实测GPT-Image-2:一句话出图效果炸裂,设计师该何去何从?
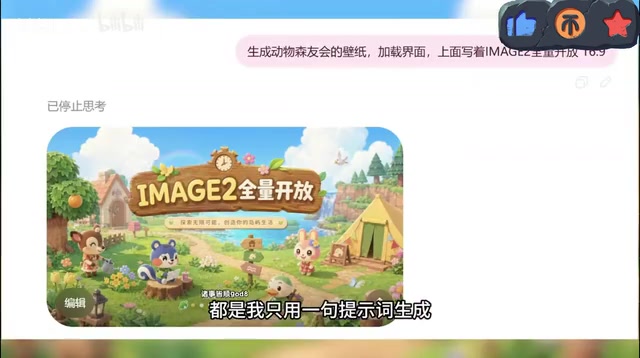
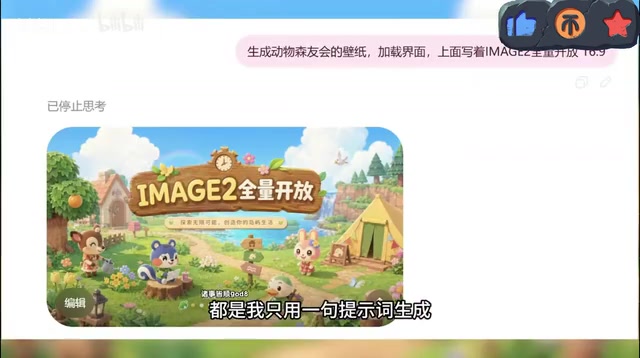
GPT-Image-2以一句提示词生成专业级图像,重新定义AI图像生成边界。
OpenAI发布的GPT-Image-2模型将AI图像生成门槛降至最低,用户仅需一句自然语言即可生成商业海报、真人人像、Logo、漫画等专业级图像。其审美水平媲美专业设计师,真人人像更是以假乱真,引发"有图为证"时代终结的担忧。该模型对设计行业执行层工作构成直接冲击,但高阶创意工作仍需人类主导。
OpenAI最新发布的GPT-Image-2模型,正在以一种令人震撼的方式重新定义AI图像生成的边界。一句提示词,就能生成媲美专业设计师水准的作品——从商业海报到真人人像,从品牌Logo到日系穿搭手册,几乎无所不能。本文基于实际测试,带你看看这个模型究竟强在哪里。
GPT-Image-2一句话出图:提示词门槛降到最低
过去使用AI生图工具,用户往往需要精心编写冗长的提示词,反复调试参数,才能获得一张勉强满意的图片。所谓的"提示词工程"(Prompt Engineering)曾是AI图像生成领域的核心技能——在Midjourney、Stable Diffusion等早期工具中,用户需要掌握特定的语法结构,例如使用权重标记(如"masterpiece:1.5")、负面提示词(Negative Prompt)排除不想要的元素,甚至需要指定采样器(Sampler)和CFG Scale等技术参数。一个成熟的提示词往往长达数百个英文单词,涵盖主体描述、风格参考、光照条件、镜头参数等多个维度。
但GPT-Image-2彻底改变了这一局面。其核心在于底层架构融合了大语言模型的语义理解能力,模型能够自动将用户的自然语言描述"翻译"为精确的视觉生成指令,省去了人工编写复杂提示词的过程。
测试中,仅用一句简短的中文描述,就成功生成了"马斯克和库克打PK"的对比海报、手机品牌官网页面等高质量图像。模型对用户意图的理解能力极强,不需要你像写论文一样描述画面的每一个细节,它就能准确捕捉你想要的效果。
这意味着AI图像生成的使用门槛被大幅拉低。过去需要花时间学习提示词工程的技巧,现在只需要像跟人说话一样描述需求就行。
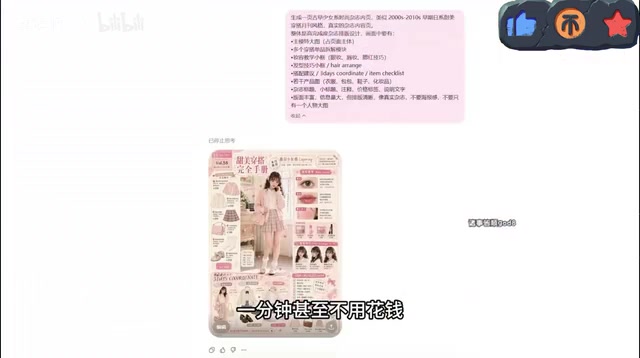
审美在线:日系穿搭手册惊艳全场
不少人对AI生图的刻板印象是"能用但不好看",审美水平始终是短板。GPT-Image-2在这方面的表现却让人刮目相看。
AI模型的"审美"本质上来源于训练数据的质量和多样性。早期的图像生成模型(如GAN架构的StyleGAN系列)虽然能生成逼真的图像,但在构图、配色、版式等设计维度上缺乏系统性理解。GPT-Image-2的审美突破,很可能得益于OpenAI在训练数据中纳入了大量经过专业策展的设计作品、摄影作品和排版案例,并通过RLHF(基于人类反馈的强化学习)等技术让模型学习人类对"美"的偏好。此外,多模态架构使模型能够同时理解文字与视觉的对应关系,从而在生成时自动遵循设计原则——如三分法构图、互补色搭配、视觉层次分明等专业规范。
测试者尝试生成了一本日系穿搭手册风格的图像,仅凭一句提示词,模型就输出了排版精致、色调和谐、极具翻阅欲望的设计稿。从配色方案到版式布局,从字体选择到留白处理,每一个细节都透着专业设计师的审美水准。

要知道,如果用传统方式(测试者戏称为"古法创作")来制作同等质量的图片,一个设计师需要经历找素材、贴图、修细节、排版等多个环节,没有几百块钱的人工成本根本下不来。而现在,一句话、一分钟,成本几乎为零。
AI生成真人人像以假乱真:"有图为证"时代正在终结
如果说设计类图片的突破还在意料之中,那么GPT-Image-2在真人人像方面的表现则真正让人感到不安。
测试中生成了一个女生的照片,以及她"被采访的综艺片段"截图。测试者坦言,自己使用AI生图工具已经三年,但面对这些图片,依然无法判断是否为AI生成。皮肤纹理、光影关系、面部微表情,每一个细节都趋近真实。

这意味着一个严峻的现实:"有图为证"的时代正在彻底终结。 当AI生成的人像照片连专业用户都无法辨别真伪时,图片作为证据的可信度将面临前所未有的挑战。虚假新闻、身份伪造、网络诈骗等深度伪造问题可能因此进一步加剧。
深度伪造(Deepfake)技术自2017年首次引发公众关注以来,已经从粗糙的换脸视频发展到如今几乎无法辨别的静态图像生成。GPT-Image-2在真人人像方面的突破,将这一问题推向了新的高度。目前全球范围内,针对深度伪造的治理手段主要包括三个方向:一是技术检测,如微软的Video Authenticator、Adobe的Content Authenticity Initiative(CAI)等工具通过分析像素级特征识别AI生成内容;二是标准制定,C2PA(内容来源与真实性联盟)正在推动为数字内容嵌入不可篡改的来源元数据;三是法律监管,欧盟《AI法案》已将深度伪造列为高风险应用,要求生成内容必须明确标注为AI生成。然而,技术迭代速度远超监管步伐,这场"矛与盾"的博弈仍在持续。
全能型AI设计助手:插画、Logo、漫画、表情包一网打尽
除了上述场景,GPT-Image-2还展现了惊人的多场景适应能力:
- 商业插画生成:一句话即可输出风格统一、细节丰富的插画作品
- 品牌Logo设计:快速生成标识方案,构图简洁、辨识度高
- 漫画创作:自动理解叙事逻辑,生成分镜感十足的漫画画面
- 表情包制作:精准捕捉情绪表达,生成自带传播力的表情包
每一个类别都只需一句提示词,模型就能自动匹配对应的视觉风格和设计规范。这种"全能型"的表现,意味着它不仅仅是一个图像生成工具,更像是一个内置了海量设计知识的AI设计助手。
虽然OpenAI尚未公开GPT-Image-2的完整技术细节,但从其表现推测,该模型很可能采用了原生多模态(Natively Multimodal)架构,即文本理解和图像生成共享同一个Transformer骨干网络,而非早期DALL·E系列将文本编码器和图像解码器分离的设计。这种架构的优势在于模型能够在统一的表征空间中处理语言和视觉信息,从而实现更精准的语义-视觉对齐。从行业竞争格局来看,GPT-Image-2的发布直接对标Google的Imagen 3、Midjourney V6以及Stability AI的Stable Diffusion 3等产品。但其最大的差异化优势在于与ChatGPT生态的深度整合——用户可以在对话中迭代修改图像,实现真正的"对话式设计"工作流。
GPT-Image-2对设计行业意味着什么?
面对GPT-Image-2的能力,一个不可回避的问题浮出水面:设计师的价值在哪里?
测试者在生成手机官网页面后发出感慨:"我们设计师除了给它改改字,还能做什么呢?"这虽然带有调侃成分,但确实反映了行业普遍存在的焦虑。
事实上,设计行业面临技术性变革并非首次。回顾历史,1980年代桌面出版(DTP)革命中,PageMaker和QuarkXPress的出现让传统排版工人大量失业;2000年代,Canva等在线设计工具的兴起让非专业人士也能制作基础设计物料,挤压了初级设计师的生存空间。每一次技术变革都遵循类似的规律:低技能的执行性工作被自动化取代,而高层次的创意策略和品牌思维反而更加稀缺。当前AI对设计行业的冲击本质上是这一趋势的加速——据麦肯锡2024年的报告,约60%的设计类岗位中有30%以上的工作内容可以被生成式AI自动化,但涉及用户研究、品牌战略和跨媒介创意整合的高阶工作,AI的替代率不足5%。
客观来看,GPT-Image-2目前最大的冲击对象是执行层面的设计工作——那些以素材拼贴、基础排版、简单修图为主的任务,正在被AI以极低的成本和极高的效率取代。但在品牌策略、用户体验设计、创意方向把控等需要深度思考的领域,人类设计师的价值仍然不可替代。
真正的变化或许是:设计师的角色将从"执行者"转变为"审核者"和"创意指挥者"。未来的设计工作流很可能是——AI负责快速生成大量方案,人类负责筛选、优化和最终决策。
写在最后
GPT-Image-2的出现,标志着AI图像生成正式进入"一句话时代"。它不仅在技术层面实现了质的飞跃,更在实际应用中展现了颠覆性的生产力。但另一边,它也带来了深刻的社会问题——当任何人都能轻松生成以假乱真的图片时,我们该如何重建对视觉信息的信任?这个问题,或许比技术本身更值得深思。
相关推荐
 产品体验
产品体验Qoder vs Cursor实测对比:同样20美金谁更强?
实测对比Qoder和Cursor两款AI IDE,从Agent自主修复能力、人工沟通次数、架构决策等维度评测。Qoder仅需2次沟通完成任务,Cursor需8次。详细分析两者差异,帮你选择最适合的AI编程工具。
 产品体验
产品体验Cursor云Agent演示:打通软件开发全链路瓶颈
深度解析Cursor云Agent最新Demo,展示如何通过云端虚拟机、自动测试产物和全链路控制平面,系统性消除软件开发生命周期中的人类瓶颈,让Agent自主运行、人按需介入。
 产品体验
产品体验Cursor 3.0深度解析:多Agent并行、Design Mode与Best-of-N模型对比
Cursor 3.0正式发布,从AI辅助编程工具进化为Agent舰队指挥中心。本文详解多智能体并行、Design Mode可视化编辑、Best-of-N多模型择优等核心功能,解读AI编程新范式。