SciMDR:7B小模型如何在科研推理上比肩GPT-5

SciMDR框架让7B小模型在科研文献阅读理解上达到GPT-5水平
耶鲁大学等机构推出SciMDR框架,通过"降维构建+升维重塑"两阶段数据合成流水线,解决了科研领域合成数据在规模、真实可靠与现实复杂之间的"不可能三角"困境。该框架先从论文中提取原子级断言并逆向生成高质量问答对,再将其放回长文档真实环境中训练模型的证据定位能力。最终仅70亿参数的模型在科研评测中达到49.1分,大幅超越GPT-4o并接近GPT-5水平。
耶鲁大学、芝加哥大学和TCS Research联合推出了SciMDR框架,通过两阶段数据合成流水线,让仅有70亿参数的小模型在科研文献阅读理解上达到了接近GPT-5的水平。这项研究揭示了一个深刻的道理:在垂直领域,数据质量的突破可以跨越模型参数量的鸿沟。
科研阅读的"死亡之谷":大模型为何也束手无策
尽管大语言模型在代码生成、文本创作等领域表现优异,但面对真正的科研文献时,它们往往会坠入"死亡之谷"。科学论文通常具有数万字的超长上下文,核心信息分布稀疏,图文交织的特征要求AI具备跨越多个页面的关联理解能力。专业术语和复杂的逻辑推导构成了"学术黑盒",进一步加剧了推理难度。
科研文献阅读理解之所以成为AI的难题,根源在于其信息结构与通用文本存在本质差异。一篇典型的学术论文通常包含8000-15000词的正文、20-50个数学公式、10-30张图表,以及大量跨段落的逻辑引用关系。这种信息密度和跨模态特征远超大模型在预训练阶段接触的主流语料(如网页文本、书籍等)。此外,科学论文的论证结构往往是非线性的——结论可能依赖于方法部分的某个细节假设,而该假设又需要结合附录中的数学证明才能完整理解。这种"远距离依赖"对模型的上下文窗口利用效率提出了极高要求。

更深层的问题在于合成训练数据面临的"不可能三角"困境——规模、真实可靠与现实复杂三者之间难以兼得。合成数据(Synthetic Data)是当前AI训练的核心策略之一,其基本思路是利用已有的强模型生成新的训练样本来增强弱模型。然而在科研领域,这一策略面临独特困境。所谓"不可能三角"借鉴了金融学中蒙代尔不可能三角的概念:规模(需要数十万级样本)、真实可靠(答案必须事实正确)、现实复杂(问题需要在真实长文档环境中回答)三者在传统方法中最多只能同时满足两个。这是因为当上下文变长时,即使是GPT-4级别的模型也会出现"注意力稀释"现象,导致生成的答案包含事实错误或逻辑跳跃。
现有方案通常有两种妥协路径:
- 温室效应方案:只给AI提供单一图表或极短的原子语境,生成的问答数据逻辑完美但完全缺乏现实复杂性。一旦脱离理想化环境进入真实长文档,AI会迅速丧失导航和推理能力。
- 野蛮投放方案:直接让AI阅读整篇长论文后生成问答,形态上贴近真实应用,但过大的信息噪音稀释了模型注意力,生成的问答往往包含虚假逻辑,最终污染训练过程。
SciMDR的破局之道:两阶段流水线架构
SciMDR的核心创新在于"降维构建+升维重塑"的两阶段策略,巧妙地将原本矛盾的真实度与复杂性统一起来。
第一阶段:降维打击,锁定绝对正确的事实
SciMDR首先从海量论文中提取原子级的核心断言(claim),像手术刀一样剥离出类似"模型X比模型Y更快"这种极简结论。由于处于极简语境下,AI在这一步几乎不会产生任何逻辑幻觉,从而构建了一套高准确度的底层事实库。
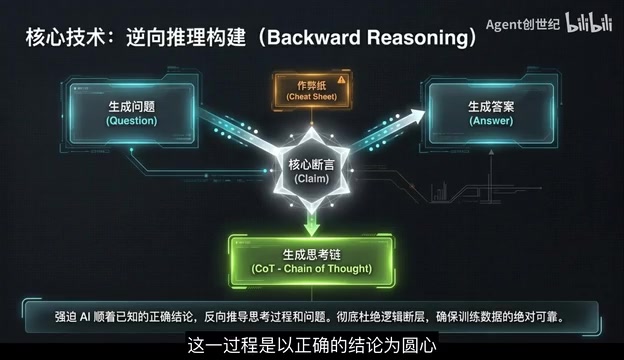
在锁定核心断言后,SciMDR利用逆向推理构建技术生成高质量数据。传统的数据合成采用"前向生成"模式:给定文档→生成问题→生成答案→生成推理链。这种流水线中,每一步的错误都会向下游传播和放大。逆向推理则反转了这一流程:以正确的结论为原点,反向推导问题、答案以及完整的思考链(Chain-of-Thought),并通过生成校验值来辅助校对。这类似于数学中的"逆向归纳法"——当终点已知时,回溯路径的正确性更容易保证。校验值的引入则提供了额外的质量门控,确保生成的推理链在逻辑上自洽。这种方法强迫AI在已知正确答案的前提下回溯推理路径,彻底杜绝了因前向生成导致的逻辑断层。
第二阶段:升维重塑,回归现实丛林
第二阶段将这些经过验证的问答对重新放回原始论文中——包含数万字、数十张图表和复杂公式的长篇背景。其目的在于构建极具挑战性的训练样本,让AI不仅掌握正确的逻辑,还要学会从充满噪音的现实环境中精准定位证据。
这一阶段引入了关键的**信息定位注入(Evidence Localization Injection)**机制,强制AI在回答前先进行文档内的空间导航,例如输出"扫描全文"或"定位至图表三"等具体指令。信息定位注入本质上是一种结构化的注意力引导机制。在传统的长文档问答中,模型需要在数万个token中自行发现相关证据,这一过程高度依赖模型内部注意力机制的自组织能力,容易受到无关信息的干扰。ELI机制通过在训练数据中显式标注证据的物理位置(如"第3节第2段"或"图表4的横轴"),将证据检索从隐式的注意力计算转化为显式的空间导航任务。这与人类阅读论文时的行为模式高度一致——我们通常先快速扫描定位相关章节,再深入阅读具体内容。这种"先定位后推理"的分步策略有效降低了单步推理的认知负荷,使模型练就了穿越长文本噪音的本领,即使面对海量无关信息,也能精准锁定关键论据。
数据集与评测基准:工业级规模的训练资源
SciMDR数据集展现了惊人的工业级规模:涵盖2万篇前沿科学论文,包含30万个经过验证的高质量问答对,每个样本都附带严密的思考链。思考链(Chain-of-Thought, CoT)是由Google Brain团队在2022年提出的提示工程技术,其核心发现是:当模型被要求展示中间推理步骤时,其在复杂推理任务上的表现会显著提升。CoT的有效性源于两个机制:一是将复杂问题分解为多个简单子问题,降低了每一步的推理难度;二是中间步骤提供了"工作记忆"的外化表示,缓解了Transformer架构在长程推理中的信息遗忘问题。在SciMDR中,CoT不仅是推理时的辅助工具,更是训练数据的核心组成部分——每个问答对都附带完整的推理链,使模型在训练阶段就内化了科学推理的思维模式。
从数据构成看,图文融合与纯图表任务占比均超过40%,纯文本仅占15%,这种多模态分布为训练科研AI提供了充足的高质量语料。

为了检验模型在真实科研场景的水平,研究团队还推出了SciMDEval专家级评测基准,包含907个手工标注的高难度问题,专门针对跨越数十页文档的证据定位能力进行考核。该基准将科学思维拆解为五个核心维度:
| 维度 | 考察能力 |
|---|---|
| EQ | 图表与文本支撑关系 |
| CIM | 抽象理论到具体实例的映射 |
| HVI | 跨线索的推理预测 |
| CAC | 批判性分析,判断文本是否夸大数据 |
| ARS | 论点提炼与综合 |
这种维度划分标志着AI从简单的"看图说话"正式向具备批判性思维的科研助手转型。
实验结果:7B模型的性能突破
研究人员选取了仅有70亿参数的Qwen2.5-VL-7B作为基座模型。Qwen2.5-VL-7B是阿里巴巴通义千问团队推出的多模态视觉语言模型,属于Qwen2.5系列的视觉增强版本。该模型采用Vision Transformer(ViT)作为视觉编码器,结合大语言模型的文本理解能力,支持图文混合输入。7B(70亿)参数的规模使其可以在单张消费级GPU(如A100 40GB)上进行推理,部署成本远低于GPT-4o等数千亿参数的闭源模型。选择7B模型作为基座具有重要的实践意义:它代表了学术机构和中小企业可负担的计算规模,如果能在这一量级实现顶尖性能,意味着高质量科研AI工具的民主化成为可能。
通过SciMDR高质量数据的特训,研究团队将其打造为专业的科研推理模型。

在最严苛的SciMDEval真实科研评测中,SciMDR-7B模型的得分达到了49.1分,相比基础模型提升了29.3分。这一成绩不仅大幅超越了GPT-4o的24.7分,更与顶级模型GPT-5的预估水平线持平。在ChartsQA等图表问答任务中,它也显著超越了LLaVA-OV和InternVL3等同级别甚至8B规模的开源模型。
消融实验揭示核心秘诀
消融实验(Ablation Study)是深度学习研究中验证各组件贡献度的标准方法论,其思路类似于生物学中的基因敲除实验——通过逐一移除系统中的某个组件,观察整体性能的变化来量化该组件的重要性。SciMDR的消融实验设计特别精巧:它不仅验证了单个组件的贡献,还揭示了组件间的协同效应。
实验结果进一步揭示了SciMDR高性能的关键因素:
- 定位注入 + 思考链全开:性能达到峰值49.1分
- 关闭定位注入:AI迷失在长文噪音中,性能骤降至22.8分(降幅53.6%),说明在长文档场景中,"知道在哪里找"比"知道怎么想"更为基础
- 仅保留定位,移除思考链:复杂推理能力大幅下降至16.9分,表明即使找到了正确位置,缺乏结构化推理能力也无法得出正确结论
实验有力证明,教会AI"在哪里找证据"和"如何一步步思考"同样重要,两者缺一不可。
实战能力:从图表解读到工程级理解
在CIM(概念-实例映射)实战案例中,SciMDR表现得像真正的工程师——它不仅能解读图例,还能将文本中抽象的"编码器/解码器"概念与架构图中具体的物理模块精准对应,准确锁定图中层叠的residual LSTM模块并理清其物理约束反馈循环。
在HVI(隐藏行为推理)案例中,模型化身专业数据分析师,通过分析多组小提琴图对比GPT-3.5与LLM-A3的隐藏行为倾向,精准推断出GPT-3.5具备跨情景的强社会意图,证明其训练实现了规范泛化而非简单的过拟合。
总结与启示
SciMDR的成功传递了一个清晰的信号:在垂直领域,数据质量的突破可以弥补模型参数量的不足。通过解决合成数据"不可能三角"的质量矛盾,7B小模型也能释放出顶尖科研潜力。这一框架的两阶段思路——先在受控环境中确保逻辑正确性,再将验证过的数据回归真实复杂场景——为其他垂直领域的模型开发提供了极具价值的方法论参考。随着该框架的开源推进,我们有理由期待更多轻量级模型在专业领域实现"以小博大"的突破。
相关推荐
 前沿研究
前沿研究纽约中央公园发现新物种?城市昆虫猎捕计划揭秘
科学家在纽约中央公园和布鲁克林展望公园设置昆虫捕集器,试图在城市环境中发现未知物种。地球90%物种尚未被命名,城市生物多样性研究正成为生态学新趋势。
 前沿研究
前沿研究希格斯玻色子发现始末:亲历者讲述「上帝粒子」背后的故事
费米实验室物理学家亲历讲述希格斯玻色子发现全过程:费米实验室与CERN的跨大西洋竞赛、2012年历史性宣布的幕后细节、从发现到验证的14年科学历程,以及「上帝粒子」名号的真实由来。
 前沿研究
前沿研究Claude Code开源架构深度解析:51万行代码的设计哲学
深度解析Claude Code开源架构的六大核心设计理念,包括双层循环架构、七步工具执行管道、四层Token压缩策略、记忆系统与多智能体协作模式,揭示工业级AI智能体的工程化精髓。