Gemini 2.5 Pro 0605实测对比o3与Claude Opus 4:编程、推理、写作全维度评测

Gemini 2.5 Pro 0605多维度横评:编程可视化强,推理写作仍逊于竞品
Google新发布的Gemini 2.5 Pro 0605在前端代码生成和可视化效果方面提升显著,但逻辑推理严谨性不及o3(倾向强行给出确定答案),创意写作文学性也有差距。实际工程开发中存在知识库滞后和稳定性问题,需多模型协作。其价格优势明显,适合预算敏感的开发者。当前AI竞争格局是"没有全能冠军,只有场景之王"。
文章正文
Google 最新发布了 Gemini 2.5 Pro 0605 版本,官方宣称在推理、科学问题和编程等多个基准上均表现优异。本文通过代码生成、逻辑推理、创意写作和实际应用开发等多个维度,对新版 Gemini 2.5 Pro 与 OpenAI o3、Claude Opus 4 等模型进行了详细的横向对比测试。
编程能力:可视化效果显著提升
新版 Gemini 2.5 Pro 在编程方面的提升是最直观的。Google 特别强调了该模型在 Web Dev Arena 上的高分表现——这个由 LMSYS(Large Model Systems Organization)推出的专项评测平台采用「盲测对战」机制:用户提交前端开发需求后,平台同时调用两个匿名模型生成界面,用户仅凭视觉效果投票,最终通过 Elo 评分体系排名。这种方式规避了用户对模型品牌的主观偏好,被认为比传统静态基准更能反映真实的用户体验价值。前端代码生成能力的评估之所以复杂,在于它不仅考验语法正确性,还涉及 CSS 布局精度、动画曲线计算、WebGL/Canvas 渲染逻辑以及跨浏览器兼容性等多个维度。

在多个可视化编程测试中,新版 Gemini 表现出色:
- 24小时圆环时钟(SVG):新版比旧版效果更精细,外圈白昼、内圈夜间渐变深蓝的呈现更加美观
- 3D门格海绵(P5.js):支持点击增加细节、滚轮缩放,内部渐变效果出色。P5.js 和 Three.js 分别代表 2D 创意编程和 3D 图形渲染两个不同技术栈,模型需要理解底层图形学原理才能生成高质量的交互效果
- 无限星际穿梭:鼠标交互响应灵敏,点击可生成超新星,整体效果优于 o3 的生成结果
- 抓娃娃机(Three.js):新版比旧版改进明显,推杆仿真度高,对比千问3 235B 和 Claude 3.5 Haiku 的简陋输出优势巨大
不过在 SWE-Bench 上,Claude Opus 4 的得分仍然最高,新版 Gemini 2.5 Pro 与 o3 非常接近。SWE-Bench(Software Engineering Benchmark)由普林斯顿大学研究团队发布,从 GitHub 上收集真实的 Issue 报告和对应的 Pull Request 修复补丁,要求模型在给定代码仓库上下文的情况下自动定位 Bug 并生成可通过测试的修复代码——与「写一个排序算法」类的玩具题不同,它要求模型具备跨文件理解、依赖追踪、测试驱动开发等工程化能力,被认为是衡量模型「能否真正替代初级工程师」的黄金标准。在克隆 Vercel 界面的测试中,Opus 4 做出的效果也明显优于 Gemini,内容更丰富、更接近真实产品。
逻辑推理能力:Gemini仍有明显短板
在一道关于三个创业团队竞争项目资金的逻辑推理题中,两个模型给出了截然不同的回答。
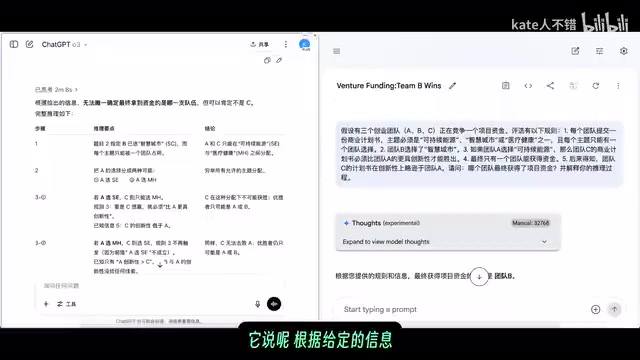
o3 思考了两分钟后,给出了较为严谨的分析:根据给定信息无法唯一确定最终获得资金的队伍,但可以排除 C 队。它将 A 队的选择分成两种可能性,最终结论是「仅靠题干内容只能排除 C,无法断言是 A 还是 B」。这种「承认不确定性」的能力在 AI 安全领域被称为「校准性」(Calibration),即模型的置信度应与其实际正确率相匹配。o3 属于「推理模型」(Reasoning Model)系列,其核心特征是在生成最终答案前会进行大量内部「思维链」计算,因此在面对信息不完整的逻辑题时,更容易识别出「条件不充分」的情况并如实报告。
Gemini 2.5 Pro 则认为这是一个逻辑谜题,「必然有一个唯一确定的答案」。在无法确定 A 或 C 会赢的情况下,它将团队 B 定义为「逻辑风暴的局外人」,因此认为 B 获得资金。这个推理过程存在明显的逻辑跳跃,说服力不足。这种「过度自信」(Overconfidence)是当前大模型的普遍问题——模型在训练中受到「给出明确答案」的奖励信号影响,有时会牺牲准确性来满足「看起来有用」的表象。
从这道题来看,Gemini 在逻辑推理的严谨性上相比 o3 仍有不小差距。o3 能够诚实地承认信息不足以得出唯一结论,而 Gemini 则倾向于强行给出一个「确定」答案。
创意写作对比:o3的文学性更胜一筹
写作测试的题目是围绕「孤独的灯塔看守人与小猫之间的友谊」展开故事,要求呈现两种不同风格。
o3 的表现更具文学性和诗意。例如「小猫眨着琥珀色的大眼睛」「阿光教小猫数星星,小猫教阿光听贝壳唱歌」,画面感十足。哥特风格中「倘若连大海都要将这脆弱生命托付给他,那么这座灯塔究竟意欲让他守护,还是让他审判」这样的句子极具张力。
Gemini 的故事相对平铺直叙——灯塔看守人发现木箱、打开看到小猫,叙事结构较为简单。虽然第二种风格中也有「我是这只眼睛的看守,也是他唯一的囚徒」这样有意思的表达,但整体文学性和情感深度不及 o3。
信息检索与表格处理能力
在「如何快速了解一项全新小众生物技术」的信息检索策略题中,两个模型各有特色。
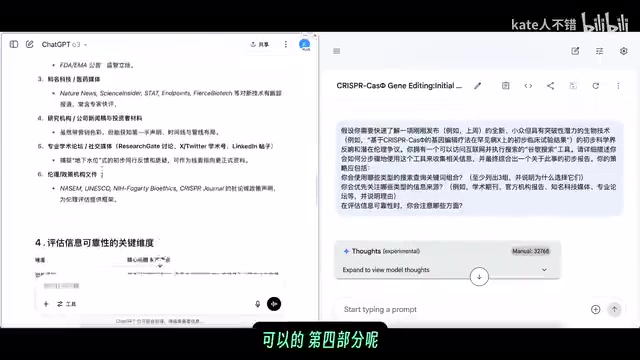
o3 的回复采用了清晰的表格式结构,分为五个步骤:明确信息需求、设计搜索组合词、优先信息来源排序、评估信息可靠性维度、整合报告。这种结构化输出非常适合实际操作。
Gemini 的回复同样有条理,包含定位、收集初步反响、探索伦理争议、综合报告等步骤,还给出了具体的搜索关键词组合和同行评议期刊关注建议。
在表格识别方面,新版 Gemini 的表现令人满意,比对后基本没有出错。而 o3 在 ChatGPT 中调用了 Python 工具处理表格,过程复杂且耗时较长,最终还出现了一些理解错误(如将 Gemini 2 Flash 的横杠标记错误识别)。
实际应用开发测试:多模型协作才是最优解
在开发一个基于 React Router v7 的 3D 虚拟展厅应用时,测试暴露了 Gemini 2.5 Pro 的一些实际问题。
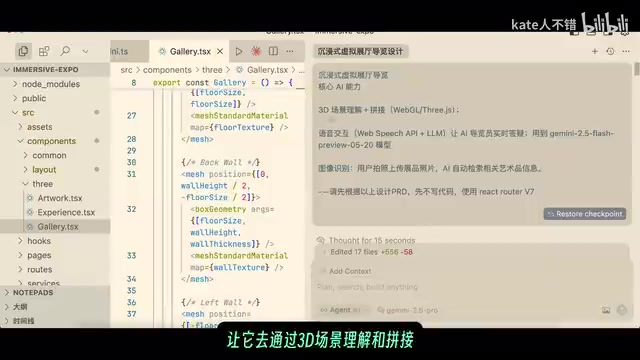
Gemini 遇到的问题:
- 错误地认为 React Router v7 处于 alpha 版本(知识库更新不及时)
- 在长对话中遗忘了之前的提示要求
- 运行中出现大量错误,多次修改后仍建议重装 Node
- 缺少 API key 时首页直接无法打开
React Router v7 于 2024 年底正式发布,是 Remix 框架与 React Router 深度整合后的重大版本。Gemini 将其误判为「alpha 版本」,暴露了大模型训练数据截止日期(Knowledge Cutoff)带来的系统性风险——大多数主流模型的训练数据截止于 2024 年初至中期,对于快速迭代的前端生态而言,这种滞后可能导致模型给出过时甚至错误的技术建议。在实际工程开发中,开发者通常需要在提示词中明确注明框架版本,或通过 RAG(检索增强生成)技术将最新文档注入上下文,以弥补模型知识库的时效性缺陷。
最终不得不让 Claude Sonnet 4 接手,后者在处理终端错误、安装依赖、解决版本冲突等方面表现更为稳定,经过几轮修改后成功完成了应用部署。
这说明在实际工程开发中,单一模型往往难以完美完成复杂任务,多模型协作可能是当前最务实的策略。「多模型协作」(Multi-Model Orchestration)正在成为 AI 工程实践的主流范式,催生了 LangChain、LlamaIndex 等编排框架,以及 Cursor、Windsurf 等将多模型调度内置于 IDE 的开发工具。从架构角度看,不同模型在「规划-执行-验证」流程中各有优势:推理模型(如 o3)适合任务分解和逻辑验证,代码专项模型(如 Claude Sonnet 系列)适合具体实现和调试,而成本较低的模型则适合处理重复性的格式转换任务。
性价比优势:预算敏感开发者的优选
说个细节,新版 Gemini 2.5 Pro 的定价与旧版保持一致,相比 o3 和 Claude Opus 4 有明显的价格优势。对于预算敏感的开发者来说,Gemini 2.5 Pro 在编程可视化、表格处理等场景下已经能够提供相当不错的体验,是一个极具竞争力的选择。
总结:没有全能冠军,只有场景之王
新版 Gemini 2.5 Pro 0605 在前端代码生成和可视化效果方面进步显著,尤其在 Web Dev Arena 类场景中表现亮眼。但在逻辑推理的严谨性上不及 o3,创意写作的文学性也有差距,实际工程开发中的稳定性仍需提升。
当前 AI 模型的竞争格局愈发清晰:没有全能冠军,只有场景之王。Anthropic、Google 和 OpenAI 也分别推出了各自的 Agent 框架(Claude Computer Use、Gemini Function Calling、OpenAI Assistants API),本质上都是在系统层面实现多模型或多工具的协同调度。这种格局正在推动整个行业从「选最好的模型」转向「设计最优的模型组合策略」——选择合适的模型组合,才是提升效率的关键。
核心要点
- Gemini 2.5 Pro 0605 在前端代码生成和可视化效果方面提升显著,3D 场景、交互动画等表现优于旧版和部分竞品
- 逻辑推理能力仍是短板,面对复杂推理题时倾向于强行给出确定答案,严谨性不及 o3
- 创意写作方面 o3 的文学性和情感深度更胜一筹,Gemini 的叙事相对平铺直叙
- 实际工程开发中 Gemini 存在知识库滞后、长对话遗忘、调试不稳定等问题,需要与 Claude 等模型协作完成
- 价格与旧版持平,相比 o3 和 Claude Opus 4 有明显成本优势,性价比突出
相关推荐
 产品体验
产品体验Qoder vs Cursor实测对比:同样20美金谁更强?
实测对比Qoder和Cursor两款AI IDE,从Agent自主修复能力、人工沟通次数、架构决策等维度评测。Qoder仅需2次沟通完成任务,Cursor需8次。详细分析两者差异,帮你选择最适合的AI编程工具。
 产品体验
产品体验Cursor云Agent演示:打通软件开发全链路瓶颈
深度解析Cursor云Agent最新Demo,展示如何通过云端虚拟机、自动测试产物和全链路控制平面,系统性消除软件开发生命周期中的人类瓶颈,让Agent自主运行、人按需介入。
 产品体验
产品体验Cursor 3.0深度解析:多Agent并行、Design Mode与Best-of-N模型对比
Cursor 3.0正式发布,从AI辅助编程工具进化为Agent舰队指挥中心。本文详解多智能体并行、Design Mode可视化编辑、Best-of-N多模型择优等核心功能,解读AI编程新范式。