Seaborn内置数据集加载指南:五大常用数据集与本地加载方法
Seaborn五大内置数据集的结构、用途及本地加载方法介绍
本文系统介绍了Seaborn库中Tips、Iris、Penguins、Titanic、Diamonds五大常用内置数据集的字段结构与典型应用场景,并针对国内网络环境下GitHub数据拉取失败的问题,给出了通过data_home参数指定本地路径的稳定加载方案,帮助开发者高效开展数据可视化与机器学习的学习实践。
前言
Seaborn 是 Python 中最受欢迎的数据可视化库之一,内置了多个经典测试数据集,开发者无需额外准备数据就能快速上手练习。Seaborn 由 Michael Waskom 于 2012 年开发,构建在 Matplotlib 之上,专注于统计数据可视化。它与 Python 数据科学生态中的 Pandas、NumPy、SciPy 等库深度集成,能够直接接受 DataFrame 作为输入,大幅简化了从数据处理到可视化的工作流。相比 Matplotlib 需要手动设置大量参数,Seaborn 提供了更高层级的 API 和更美观的默认样式,使得开发者只需一两行代码就能生成专业级的统计图表。在 Python 可视化生态中,Seaborn 与 Plotly(交互式图表)、Bokeh(Web 可视化)形成互补关系,各有侧重。
不过在实际使用中,由于网络原因,直接从 GitHub 拉取数据集经常失败。本文将系统介绍 Seaborn 五大常用内置数据集的结构与应用场景,并给出稳定可靠的本地加载方法,帮助大家高效开展数据分析学习。
Seaborn五大常用内置数据集概览
Seaborn 自带了多个测试数据集,其中最常用的有以下五个:
| 数据集 | 名称 | 主要用途 |
|---|---|---|
| Tips | 餐厅小费数据 | 分类散点图、柱状图 |
| Iris | 鸢尾花数据 | 聚类分析(机器学习经典) |
| Penguins | 企鹅特征数据 | 多分类、配对图 |
| Titanic | 泰坦尼克号数据 | 生存分析、分类任务 |
| Diamonds | 钻石价格数据 | 分布图、回归图 |
这些数据集覆盖了从基础可视化到机器学习的多种应用场景。其中 Tips 和 Iris 是入门阶段最常接触的两个数据集,而 Titanic 则是机器学习分类任务中的经典案例。
数据集加载方法详解
导入必要的库
首先需要导入 Seaborn 和 Pandas:
import seaborn as sns
import pandas as pd
使用 load_dataset 函数加载数据
Seaborn 提供了 sns.load_dataset() 函数来加载内置数据集。默认情况下,该函数会从 GitHub 仓库(mwaskom/seaborn-data)拉取 CSV 文件,并缓存到用户主目录下的 ~/seaborn-data 文件夹中。首次加载时需要网络连接,后续加载会优先读取本地缓存。但国内网络环境下,首次加载经常因为无法访问 GitHub 而失败。
推荐的解决方案是将数据集预先下载到本地,然后通过 data_home 参数指定本地路径:
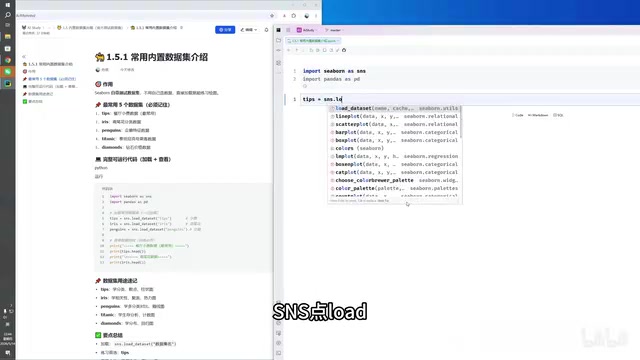
# 加载餐厅小费数据
tips = sns.load_dataset('tips', data_home='/path/to/seaborn-data')
# 加载鸢尾花数据
iris = sns.load_dataset('iris', data_home='/path/to/seaborn-data')
# 加载企鹅数据
penguins = sns.load_dataset('penguins', data_home='/path/to/seaborn-data')
这里有两个关键点需要注意:
data_home参数:指定本地数据文件所在的目录全路径。data_home参数允许开发者自定义缓存目录的位置,这在企业内网环境、教学机房或网络受限的场景下尤为实用。- 第一个参数:数据集的文件名(不含
.csv后缀),与本地文件夹中的 CSV 文件名一一对应
值得注意的是,虽然开发者也可以直接使用 Pandas 的 pd.read_csv() 读取这些 CSV 文件,但通过 load_dataset() 加载的好处是 Seaborn 会自动将某些列转换为 Categorical 类型,优化后续绑图时的分类处理,减少手动数据预处理的工作量。
加载结果验证
执行上述代码后,三份数据集就成功加载到了对应的 DataFrame 变量中:
各数据集字段结构预览
Tips 餐厅小费数据集
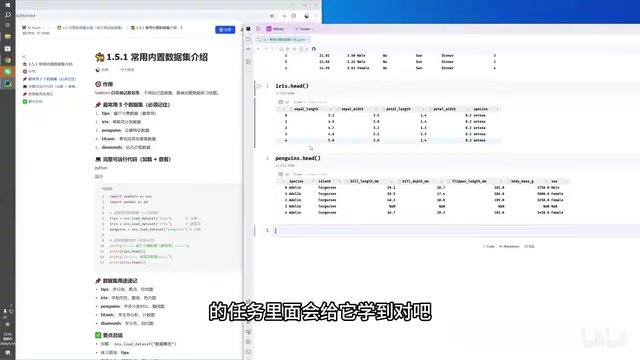
使用 tips.head() 查看前五行数据:
tips.head()
Tips 数据集包含以下字段:
- total_bill:总账单金额
- tip:小费金额
- sex:性别
- smoker:是否吸烟
- day:星期几
- time:用餐时间(午餐/晚餐)
- size:用餐人数
该数据集非常适合用来练习分类散点图和柱状图的绑制,是学习 Seaborn 可视化的入门首选。数据中同时包含数值型变量(账单金额、小费金额、用餐人数)和分类型变量(性别、是否吸烟、星期、用餐时段),这种混合结构使得开发者可以在一个数据集上练习几乎所有常见的统计图表类型。
Iris 鸢尾花数据集
iris.head()
Iris 数据集是机器学习领域最经典的数据集之一,包含以下字段:花萼长度(sepal_length)、花萼宽度(sepal_width)、花瓣长度(petal_length)、花瓣宽度(petal_width)以及花的种类(species)。
该数据集由英国统计学家和生物学家 Ronald Fisher 于 1936 年在其论文《The use of multiple measurements in taxonomic problems》中首次引入,包含三种鸢尾花(Setosa、Versicolour、Virginica)各 50 个样本,共 150 条记录。Fisher 使用这些数据来演示线性判别分析(LDA)方法。由于数据规模适中、特征清晰、类别边界明确(Setosa 线性可分,另外两类存在一定重叠),Iris 成为了模式识别和机器学习领域最广泛使用的基准数据集之一,几乎所有机器学习教材都会以它作为分类和聚类算法的入门示例。在后续学习机器学习聚类任务时,会频繁使用到这个数据集。
Penguins 企鹅特征数据集
penguins.head()
企鹅数据集包含不同种类企鹅的体征特征数据,如喙长(bill_length_mm)、喙深(bill_depth_mm)、鳍长(flipper_length_mm)和体重(body_mass_g)等,适合用于多分类分析和配对图(Pair Plot)的绑制。
该数据集由 Kristen Gorman 博士和南极洲 Palmer 站的研究团队收集,记录了南极洲 Palmer 群岛上三种企鹅(Adelie、Chinstrap、Gentoo)的体征数据,于 2020 年由 Allison Horst 等人整理发布。Penguins 被数据科学社区视为 Iris 数据集的现代替代品——相比 Iris,它包含更丰富的变量类型(数值型和分类型并存)、真实的缺失值,以及更直观的生物学背景,使得教学场景更加贴近实际数据分析工作。
配对图在探索性分析中的价值
配对图(Pair Plot)是探索性数据分析(EDA)中的重要工具,它将数据集中所有数值变量两两组合,在矩阵的非对角线位置绘制散点图,在对角线位置绘制单变量分布图(直方图或核密度估计图)。通过 sns.pairplot() 一行代码即可生成,开发者能够快速识别变量之间的相关性、发现聚类结构和异常值。配合 hue 参数按类别着色后,还能直观判断不同类别在特征空间中的分离程度,为后续选择分类或聚类算法提供依据。Penguins 数据集因其清晰的多分类结构,是练习配对图的理想素材。
五大数据集典型应用场景
简单总结各数据集的核心应用场景:
- Tips:学习分类可视化时的首选,常用于散点图、柱状图、箱线图等基础图表的练习。数据中丰富的分类变量使其特别适合练习 Seaborn 的
catplot()、boxplot()、violinplot()等分类绑图函数。 - Iris:机器学习聚类分析的经典数据集,深入学习时必定会用到。常见的应用包括 K-Means 聚类、KNN 分类、决策树分类等算法的入门实践。
- Penguins:多分类场景下的理想数据集,适合绑制配对图进行特征对比。作为 Iris 的现代替代,它在教学中越来越受欢迎。
- Titanic:生存分析的经典案例,数据包含乘客是否存活的标签,是分类任务的常用素材。该数据集因 Kaggle 平台上的入门竞赛「Titanic: Machine Learning from Disaster」而广为人知,这个竞赛被视为数据科学初学者的第一个实战项目。数据中包含缺失值(如年龄字段约有 20% 缺失)、分类变量和数值变量的混合,非常适合练习数据清洗、特征工程和二分类模型构建等核心技能。
- Diamonds:钻石价格相关数据,包含克拉数、切工、颜色、净度等特征,适合分布图和回归分析的练习。该数据集规模较大(约 54,000 条记录),也适合用来测试大数据量下的可视化性能。
小结
本文介绍了 Seaborn 五大常用内置数据集(Tips、Iris、Penguins、Titanic、Diamonds)的结构与加载方式。核心要点如下:
- 使用
sns.load_dataset()函数加载 Seaborn 内置数据集 - 通过
data_home参数指定本地数据路径,避免因网络问题导致加载失败 - 提前从 GitHub 仓库(seaborn-data)下载数据集到本地,确保学习过程中数据加载的稳定性
- 每个数据集都有其独特的数据结构和适用场景,建议根据学习目标选择合适的数据集进行练习
在接下来的学习中,我们会结合这些数据集,深入探索 Seaborn 的各种可视化功能,包括分布图(displot)、关系图(relplot)、分类图(catplot)等高级绑图接口。
相关推荐
 教程攻略
教程攻略Cursor+Codex双IDE协同:开源项目二开实战方法论
基于实战经验总结的开源项目二次开发完整方法论,详解Cursor+Codex双IDE协同工作流,涵盖二开七环节、MVP验证、AI读源码技巧,帮助开发者三天跑通项目、两周完成业务集成。
 教程攻略
教程攻略Cursor多Agent实战:50分钟搭建Next.js全栈博客
使用Cursor IDE多Agent协作模式,50分钟内从零搭建全栈博客。涵盖Next.js、Clerk认证、Supabase数据库集成,详解4个AI Agent分阶段开发流程与关键避坑经验。
 教程攻略
教程攻略从零搭建AI软件工厂:Cursor工程师的多Agent协作实战经验
Cursor工程师Eric分享AI软件工厂构建实战:从自动化六层级、护栏设计、并行Agent管理到规模化扩展,详解如何用多Agent协作实现7×24小时高效软件开发。