LangChain Agent Executor构建原理:从零实现ReAct智能体
深入剖析LangChain Agent Executor工作原理,手把手构建自定义Agent执行器
本文详解了LangChain中Agent Executor的核心机制,围绕ReAct(推理+行动+观察)迭代模式展开,介绍了Prompt设计、工具绑定、Tool Choice策略(推荐强制工具调用+Final Answer工具),并完整实现了自定义Agent Executor类,强调了最大迭代次数保护和并行工具调用中Tool Call ID的关键作用。
引言
在AI应用开发中,Agent(智能体)是一个核心概念。它不仅仅是一次简单的LLM调用,而是一套迭代运行LLM调用、处理输出并执行工具的代码逻辑。本文将深入剖析LangChain中Agent Executor的工作原理,并手把手构建一个自定义的Agent执行器,帮助你真正理解Agent背后的运作机制。
ReAct模式:Agent的核心思维框架
什么是ReAct?
ReAct是目前最主流的Agent设计模式之一,其名称来源于Reasoning(推理)+ Action(行动)的组合。这一模式源于2022年普林斯顿大学与谷歌研究院联合发表的论文《ReAct: Synergizing Reasoning and Acting in Language Models》。论文通过在HotpotQA、FEVER等多跳推理基准上的实验,证明了将推理轨迹(Reasoning Trace)与行动步骤(Action Step)交织在一起,能显著提升LLM在多步骤任务上的表现——相比单纯的Chain-of-Thought推理,ReAct在需要外部信息检索的任务上准确率提升了约10%~30%。更重要的是,这种"边想边做"的结构天然具备可解释性:每一步推理都有迹可循,调试时可以清晰定位Agent在哪个环节出现了判断偏差。尽管这个模式已经提出了几年,但包括OpenAI在内的几乎所有LLM厂商,其工具调用Agent都遵循着非常相似的模式。
ReAct的核心循环包含三个步骤:
- Reasoning(推理):LLM分析当前信息,决定下一步该做什么
- Action(行动):执行具体的工具调用
- Observation(观察):获取工具执行的结果
以一个具体例子来说明:假设用户问"除了Apple Remote,还有什么设备可以控制Apple Remote最初设计交互的程序?"LLM会先推理出需要搜索Apple Remote的相关信息,然后调用搜索工具,获得"Apple Remote用于控制Front Row媒体中心"的观察结果。接着进入第二轮循环,搜索Front Row,最终得出"键盘功能键"这个答案。
Agent Executor的角色定位
在整个ReAct循环中,Agent本身只负责推理和生成工具调用指令,而真正执行工具、处理响应、管理迭代循环的是Agent Executor。它的工作流程可以概括为:
- 将用户输入传给LLM
- 判断LLM的输出是最终答案还是工具调用
- 如果是工具调用,执行工具并将结果反馈给LLM
- 重复上述过程直到获得最终答案
说个细节,每次迭代都可能涉及多次LLM调用,这意味着Agent在延迟和token成本上都会高于单次LLM调用,但换来的是远超普通LLM的问题解决能力。
从零构建Agent:Prompt设计与工具绑定
定义Prompt模板
构建Agent的第一步是设计合理的Prompt模板。一个典型的Agent Prompt包含四个部分:
- System Message:定义Agent的行为规则,包括何时使用工具、何时直接回答
- Chat History:历史对话记录
- User Input:当前用户消息
- Agent Scratchpad:中间推理步骤,包括工具调用记录和观察结果
其中Agent Scratchpad是关键——LLM生成的工具调用会作为AI Message存储,而工具返回的结果则作为Tool Message存储,两者通过tool_call_id进行关联。
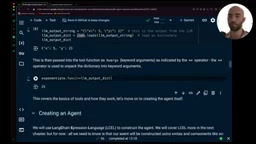
工具绑定与执行机制
LangChain通过@tool装饰器将普通Python函数转换为结构化工具对象,包含名称、描述和JSON Schema等元信息。这一机制的底层原理是:装饰器会自动解析Python函数的类型注解(Type Hints)和文档字符串(Docstring),并借助Pydantic模型将其转换为符合OpenAI Function Calling规范的JSON Schema格式。这意味着你编写的函数注释质量直接决定了LLM理解和调用工具的准确率——描述越精确、参数说明越清晰,LLM选择正确工具并传入合法参数的概率就越高。将工具绑定到LLM后,LLM就能生成包含工具名称和参数的结构化输出。
执行流程非常直观:从LLM的输出中提取工具名称和参数,通过名称映射找到对应的函数,然后用关键字参数执行该函数。
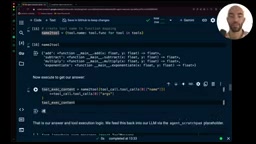
Tool Choice策略:两种终止方式的对比
方式一:Auto模式
设置tool_choice="auto"时,LLM可以自由选择使用工具或直接在content字段中回答用户。这种方式简单直观,但存在一个实际问题:LLM有时会在应该使用工具时选择直接回答,尤其是在使用较小模型时,这种"跳过工具"的行为会更加频繁。
方式二:强制工具调用 + Final Answer工具(推荐)
设置tool_choice="any"(等同于"required")会强制LLM每次都必须调用工具。为了让Agent能够输出最终答案,需要额外创建一个final_answer工具。
这种方式有两个显著优势:
- 更强的控制力:消除了LLM绕过工具直接回答的可能性,输出始终在tool_calls字段中,格式统一
- 结构化输出:可以在final_answer工具中定义精确的输出Schema,例如包含
answer字段和tools_used字段,确保下游逻辑能可靠地解析输出
这种结构化输出在实际生产环境中极其重要——当Agent的输出需要传递给前端展示或后续处理流程时,可预测的输出格式能大幅降低系统的脆弱性。
自定义Agent Executor类的完整实现
核心架构
将前面所有手动执行的步骤封装到一个CustomAgentExecutor类中,核心逻辑如下:
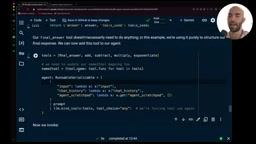
class CustomAgentExecutor:
def __init__(self, llm, tools, prompt, max_iterations=3):
self.chat_history = []
self.max_iterations = max_iterations
# 初始化agent和工具映射
def invoke(self, input: str):
count = 0
while count < self.max_iterations:
# 1. 调用agent生成工具调用
# 2. 执行工具,获取观察结果
# 3. 将结果添加到scratchpad
# 4. 如果是final_answer,提取答案并返回
count += 1
关键设计要点
最大迭代次数保护:这是一个容易被忽视但至关重要的安全机制。如果Agent的逻辑出现问题(比如观察结果没有正确反馈给LLM),Agent可能会无限循环调用LLM,导致高昂的API费用。设置max_iterations可以有效防止这种情况。
Tool Call ID的重要性:每个工具调用都有唯一的ID,工具返回结果时必须携带对应的ID。这在并行工具调用场景中尤为关键。OpenAI从GPT-4 Turbo版本开始引入了并行函数调用(Parallel Function Calling)能力,允许模型在单次响应中的tool_calls数组里同时生成多个调用指令。这一特性可以将多个独立查询的总延迟从"串行叠加"压缩为"并行执行",在需要同时查询多个数据源的场景下效果尤为显著。然而,并行执行意味着各工具的返回顺序不再确定,tool_call_id就成了唯一可靠的关联锚点——LLM依赖它将每条观察结果精确匹配回对应的调用请求,从而保证推理上下文的完整性。
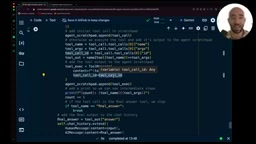
并行调用的处理:OpenAI的模型支持在一次响应中生成多个并行工具调用。在简单场景下可以假设每次只有一个工具调用(通过索引[0]获取),但在生产环境中,需要添加额外逻辑来处理并行调用的情况。
总结与实践建议
通过手动构建Agent Executor,我们可以清晰地看到:Agent的核心并不神秘,它本质上是一个围绕LLM调用的迭代控制循环。理解这一点后,你可以根据具体业务需求灵活定制Agent的行为逻辑。
几点实践建议:
- 优先使用强制工具调用 + Final Answer工具的模式,获得更可控的输出
- 始终设置最大迭代次数,防止意外的无限循环
- 在生产环境中处理并行工具调用,不要假设每次只有一个工具调用
- 先理解底层原理,再使用LangChain的抽象封装,这样在遇到问题时才能快速定位和解决
虽然LangChain提供了高度抽象的AgentExecutor可以直接使用,但深入理解其内部机制,能让你在构建更复杂、更贴合业务场景的Agent系统时游刃有余。
核心要点
- ReAct模式是Agent的核心框架,源于2022年学术论文,通过Reasoning(推理)→ Action(行动)→ Observation(观察)的迭代循环来解决复杂问题
- Agent Executor是控制整个迭代流程的代码逻辑,负责执行工具、处理响应并管理循环,与Agent本身(负责推理和生成指令)职责分离
- 推荐使用强制工具调用(tool_choice=any)配合Final Answer工具的模式,相比auto模式能获得更强的输出控制力和结构化输出能力
- 构建Agent Executor时必须设置最大迭代次数保护机制,防止逻辑错误导致的无限循环和高额API费用
- Tool Call ID在并行工具调用场景中至关重要,是关联工具调用请求与返回结果的唯一可靠方式
相关推荐
 教程攻略
教程攻略Cursor+Codex双IDE协同:开源项目二开实战方法论
基于实战经验总结的开源项目二次开发完整方法论,详解Cursor+Codex双IDE协同工作流,涵盖二开七环节、MVP验证、AI读源码技巧,帮助开发者三天跑通项目、两周完成业务集成。
 教程攻略
教程攻略Cursor多Agent实战:50分钟搭建Next.js全栈博客
使用Cursor IDE多Agent协作模式,50分钟内从零搭建全栈博客。涵盖Next.js、Clerk认证、Supabase数据库集成,详解4个AI Agent分阶段开发流程与关键避坑经验。
 教程攻略
教程攻略从零搭建AI软件工厂:Cursor工程师的多Agent协作实战经验
Cursor工程师Eric分享AI软件工厂构建实战:从自动化六层级、护栏设计、并行Agent管理到规模化扩展,详解如何用多Agent协作实现7×24小时高效软件开发。