三款PDF Agent Skills实测:B站视频笔记与技术手册一键生成

实测三款AI Agent PDF生成技能插件的功能与效果
本文介绍了AI Agent生态中Skills插件化架构的概念,并实测了三款PDF生成相关的Agent Skills:Bilibili Render PDF能将B站视频自动转化为LaTeX排版的图文笔记,需搭配多模态模型使用;MiniMax PDF支持从零生成专业PDF文档;Any2PDF则解决品牌级PDF制作需求。这些工具展示了Agent Skills如何通过调用外部工具链突破纯文本生成的边界。
AI Agent生态与Skills插件化架构
AI Agent(智能代理)是一种能够自主感知环境、制定计划并执行多步骤任务的AI系统,与传统的单次问答式大模型有本质区别。Skills(技能插件)则是Agent生态中的功能扩展单元,类似于智能手机的App——每个Skill封装了特定的工具调用能力(如网络访问、文件操作、API调用等),使Agent能够突破纯文本生成的边界,真正与外部世界交互。当前主流的Agent框架(如OpenAI的GPT Actions、Anthropic的Tool Use以及各类开源框架)都支持这种插件化架构,这也是为什么PDF生成这类需要调用外部渲染引擎的复杂任务,能够被封装成一个简单易用的Skill。
AI Agent生态日趋成熟,各种实用的Skills(技能插件)正在重塑我们的工作流程。本文实测三款围绕PDF生成的Agent Skills——Bilibili Render PDF、MiniMax PDF和Any2PDF,它们分别解决了视频笔记整理、技术文档转换和品牌级PDF制作的痛点。
视频笔记神器:Bilibili Render PDF
使用场景与工作原理
很多人都有这样的需求:在B站上看到一个优质的技术课程视频,但没时间从头到尾看完,或者看完后想要一份结构化的笔记方便回顾。Bilibili Render PDF这个Skill就是为此而生——它能将B站视频自动转化为图文并茂的LaTeX排版笔记,最终输出为PDF格式。
LaTeX排版技术背景:LaTeX是一种基于TeX排版系统的文档准备语言,由Leslie Lamport在1980年代开发,至今仍是学术界、技术文档领域的黄金标准。与Word等所见即所得工具不同,LaTeX采用标记语言描述文档结构,由编译器负责最终的版面计算,因此能产生极为精确的数学公式、代码块和复杂表格排版。选择LaTeX作为中间格式,正是因为它在处理技术内容(代码、公式、架构图)时的排版质量远超HTML或Markdown直接渲染。不过LaTeX的编译环境(如TeX Live、MiKTeX)体积庞大,这也是为什么此类Skill通常需要在具备完整工具链的沙箱环境中运行。
它的工作流程大致如下:
- 接收用户提供的B站视频链接
- 利用Python库(如yt-dlp)下载视频内容
- 通过FFmpeg等工具提取关键帧和音频
- 调用多模态大模型识别画面内容并总结文字
- 整合为结构化的LaTeX文档,编译输出PDF
FFmpeg与视频处理:FFmpeg是一个开源的跨平台音视频处理框架,被誉为「音视频处理的瑞士军刀」,几乎所有主流视频平台和编辑软件的底层都依赖它。在此流程中,FFmpeg承担了关键帧提取(Scene Detection)和音频分离的核心工作。关键帧提取并非简单地按时间间隔截图,而是通过分析相邻帧之间的像素差异,智能识别画面发生显著变化的时刻(如PPT翻页、演示内容切换),从而以最少的图片数量覆盖最多的信息量。提取出的音频则会进一步通过语音识别(ASR)转为文字,与关键帧图像一起送入多模态模型进行综合理解,这种「视听融合」的处理方式是视频内容理解的主流技术路径。
关键要求:必须搭配多模态模型
这里有一个重要的技术细节:该Skill要求底层大模型具备多模态能力。生成笔记的过程中,AI需要从视频关键帧中识别图片内容——比如代码截图、架构图、PPT页面等,只有能"看懂"图片的模型才能准确提取信息。
多模态大模型技术解析:多模态大模型(Multimodal LLM)是指能够同时处理文本、图像(部分还支持音频、视频)等多种数据类型的AI模型。与纯文本语言模型相比,多模态模型在预训练阶段引入了大量图文对齐数据,使其具备「看图说话」的能力。代表性模型包括GPT-4V、Claude 3系列、Google Gemini以及开源的LLaVA、Qwen-VL等。在Bilibili Render PDF的工作流中,多模态能力至关重要:视频关键帧中往往包含PPT截图、代码片段、架构示意图等视觉信息,纯文本模型只能处理音频转录的文字,而多模态模型能够「读懂」这些图像内容,从而生成更完整、更准确的笔记。这也是为什么模型选择会直接影响最终笔记质量的根本原因。
作者在实测中使用的是Codex作为运行环境,效果较为理想。
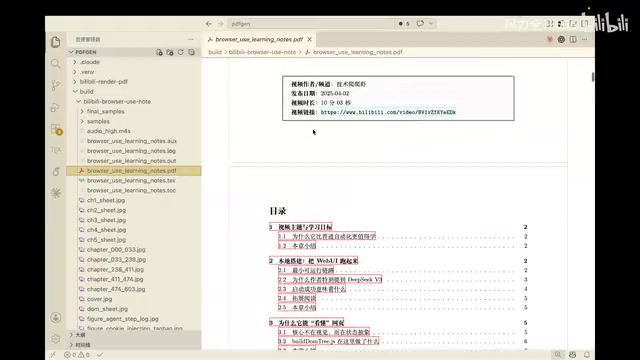
从实际生成的PDF来看,笔记包含了视频的核心知识点、关键截图以及结构化的章节划分。对于那些动辄一两个小时的技术教程视频,这种自动化笔记整理能力可以大幅节省学习时间,同时保留了视觉化的关键信息。
技术文档转PDF:MiniMax PDF与Any2PDF
MiniMax PDF:从零生成专业文档
第二个值得关注的Skill是MiniMax PDF。它的核心能力是从零生成PDF文档,也支持填充PDF表单、改版已有文档等操作。
在实测中,作者让AI先编写一份"零基础小白上手学习RAG
相关推荐
 产品体验
产品体验Qoder vs Cursor实测对比:同样20美金谁更强?
实测对比Qoder和Cursor两款AI IDE,从Agent自主修复能力、人工沟通次数、架构决策等维度评测。Qoder仅需2次沟通完成任务,Cursor需8次。详细分析两者差异,帮你选择最适合的AI编程工具。
 产品体验
产品体验Cursor云Agent演示:打通软件开发全链路瓶颈
深度解析Cursor云Agent最新Demo,展示如何通过云端虚拟机、自动测试产物和全链路控制平面,系统性消除软件开发生命周期中的人类瓶颈,让Agent自主运行、人按需介入。
 产品体验
产品体验Cursor 3.0深度解析:多Agent并行、Design Mode与Best-of-N模型对比
Cursor 3.0正式发布,从AI辅助编程工具进化为Agent舰队指挥中心。本文详解多智能体并行、Design Mode可视化编辑、Best-of-N多模型择优等核心功能,解读AI编程新范式。