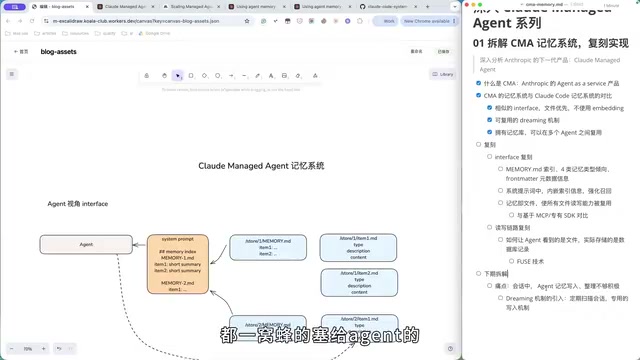
Claude云端Agent记忆系统架构深度拆解:CMA设计理念与技术选型
Anthropic 近期推出了野心勃勃的下一代产品——Cloud Managed Agents(CMA),将 Claude Code 从本地工具升级为云端托管的 Agent 服务。本文基于对 CMA 记忆系统的深度逆向分析,拆解其核心设计理念、技术选型以及与 Claude Code 记忆系统的关键差异。
什么是 Cloud Managed Agents?
CMA 本质上是 Anthropic 推出的 "Agent as a Service" 产品。与本地运行的 Claude Code 不同,CMA 将 Agent 完整托管在 Anthropic 的云基础设施上,使其更接近一种云服务形态。
Agent as a Service(AaaS)是继 SaaS、PaaS 之后新兴的云服务形态。传统的 AI API 服务(如 OpenAI API)提供的是单次推理能力,而 AaaS 则将完整的 Agent 生命周期——包括任务规划、工具调用、状态管理、错误恢复——全部托管在云端。这种模式的兴起源于企业级 Agent 部署面临的现实挑战:本地运行的 Agent 受限于单机算力、网络稳定性和运维成本,难以支撑需要长时间运行的复杂工作流。CMA 的推出标志着 Anthropic 从模型提供商向 Agent 平台运营商的战略转型。
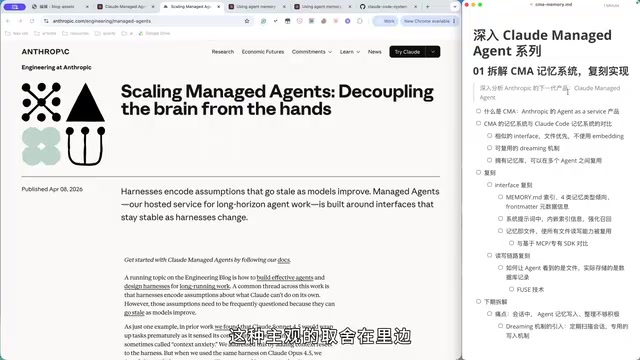
从架构层面看,CMA 的核心 Harness(即 Agent 运行引擎)依然是 Claude Code,但它将所有依赖的能力——Session 存储、外部编排、沙箱执行、工具调用、MCP 集成——全部外置给云平台。这与此前的 Remote Control 方案有本质区别:Remote Control 是远程控制一个运行在用户本地的 Claude Code,而 CMA 则是直接将 Claude Code 跑在 Anthropic 的云端。
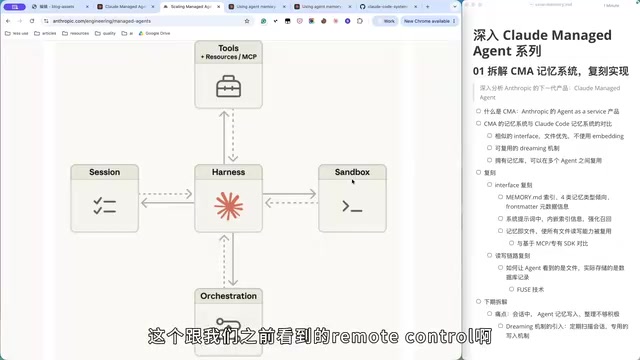
这种架构设计的核心价值在于支撑长时间运行的 Agent 任务。当 Agent 需要持续数小时甚至数天执行复杂编排时,本地运行的局限性就暴露无遗——网络断连、机器休眠、进程被杀都会导致任务中断——而云端托管则天然具备弹性扩展和高可用的能力。
CMA 与 Claude Code 记忆系统核心对比
共享的设计基因
CMA 和 Claude Code 的记忆系统在底层共享了大量设计,这源于它们共同的核心引擎——Claude Agent SDK。两者的关键共性包括:
文件优先,不使用 Embedding。 这是 Anthropic 在记忆方向上一直坚持的技术路线。它们始终没有引入向量层来做 RAG 或语义召回,而是充分发挥 Agent 对文件的理解能力。
要理解这一选择的深层逻辑,需要了解 Embedding 与 RAG 方案的现实痛点。Embedding 是将文本转换为高维向量表示的技术,是 RAG(Retrieval-Augmented Generation)系统的基础。典型的 RAG 流程是:将知识库文档切片后通过 Embedding 模型转为向量存入向量数据库(如 Pinecone、Milvus),查询时将用户问题同样向量化后进行相似度检索,再将检索结果作为上下文注入 LLM。这套方案的痛点包括:chunk 切分策略直接影响召回质量、Embedding 模型对专业术语的表达能力有限、向量相似度不等于语义相关性、索引更新存在延迟。此外,当上下文窗口从 4K 扩展到 200K 甚至更大时,直接将完整文件喂给模型的暴力方案在很多场景下已经"够用",RAG 的工程复杂度反而成为负担。
从实际效果来看,Anthropic 的这种选择确实规避了 Embedding 带来的额外复杂度和不稳定性——向量检索的召回质量往往受限于 Embedding 模型的表达能力,而直接操作文件则让 Agent 能够利用其强大的上下文理解能力进行更精准的信息提取。
共享 Dreaming 机制。 两者都复用了一套称为 "Dreaming" 的记忆整理机制(将在后续详细分析)。
关键差异:记忆库的跨Agent复用抽象
CMA 记忆系统最核心的差异在于引入了「记忆库」这一抽象层。Claude Code 的记忆直接存储在用户本地电脑上,而 CMA 的记忆库支持跨 Agent 复用。
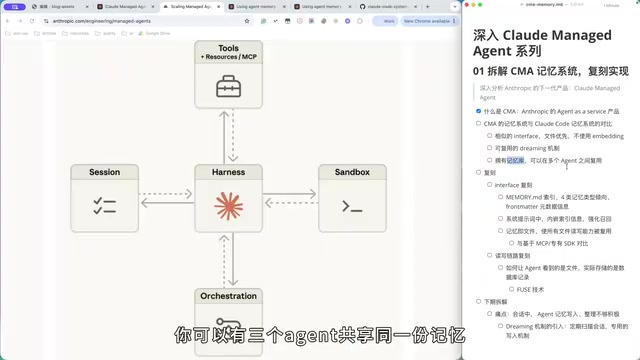
具体来说,你可以让三个云上 Agent 共享同一份记忆库,同时每个 Agent 还可以拥有各自独立的记忆。这种设计在实际场景中极具价值——比如一个负责代码审查的 Agent 和一个负责文档编写的 Agent 可以共享项目上下文记忆,但各自保留专属的工作偏好记忆。
为了实现这种复用能力,CMA 的数据链路与本地 Claude Code 有着根本性的不同。经过逆向分析,CMA 大概率采用了 FUSE(Filesystem in Userspace) 技术:记忆文件实际存储在数据库中,但 Agent 操作时看到的仍然是标准的文件系统接口。
FUSE 是一种允许非特权用户在用户空间创建自定义文件系统的技术框架,最早由 Linux 社区开发。传统文件系统运行在内核空间,修改和扩展需要编写内核模块,门槛极高。FUSE 通过在内核中提供一个通用的文件系统桥接模块,将文件操作请求转发到用户空间的守护进程处理。这意味着开发者可以用任何编程语言实现文件系统逻辑——比如将数据库查询伪装成文件读取,将网络存储映射为本地目录。在 CMA 的场景中,FUSE 使得 Agent 可以用标准的文件 I/O 操作(open、read、write)来访问实际存储在分布式数据库中的记忆数据,而无需修改 Agent 的核心代码逻辑。
这种设计既保持了"文件优先"的一致性,又实现了底层存储的灵活性和可共享性。
不用 Embedding 也不用 MCP:设计取舍的深层逻辑
Anthropic 在记忆系统上的技术选型体现了强烈的主观取舍。不使用 Embedding、不依赖 MCP 或专用 SDK,这些"不做"的决定背后有清晰的工程哲学:
降低系统复杂度。 Embedding 方案需要维护向量数据库、处理索引更新、调优召回参数,每一层都是潜在的故障点。而文件方案的链路极其简洁——读文件、写文件、理解文件内容,Agent 本身就是最好的"检索引擎"。
提升可调试性。 文件是人类可读的,开发者可以直接查看、编辑记忆内容,而向量空间中的信息则几乎不可解释。当 Agent 的行为出现异常时,开发者可以直接打开记忆文件检查其内容是否正确,这在生产环境的故障排查中价值巨大。相比之下,向量数据库中的高维向量对人类而言是完全不透明的黑箱。
充分利用模型能力。 随着上下文窗口的持续扩大(从早期的 4K 到如今的 200K)和模型理解能力的提升,让模型直接处理结构化文件的效果已经足够好,Embedding 的边际收益在递减。Anthropic 显然押注于模型能力的持续增长将进一步削弱 RAG 方案的必要性。
Agent 记忆写入积极性:核心痛点与 Dreaming 解法
无论是 CMA 还是其他 Agent 系统,记忆的读取可以通过提示词工程来优化——比如"当用户提及身份信息时,主动查询记忆"。但写入是一个更深层的难题。
当前 Agent 在长期对话中自发决定写入记忆的能力普遍不足。现实中,不管是前沿 Agent 还是开发者自建的简单 Agent,大多仍然依赖用户主动提示"帮我记住这个"。Agent 的自主记忆写入触发极不积极,而当记忆积累到一定量后,整理和去重同样缺乏主动性。
Agent 自主记忆写入是当前 AI Agent 领域公认的难题之一。问题的根源在于:模型需要在执行任务的同时判断"什么信息值得长期记住",这本身就是一个需要元认知能力的高阶决策。目前业界的主流方案包括:基于规则的触发(如检测到用户偏好表达时自动记录)、基于重要性评分的写入(如 Stanford 的 Generative Agents 论文中提出的 importance scoring 机制,通过让 LLM 对每条信息打 1-10 的重要性分数来决定是否写入长期记忆)、以及用户显式指令触发。但这些方案要么覆盖面不足,要么过度写入导致记忆膨胀。
为解决这一痛点,Anthropic 引入了 Dreaming 机制:系统会定期扫描对话历史,通过专有的写入流程对已有记忆进行全面整理。即使对话过程中没有及时触发记忆写入,只要对话数据仍然存在,Dreaming 就能事后补录。
Dreaming 机制的命名并非偶然,它直接借鉴了认知神经科学中关于睡眠与记忆巩固的研究。人类大脑在清醒时不断接收信息,但真正的记忆整合——包括短期记忆向长期记忆的转化、无关信息的遗忘、关联记忆的强化——主要发生在睡眠阶段,尤其是快速眼动(REM)睡眠期间。大脑会"重放"白天的经历,筛选出重要信息并将其编码到长期存储中。CMA 的 Dreaming 机制遵循了相同的范式:Agent 在"清醒"执行任务时专注于当前工作,而记忆的整理、去重、结构化则交给独立的异步流程在"离线"时完成。这种设计避免了实时记忆写入对任务执行的干扰,同时确保了记忆质量。
这本质上是将"实时记忆"降级为"异步记忆",用确定性的批处理替代不确定性的实时触发,是一个非常务实的工程方案。
总结:CMA 记忆架构的可迁移价值
CMA 的记忆系统设计体现了 Anthropic 一贯的工程风格:在关键技术选型上做出明确取舍(文件优先、无 Embedding),在产品能力上追求实用性(记忆库复用、Dreaming 机制),在架构上保持简洁可扩展(FUSE 抽象层)。
这套记忆系统的设计思路并不局限于 CMA 本身,其核心理念——文件优先的存储、按需读取的召回、异步批处理的写入整理——完全可以迁移到其他 Agent 框架中。对于正在构建 Agent 记忆系统的开发者而言,Anthropic 的这套方案提供了一个经过大规模验证的参考架构。
值得注意的是,这套架构的适用性与模型能力的发展紧密相关。随着上下文窗口继续扩大、模型推理能力持续增强,"文件优先"策略的优势只会更加明显。而 Dreaming 机制作为一种通用的异步记忆整理范式,其设计模式可以被任何 Agent 框架采用,无论底层使用何种存储方案。
相关推荐
Claude Code Skills技能机制详解:按需加载省Token又高效
深入解析Claude Code的Skills技能机制,通过按需加载替代全量灌输,大幅降低Token消耗并提升输出质量。涵盖Skill文件三层结构、技能生成器用法及经验模块化实操建议。

多智能体省钱指南:4个文档砍掉六到八成Token开销
多智能体系统账单失控?本文拆解Token成本两大痛点,提供需求判断、预算闸门、监控仪表盘、模型分级缓存4个落地文档,帮你把多智能体任务成本砍掉六到八成。
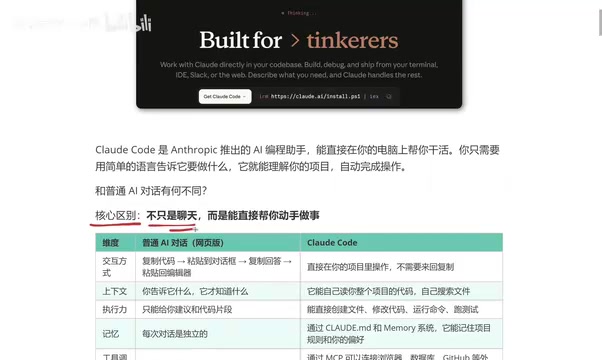
Claude Code是什么?与普通AI对话的五大核心区别
深入解析Claude Code与ChatGPT、DeepSeek等普通AI对话工具的五大核心区别,从交互方式、上下文理解、执行力、记忆能力到工具调用,全面了解这款AI编程助手的真正实力。