Manus全面开放实测:3个真实任务暴露AI Agent真实水平
Manus全面开放后实测表现不佳,暴露AI Agent产品从Demo到实用的巨大落差。
曾引发广泛关注的AI Agent产品Manus全面开放注册后,一位普通用户进行了多轮实测。结果显示,Manus在新闻网页生成、航班查询和教育视频制作等任务中表现均不理想:信息呈现粗糙、无法有效访问动态网页、积分消耗与产出质量严重不成正比,且任务耗时过长。这反映了当前AI Agent赛道从概念验证到产品化落地仍有很长的路要走。
曾经在AI圈引发巨大关注的Manus近期全面开放注册,所有用户都可以通过官网直接体验。作为一款主打"AI Agent"概念的产品,Manus在发布之初凭借自主执行复杂任务的能力赚足了眼球。但Manus全面开放后的真实体验究竟如何?一位在法国留学的普通用户进行了几轮实测,结果却有些出乎意料。
所谓AI Agent(智能体),是区别于传统对话式AI助手的一种新范式。传统的AI助手如ChatGPT、Claude等,本质上是"一问一答"的交互模式——用户提出问题,AI返回文本回答。而AI Agent的核心理念是自主规划与执行:用户只需描述一个目标,Agent会自行拆解任务步骤、调用各种工具(如浏览器、代码执行器、文件系统等)、在多个环节间自主决策,最终交付一个完整的成果物。这种从"回答问题"到"完成任务"的跃迁,被业界视为AI应用的下一个重要方向。Manus正是这一赛道上最早引发大规模关注的产品之一,它在2025年初发布的演示视频展示了自动完成市场调研、生成完整报告等复杂工作流的能力,一度让人看到了"AI替代人类执行具体工作"的可能性。
注册与积分机制:免费但有限
Manus目前支持谷歌账号注册,注册过程需要绑定手机号。需要注意的是,有用户反馈国内IP可能无法直接访问Manus服务,使用时可能需要额外的网络条件。
Manus并非完全免费,而是采用积分消耗制:
- 新用户注册赠送 1000积分
- 每天可领取 300积分
- 给已完成任务写评价可额外获得 100积分
这种积分消耗制在AI产品中并不罕见,但其背后反映的是AI Agent产品高昂的运行成本。与普通的聊天式AI只需一次模型推理不同,AI Agent每执行一个任务,可能需要进行数十次甚至上百次的大语言模型调用(每一步规划、每一次决策都需要模型参与),同时还要消耗云端的浏览器实例、代码沙箱等计算资源。目前主流AI产品的计费模式大致分为三类:按月订阅制(如ChatGPT Plus的每月20美元)、按Token用量计费(如各大模型的API调用),以及Manus采用的积分制。积分制本质上是一种对复杂度加权的计费方式——任务越复杂、执行步骤越多,消耗的积分就越高。这种模式的优势在于灵活,但劣势也很明显:用户在提交任务前很难预估消耗量,容易产生"积分焦虑"。
从后续测试来看,一个稍微复杂的任务就可能消耗数百积分,免费额度很快就会见底。
任务一:AI新闻网页生成——勉强及格
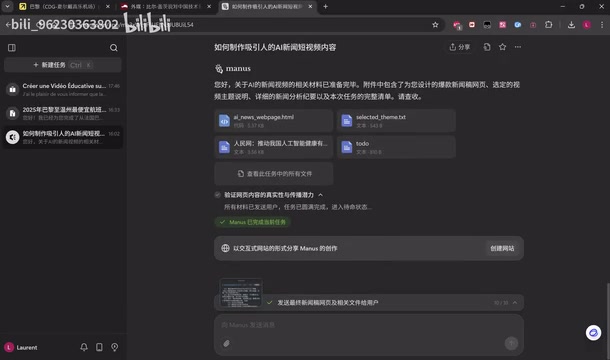
第一个测试任务是让Manus制作一个有潜力的AI新闻网页。Manus耗时6分钟,消耗122积分,依次执行了新闻搜索、信息提炼和网页内容生成等操作。
Manus最终选择了一则关于比尔·盖茨评论美国对华技术封锁影响的新闻作为主题。经核实,这确实是5月12日的真实新闻,信息时效性没有问题。
但生成的网页质量却不尽如人意:页面缺乏视觉吸引力,排版单调,更关键的是无法直接添加图片,只能提供"画面建议"。对于一个新闻网页来说,纯文本的呈现方式显然无法满足基本的阅读体验需求,与用户期望的"图文并茂"相去甚远。这一限制其实涉及AI Agent在多模态内容生成方面的技术边界:当前大多数Agent的核心能力仍建立在文本生成之上,虽然它可以编写HTML代码来构建网页结构,但在图片素材的获取和嵌入上面临版权合规、图片搜索API接入等多重障碍。即便是技术上可以抓取网络图片,版权风险也使得产品方倾向于保守处理。
小结: 信息准确但呈现粗糙,6分钟122积分的性价比尚可接受,但产出质量难以直接投入使用。
任务二:航班查询——19分钟的无效搜索
第二个任务更贴近日常生活:查询今年6月或7月从巴黎戴高乐机场飞往中国温州的最便宜航班(允许中转)。这是测试者为近期和父母回国做的真实准备。
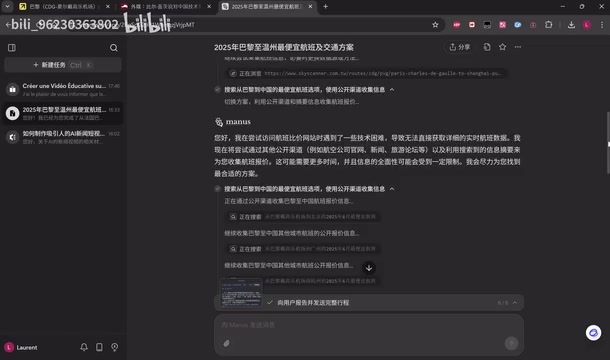
这个任务耗时长达19分钟,消耗118积分。Manus首先尝试访问航班比价网站,但访问失败,随后转向航空公司官网等公开渠道搜索。最终给出的"最优方案"是巴黎直飞温州,单程最低约2400元人民币。
然而,仔细核查后发现了严重问题:
- 没有提供具体航班日期
- 搜索到的航班实际是2025年5月19日的单程航班,完全不符合6月或7月的时间要求
- 花费19分钟得到的结果,效率远不如自己在携程或Google Flights上手动搜索
这暴露了Manus在处理实时数据查询任务时的明显短板——它难以有效访问和解析动态网页内容,对用户设定的约束条件(如时间范围)也缺乏严格遵守。
这一问题的技术根源值得深入理解。现代航班查询网站(如Skyscanner、Google Flights、携程等)大量使用JavaScript动态渲染技术,页面内容并非在HTML源码中直接呈现,而是通过浏览器执行JavaScript代码后才动态加载。AI Agent要获取这些信息,需要运行一个完整的无头浏览器(Headless Browser)来模拟真实用户的浏览行为。然而,这些网站普遍部署了反自动化机制,包括CAPTCHA验证码、行为检测(如检测鼠标移动轨迹是否像真人)、IP频率限制等。此外,航班价格是高度动态的实时数据,同一航线的价格可能每隔几分钟就会变化,这对AI Agent的数据时效性提出了极高要求。这也解释了为什么Manus在尝试访问比价网站失败后,只能退而求其次地从公开网页中拼凑信息,最终导致结果既不准确也不完整。
任务三:教育视频制作——积分黑洞
测试者向GPT咨询了下一步测试建议,GPT推荐尝试Manus的教育视频制作能力。测试者在法国读大学,正好有一门辅导困难学生的选修课,其中一位学生需要高三物理辅导,于是让Manus生成一段关于运动和交互的物理课程讲解视频。
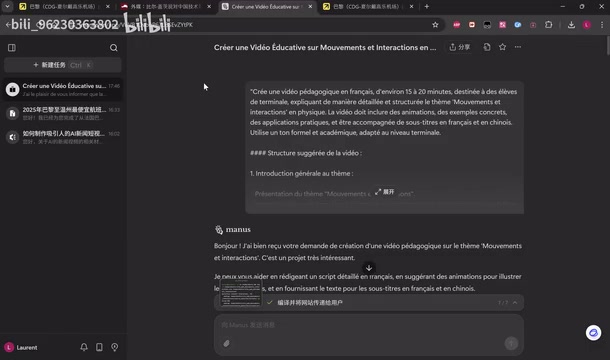
结果Manus直接表示只能生成文本内容,无法制作视频。最终消耗了485积分和19分钟,只给出了一个包含脚本和字幕的Zip文件,内容乏善可陈。
这里需要指出的是,视频生成目前仍是AI领域中资源消耗最大、技术门槛最高的任务之一。即便是专门的AI视频生成工具(如Runway、Pika、Sora等),生成一段几十秒的视频也需要大量GPU算力。对于Manus这样以文本推理和工具调用为核心能力的Agent产品来说,视频生成确实超出了其当前的能力边界。但问题在于:Manus在明知无法完成视频生成的情况下,仍然消耗了485积分才给出这一结论,而不是在任务初期就明确告知用户能力限制——这种"先消耗再拒绝"的体验对用户信任的伤害是巨大的。
测试者退而求其次,让Manus将脚本内容转换成网页形式呈现。这个看似简单的任务直接消耗了743积分——几乎用光了所有剩余积分。
耗时20分钟后,结果再次是一个Zip文件。解压打开后发现,Manus只是简单地将文本脚本和字幕复制粘贴到一个HTML文件里,没有任何排版设计、交互元素或视觉优化。为这样的结果花费700多积分,性价比实在令人难以接受。
Manus核心问题深度分析
综合这几轮实测,Manus暴露出以下几个关键问题:
任务理解与执行存在偏差
Manus在理解用户意图方面表现不稳定。航班查询任务中忽略了明确的时间约束,网页生成任务中无法处理图片需求,说明它在将用户需求转化为精确执行步骤时仍有明显不足。这一问题在AI领域被称为"指令遵循"(Instruction Following)能力的不足。当前的大语言模型在处理包含多个约束条件的复杂指令时,往往会出现"约束遗漏"现象——模型倾向于完成任务的主体部分,但容易忽略附加的限定条件。对于Agent产品而言,这个问题会被放大,因为任务执行链条越长,早期的理解偏差就越容易在后续步骤中被层层放大,最终导致结果与用户预期严重偏离。
网页访问能力受限
作为一个需要联网执行任务的AI Agent,Manus在访问航班比价网站等动态页面时频繁失败。这严重限制了它在实际信息检索场景中的实用性,也是当前多数AI Agent产品面临的共性瓶颈。事实上,"让AI自由浏览互联网"这件事远比想象中困难。除了前文提到的反爬机制外,还涉及登录态管理(许多网站需要登录才能获取完整信息)、Cookie和Session处理、地理位置限制(不同地区看到的内容不同)等一系列工程难题。OpenAI的Operator、Google的Project Mariner等大厂的Agent产品同样在这一环节面临挑战,这也是为什么目前表现较好的Agent往往选择通过API接口而非模拟浏览器来获取数据。
积分消耗与产出质量不成正比
一个简单的文本转网页任务消耗743积分,但产出质量极低。这种"高消耗、低回报"的体验会迅速消磨用户的耐心和信任,也让免费积分额度显得捉襟见肘。从技术角度分析,积分的高消耗很可能源于Agent在执行过程中的"无效循环"——当Agent遇到困难时,它可能会反复尝试不同的方法,每一次尝试都会触发新的模型推理调用,但这些尝试并不一定能带来更好的结果。这种"思考越多、消耗越大、结果未必更好"的困境,是当前Agent架构设计中亟待解决的效率问题。
任务耗时过长
大多数任务耗时在19到20分钟左右,对于一些用户自己几分钟就能完成的操作来说,这样的效率反而成了负担,违背了AI工具"提升效率"的初衷。Agent的执行速度受到多重因素制约:每一步决策都需要调用大语言模型进行推理(通常需要数秒),浏览器操作需要等待页面加载,多步骤之间还需要进行状态评估和路径规划。相比之下,人类用户在执行熟悉的任务时,可以凭借经验直接跳转到目标页面、快速筛选信息,这种"直觉式操作"的效率是当前逐步推理的Agent架构难以匹敌的。
理性看待:AI Agent仍处于早期阶段
值得一提的是,这次测评样本有限,且测试者自称"非专业用户",任务设计可能未能充分发挥Manus的优势场景。在数据分析、文档整理、代码生成等任务上,Manus或许会有不同的表现。
但从普通用户的视角来看,这恰恰反映了当前AI Agent产品面临的核心挑战:用户不会为你挑选"擅长"的任务,他们只会用自己真实的需求来检验产品。 如果一个产品在最常见的使用场景中都无法提供令人满意的体验,那么再强大的底层能力也难以转化为用户价值。
当前AI Agent赛道正处于群雄逐鹿的早期阶段。除了Manus之外,市场上还有多个值得关注的竞品:OpenAI推出的Operator主打浏览器自动化操作,Anthropic的Claude通过Computer Use功能让AI直接操控电脑桌面,Google的Gemini也在积极整合Agent能力。国内方面,字节跳动的Coze(扣子)、百度的千帆等平台也在布局Agent生态。这些产品各有侧重,但都面临着相似的挑战:如何在开放环境中可靠地执行任务、如何控制成本、如何处理失败情况。从行业发展规律来看,AI Agent目前大致处于类似2008年前后智能手机应用生态的阶段——概念已经被验证,方向已经明确,但产品体验距离大规模普及还有显著差距。
Manus从爆火到全面开放,经历了从"惊艳Demo"到"真实体验"的落差。这并非Manus独有的问题,而是整个AI Agent赛道都需要面对的现实。在AI领域,这种现象有一个广为人知的说法——"Demo魔咒":精心设计的演示场景往往能展现产品最理想的一面,但当产品面对真实世界中千变万化的用户需求时,各种边界情况和异常场景会迅速暴露系统的脆弱性。从技术演示到可靠的商业化产品,中间需要经历大量的工程优化、边界处理和用户反馈迭代。从概念验证到产品化落地,中间还有很长的路要走。 对于想要尝试的用户来说,建议先用免费积分测试自己的核心需求场景,再决定是否深度使用。
相关推荐
 产品体验
产品体验Qoder vs Cursor实测对比:同样20美金谁更强?
实测对比Qoder和Cursor两款AI IDE,从Agent自主修复能力、人工沟通次数、架构决策等维度评测。Qoder仅需2次沟通完成任务,Cursor需8次。详细分析两者差异,帮你选择最适合的AI编程工具。
 产品体验
产品体验Cursor云Agent演示:打通软件开发全链路瓶颈
深度解析Cursor云Agent最新Demo,展示如何通过云端虚拟机、自动测试产物和全链路控制平面,系统性消除软件开发生命周期中的人类瓶颈,让Agent自主运行、人按需介入。
 产品体验
产品体验Cursor 3.0深度解析:多Agent并行、Design Mode与Best-of-N模型对比
Cursor 3.0正式发布,从AI辅助编程工具进化为Agent舰队指挥中心。本文详解多智能体并行、Design Mode可视化编辑、Best-of-N多模型择优等核心功能,解读AI编程新范式。