社交媒体洗稿泛滥:AI批量搬运推文,原创者如何自保?

AI工具使社交媒体文字内容搬运工业化,原创保护面临严峻挑战
Twitter等平台上出现大规模文字内容搬运现象,同一推文被10+账号复制发布。AI大语言模型和自动化脚本将洗稿成本降至接近零,形成工业化内容盗取体系。相比视频搬运,文字洗稿检测更难、改写更快,而平台因激励结构矛盾缺乏治理动力。原创者需通过建立个人品牌和信任关系构建护城河。
同一内容被10+账号反复搬运,洗稿已成常态
近日,有用户在Twitter上公开质疑:为什么短短几天内,超过10个不同账号发布了完全相同的内容?这种现象被形容为"文字版的视频搬运"——就像此前 @nikitabier 所揭露的视频内容被大规模盗用搬运一样,如今文字推文也正遭遇同样的命运。
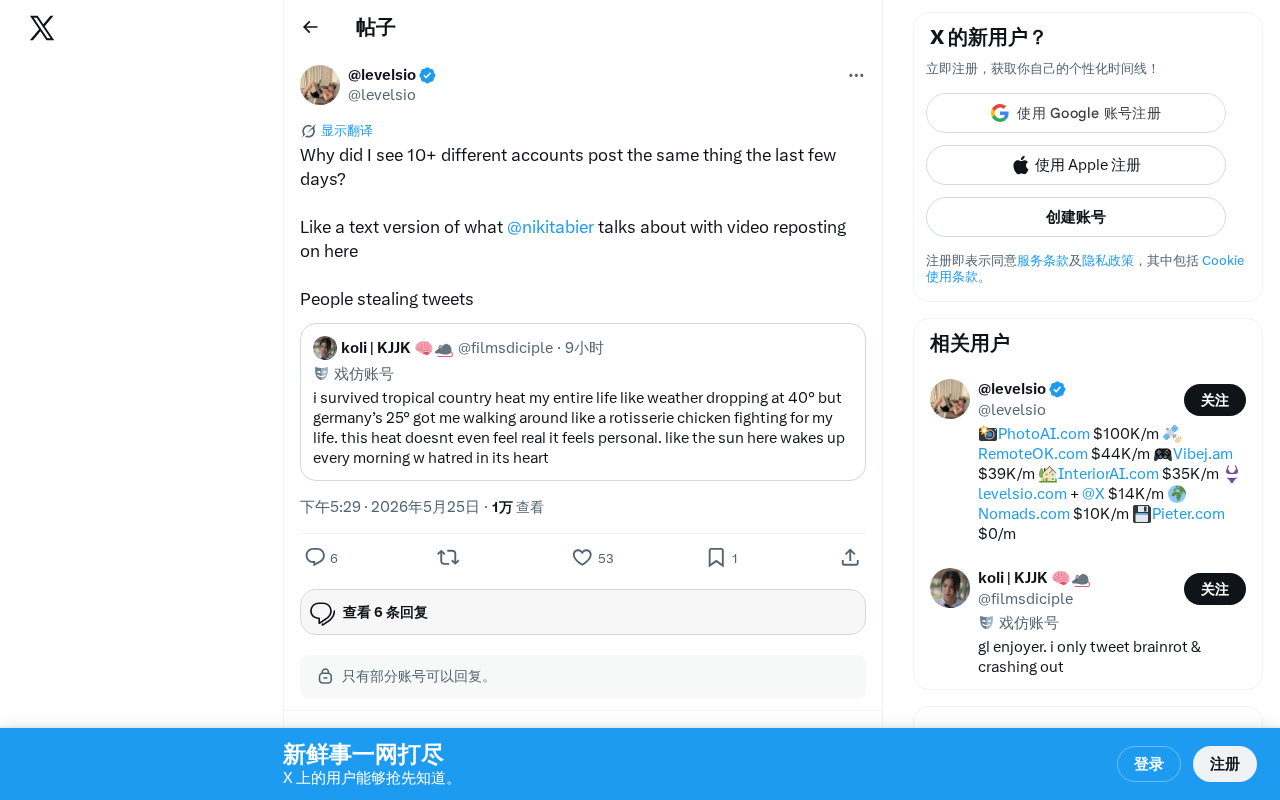
这并非个例。越来越多的用户发现,自己精心撰写的推文会在极短时间内被多个账号原封不动地复制粘贴,或者稍加改写后重新发布。这种"偷推文"(stealing tweets)的行为正在社交平台上愈演愈烈,已经从偶发事件演变为系统性的内容盗取问题。
流量经济与AI工具:洗稿泛滥的双重推手
流量变现催生灰色产业链
社交媒体平台的推荐算法天然偏爱高互动内容。值得注意的是,Twitter的For You算法、TikTok的推荐系统等主流推荐机制,本质上都是基于点赞率、转发率和停留时长等互动信号的排序系统,其核心设计目标是最大化用户参与度,而非验证内容的原创性。这意味着一条已被市场验证过的"爆款内容"被搬运后,依然能触发算法的正向反馈循环,形成所谓的"流量套利"——搬运者无需付出任何创作成本,就能坐享原创者验证过的流量红利。
这催生了一条完整的灰色产业链:
- 批量注册账号:通过自动化工具创建大量看似真实的账号
- 内容抓取与复制:实时监控热门推文,第一时间搬运
- 积累粉丝后变现:通过广告、带货或直接出售账号获利
AI让洗稿门槛降至为零
在AI工具普及之前,大规模搬运内容至少需要一定的人力成本。但现在,借助大语言模型(LLM,Large Language Model)和自动化脚本,一个人就能同时运营数十个账号——自动抓取热门内容、轻微改写以规避检测、定时发布——整个流程几乎可以全自动化完成。
大语言模型是基于Transformer架构、经过海量文本训练的生成式AI系统,代表产品包括GPT-4、Claude等。这类模型具备极强的文本改写能力——在保留原文语义的前提下,可以在秒级时间内完成同义替换、句式重组、语气调整等操作,使改写后的文本在表面上与原文差异显著,从而轻松规避基于余弦相似度或编辑距离的传统文本检测工具。结合Python等编程语言的自动化脚本,整个"抓取-改写-发布"流程可以实现无人值守的全自动化运行。
这意味着原创者面临的不再是个别抄袭者,而是一个工业化的内容盗取体系。当AI把洗稿成本压到接近零,内容搬运的规模和速度都在指数级增长。
从视频到文字:内容搬运问题全面升级
此前,视频内容的搬运问题已经引发广泛关注。Nikita Bier 等知名创业者多次公开讨论过,TikTok、Instagram Reels 等平台上存在大量视频被去水印后重新上传的现象。而如今,这一问题正在向文字领域全面蔓延。
与视频搬运相比,文字洗稿在检测和防范上难度更大:
| 对比维度 | 视频搬运 | 文字搬运 |
|---|---|---|
| 检测方式 | 画面指纹识别,技术相对成熟 | 短文本原创性验证极其困难 |
| 改写成本 | 需要剪辑、配音等操作 | AI几秒内即可换一套措辞 |
| 传播速度 | 受文件体积限制 | 体积小、发布快,分钟级完成复制 |
| 维权难度 | 有视觉证据可比对 | 改写后难以认定为抄袭 |
这一差距背后有深刻的技术原因。视频指纹技术(如YouTube的Content ID系统)通过提取音视频特征生成唯一哈希值,可实现毫秒级版权匹配,已相当成熟。而短文本(如推文)的信息熵低、特征空间有限,AI改写更会从根本上改变词向量分布,使传统哈希匹配完全失效。简单的文本比对工具在面对AI改写时几乎完全失效,这让文字内容的原创保护成为一个更加棘手的难题。
平台治理为何跟不上搬运速度?
现有审核机制的局限
目前主流社交平台的内容审核主要聚焦于违规内容(如仇恨言论、虚假信息等),对于"内容重复"或"原创性"的检测投入相对有限。Twitter/X 的举报机制虽然允许用户投诉抄袭,但处理效率远远跟不上搬运的速度——等到平台响应时,搬运内容往往已经收割完流量。
这种滞后并非单纯的技术问题,更折射出深层的激励结构矛盾。对广告驱动的社交平台而言,搬运内容同样能产生页面浏览量和广告曝光,平台在流量层面并不直接受损。建立完善的原创性检测系统需要巨大的工程投入,且可能因误判引发创作者投诉。这种"收益外部化、成本内部化"的结构性矛盾,是平台治理长期滞后的深层原因。与此同时,现行版权法对短文本的保护存在灰色地带,进一步削弱了平台主动治理的外部压力。
值得探索的解决方向
要从根本上遏制内容搬运,平台需要在多个层面同时发力:
- 内容指纹技术:为每条原创内容生成唯一标识,自动检测后续的复制和改写行为。学术界正在探索基于语义嵌入(Semantic Embedding)的相似度检测方案——将文本映射到高维向量空间后计算语义距离,即便经过AI改写也能识别内容同源性,但大规模实时部署的计算成本仍是挑战。
- 首发时间戳认证:建立可信的内容首发时间记录,为原创者提供明确的维权依据。区块链时间戳技术被部分研究者视为潜在的基础设施方案,可提供不可篡改的发布时序证明,但尚未在主流平台落地。
- 推荐算法干预:降低被识别为搬运内容的推荐权重,从流量分配端釜底抽薪
- 创作者监控工具:为原创者提供主动监控功能,及时发现和一键举报搬运行为
这些方案在技术上并非不可实现,关键在于平台是否有足够的动力去推动落地。
原创者如何在洗稿时代建立护城河
在平台治理尚未完善的当下,原创者不能坐等保护机制到位,而需要主动建立更强的个人品牌壁垒。
单纯依赖"好内容"已经不够,因为好内容会被瞬间复制。真正难以被搬运的是三样东西:持续输出的能力、独特的个人风格,以及与受众之间建立的信任关系。当读者认准的是"你这个人"而不仅仅是"你写的某条内容",搬运者即便复制了文字,也复制不走你的影响力。
这场内容搬运的军备竞赛,本质上反映了社交媒体生态中一个根本性矛盾:平台需要海量内容来维持用户活跃度,却缺乏足够的激励机制来保护内容的真正创造者。在AI进一步降低洗稿成本的趋势下,这个矛盾只会变得更加尖锐——而最终为此买单的,是每一个还在坚持原创的内容创作者。
核心要点
- Twitter上出现大规模文字内容搬运现象,同一推文被10+账号原封不动复制发布
- AI工具和自动化脚本将内容搬运门槛降至接近为零,形成工业化盗取体系
- 相比视频搬运,文字搬运检测难度更大、改写成本更低、传播速度更快
- 当前平台审核机制主要聚焦违规内容,对原创性检测投入不足,且存在深层激励结构矛盾
- 原创者需要通过建立个人品牌和持续输出能力来构建难以被搬运的护城河
相关推荐
 行业洞察
行业洞察AI产品开发实战:模型选择、护城河构建与商业化路径
分享AI产品开发的实战策略,包括为什么不应从头训练模型、如何选择API调用与微调时机、构建产品护城河的关键要素,以及从评测体系搭建到商业化落地的完整执行路径。
 行业洞察
行业洞察没有想要的产品?自己做才是独立开发者的最佳起点
市面上找不到满意的产品怎么办?从个人痛点出发,自己动手开发,正是独立开发者最好的切入方式。本文分析为什么小众需求反而是理想的创业起点,以及AI工具如何让一个人也能快速把想法变成产品。
 行业洞察
行业洞察OpenAI Codex教程遭批量搬运,AI内容农场现象引关注
B站上至少9个账号批量发布相同的OpenAI Codex教程视频,暴露AI工具教程领域的内容农场问题。本文分析批量搬运的典型特征,探讨平台治理挑战,并提供辨别原创内容的实用建议。