants)评估智能体在真实世界任务中的表现,WebArena评估智能体在网页环境中的操作能力,SWE-bench评估智能体解决真实软件工程问题的能力。这些基准通常从任务完成率、步骤效率、输出质量和鲁棒性四个维度进行评分。然而,针对复合型内容生成任务(如本文测试的课件+解说稿场景),目前尚缺乏标准化的评估框架,这也是AI智能体领域亟待完善的方向。
第三,格式化输出仍是AI智能体的短板。 即便是表现最好的Flowith,在HTML排版上也存在不足。这提示我们,当前AI智能体在「内容理解」上已经不错,但在「精美呈现」上还有提升空间。未来,随着多模态模型的发展和专门针对前端生成的微调技术的成熟,这一短板有望逐步得到改善。
写在最后:选AI工具别盲目跟风
这次实测给我们一个重要启示:没有万能的AI工具,只有最适合特定场景的工具。 如果你的需求是生成结构化的教学内容,Flowith目前看来是一个值得尝试的选择;如果只是需要快速调研和总结,Manus依然是不错的选项;而Google Deep Research可能更适合纯文本的深度研究报告场景。
值得一提的是,AI智能体领域正处于快速迭代期,各产品的能力边界每隔几周就可能发生变化。本文的测试结果反映的是特定时间点、特定任务下的表现,不代表这些产品的全部能力。建议大家在选择AI智能体时,先用自己的实际任务做一轮测试,而不是盲目跟风。毕竟,能帮你真正提升效率的,才是你的「效率之王」。
核心要点
- 三款AI智能体(Manus、Google Deep Research、Flowith)使用相同提示词生成Kafka教学课件和解说稿进行对比测试
- Flowith表现最优,课件结构清晰、分块合理,任务完成度最高
- Google Deep Research表现最差,HTML输出格式混乱且遗漏了解说稿,任务未完成
- Manus中规中矩,内容完整但课件全为纯文字形式,缺乏视觉层次
- 产品知名度不等于实际能力,选择AI工具应以实际任务测试为准
相关推荐
 产品体验
产品体验Qoder vs Cursor实测对比:同样20美金谁更强?
实测对比Qoder和Cursor两款AI IDE,从Agent自主修复能力、人工沟通次数、架构决策等维度评测。Qoder仅需2次沟通完成任务,Cursor需8次。详细分析两者差异,帮你选择最适合的AI编程工具。
 产品体验
产品体验Cursor云Agent演示:打通软件开发全链路瓶颈
深度解析Cursor云Agent最新Demo,展示如何通过云端虚拟机、自动测试产物和全链路控制平面,系统性消除软件开发生命周期中的人类瓶颈,让Agent自主运行、人按需介入。
 产品体验
产品体验Cursor 3.0深度解析:多Agent并行、Design Mode与Best-of-N模型对比
Cursor 3.0正式发布,从AI辅助编程工具进化为Agent舰队指挥中心。本文详解多智能体并行、Design Mode可视化编辑、Best-of-N多模型择优等核心功能,解读AI编程新范式。