手撕神经网络:从线性回归到梯度下降的底层原理详解
引言:为什么要手撕神经网络底层?
掌握深度学习的底层原理,是从大模型应用开发者迈向大模型解决方案架构师的必经之路。只有真正理解模型架构和训练原理,才能设计出高性能、低成本的解决方案,从容应对万亿参数模型的规模化挑战。
本文将从最基础的线性回归出发,逐步推导逻辑回归、梯度下降法,最终引出神经网络的核心机制——特征组合与反向传播。这些内容不仅是面试大厂的必考题,更是理解Transformer、Attention等现代大模型架构的基石。
线性模型:从线性回归到逻辑回归
线性回归:最朴素的预测模型
线性回归的核心思想非常直观:预测值 Y 与输入特征之间呈线性关系,即每个特征 X 的变化对 Y 的影响是成比例的。数学表达为:
$$Z = W_1X_1 + W_2X_2 + ... + W_nX_n + b$$
这里的 W 是权重参数,b 是偏置项,它们共同决定了模型的预测能力。
线性回归的历史可以追溯到19世纪初,由高斯和勒让德分别独立提出最小二乘法,它不仅是机器学习的起点,更是整个统计学的基石。在深度学习时代,线性回归的思想依然无处不在——Transformer中的线性投影层(用于生成Q、K、V矩阵)本质上就是多组线性回归的并行计算。理解线性回归中权重W的物理含义——即每个特征对预测结果的贡献度——有助于后续理解Attention中权重矩阵的语义角色。
逻辑回归:加一个Sigmoid就变成分类器
线性回归和逻辑回归之间,其实只差一个 Sigmoid 函数。在线性回归的输出 Z 上套一层 Sigmoid:
$$\hat{Y} = \sigma(Z) = \frac{1}{1 + e^{-Z}}$$
Sigmoid 函数能将任意实数映射到 (0, 1) 的开区间,输出值可以解释为概率。当预测概率大于 0.5 时归为正类,小于 0.5 时归为负类——不过这个 0.5 的阈值是主观设定的,实际业务中完全可以根据需求调整。
值得一提的是,Sigmoid函数在神经网络发展史上占据核心地位,但在现代深层网络中已逐渐被ReLU(Rectified Linear Unit)及其变体所取代。原因在于Sigmoid存在梯度消失问题:当输入值的绝对值较大时,Sigmoid的导数趋近于0,导致深层网络的梯度在反向传播过程中逐层衰减,使得靠近输入层的参数几乎无法更新。ReLU函数 $f(x)=\max(0,x)$ 在正区间的导数恒为1,有效缓解了这一问题。不过在大模型领域,GELU(Gaussian Error Linear Unit)和SwiGLU等更复杂的激活函数正在成为主流选择,例如LLaMA系列模型就采用了SwiGLU激活函数。
梯度下降法:模型学习的核心引擎
损失函数与参数更新
模型的参数 W 一开始是随机初始化的,我们需要一种方法让它逐步优化。对于线性回归,损失函数采用均方误差:
$$L = (\hat{Y} - Y)^2$$
我们希望这个损失越来越小,而改变损失的唯一途径就是调整 W。具体怎么调?对 W 求偏导:
$$\frac{\partial L}{\partial W_1} = 2(\hat{Y} - Y) \cdot X_1$$
然后按照梯度的反方向更新参数:
$$W_1 = W_1 - \mu \cdot \frac{\partial L}{\partial W_1}$$
其中 μ 是学习率。学习率太小,收敛缓慢,时间成本高;学习率太大,参数会来回震荡,无法收敛到最优解。
文中介绍的是最基础的批量梯度下降(Batch Gradient Descent),在实际工程中还有多种重要变体。随机梯度下降(SGD) 每次只用一个样本计算梯度,计算快但噪声大;小批量梯度下降(Mini-batch SGD) 取折中方案,是当前最常用的方式。更进一步,Adam优化器结合了动量(Momentum)和自适应学习率两大思想,能自动为不同参数调整学习率,已成为大模型训练的标配。在训练GPT-3等千亿参数模型时,还需要配合学习率预热(Warmup)、余弦退火(Cosine Annealing)等调度策略,以及混合精度训练、梯度累积等工程技巧,才能在数千张GPU上稳定收敛。
逻辑回归的损失函数:交叉熵
逻辑回归的损失函数不再是均方误差,而是交叉熵(Cross Entropy):
$$L = -[Y \cdot \log\hat{Y} + (1-Y) \cdot \log(1-\hat{Y})]$$
交叉熵本质上是衡量两个概率分布之间的差异。逻辑回归预测的是概率,用交叉熵来度量预测概率与真实标签之间的距离,数学上更加合理。
交叉熵源自信息论,由克劳德·香农在1948年奠基。在信息论中,熵衡量的是一个概率分布的不确定性,而交叉熵衡量的是用一个分布去编码另一个分布所需的平均比特数。当预测分布与真实分布完全一致时,交叉熵等于真实分布的熵,达到最小值。相比均方误差,交叉熵在分类任务中的优势在于:当预测严重偏离真实标签时,交叉熵的梯度更大,能驱动模型更快地修正错误。这一特性在大模型的预训练中尤为重要——GPT系列模型的预训练目标就是最小化下一个token预测的交叉熵损失。
梯度下降法最核心的优点是通用性——这个方法贯穿整个AI领域,从传统机器学习到现在的大模型、多模态模型,都在使用梯度下降法。它不局限于任何特定的模型形式,只要你能对损失函数求导,就能用它来优化。
从逻辑回归到神经网络:特征组合的艺术
线性不可分问题
逻辑回归本质上是在画一条线(或超平面)来分隔数据。但当数据是线性不可分的时候——无论怎么画线都无法完全分开两类——逻辑回归就束手无策了。
一个朴素的解决方案是手动构造新特征。比如原始特征是 X1 和 X2,我们定义 X3 = X1 × X2,将问题从二维提升到三维,就可能用一个平面把两类分开。
好特征比好模型更重要
做好分类主要靠三点:特征区分性强、特征数量多、特征组合丰富。就像一把烂牌如果能组成顺子,照样能赢。但在实际业务中,前两点往往是固定的——数据给你多少特征就是多少。真正能发挥空间的,是第三点:各种特征的组合。
然而,当特征数量达到上百个时,手动组合几乎不可能。这就催生了神经网络——一种自动进行特征组合的方法。
神经网络自动进行特征组合的能力,标志着机器学习从"特征工程"时代迈向"表示学习"时代的重大范式转变。在传统机器学习中,数据科学家需要花费大量时间手动设计特征(如文本领域的TF-IDF、词袋模型),模型性能高度依赖特征工程的质量。而深度学习的核心突破在于:让模型自己学习数据的最优表示。这一思想在大模型中被推向极致——BERT通过预训练学习通用的语言表示,GPT通过自回归预训练学习文本的生成式表示,CLIP则学习了图文对齐的多模态表示。可以说,现代大模型的本质就是超大规模的自动特征组合器。
神经网络:自动化的特征组合
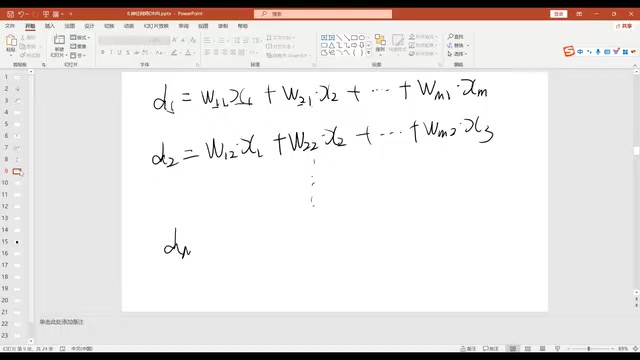
神经网络的核心思想是:让 m 个原始特征通过加权求和,生成新的组合特征。每一个新特征都是原始特征的一种线性组合:
$$d_1 = W_{11}X_1 + W_{21}X_2 + ... + W_{m1}X_m$$ $$d_2 = W_{12}X_1 + W_{22}X_2 + ... + W_{m2}X_m$$
不同的权重组合方式产生不同的特征表示。用矩阵形式可以简洁地写成:D = W · X,其中 W 是一个 M×m 的参数矩阵。矩阵运算本质上就是把大量加权求和运算压缩成一个简洁的公式。
激活函数:为什么非线性变换不可或缺?
从泰勒展开理解非线性激活的作用
仅做线性组合是不够的,必须对组合结果施加一个非线性变换(激活函数),比如 Sigmoid。为什么?
根据泰勒公式,任何函数都可以展开为多项式的加权求和。如果激活函数 f 是 Sigmoid,它的各阶导数都不为零。当我们对 $f(W_{11}X_1 + W_{21}X_2 + W_{31}X_3)$ 做泰勒展开时,二阶项展开后必然包含 $X_1 \cdot X_2$、$X_1 \cdot X_3$、$X_2 \cdot X_3$ 这样的交叉项,甚至更高阶的组合项。
这意味着,非线性激活函数在数学形式上天然具备了高阶特征组合的能力,无需人工设计。这是神经网络强大表达能力的数学根基。
从更宏观的理论视角来看,这与万能近似定理(Universal Approximation Theorem) 密切相关。该定理指出,一个具有足够多隐藏神经元的单隐藏层前馈神经网络,在使用非线性激活函数的条件下,可以以任意精度逼近任何连续函数。换言之,如果没有非线性激活函数,无论网络有多少层,其表达能力都等价于一个单层线性模型——因为多个线性变换的复合仍然是线性变换。非线性激活函数正是打破这一限制的关键。
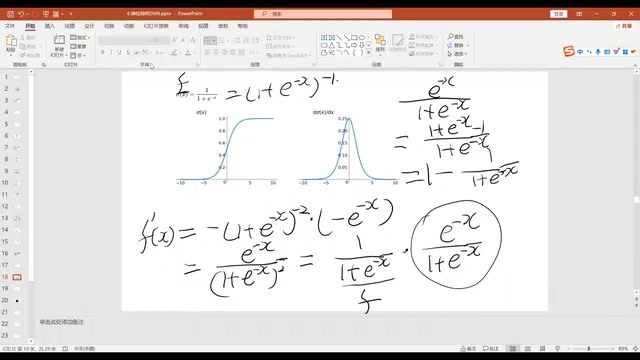
Sigmoid导数的推导
Sigmoid 函数的导数是面试高频考点,推导过程如下:
$$f(x) = \frac{1}{1 + e^{-x}}$$
$$f'(x) = \frac{e^{-x}}{(1 + e^{-x})^2} = f(x) \cdot (1 - f(x))$$
这个结论非常优雅:Sigmoid 的导数可以用函数值本身来表示。这在反向传播计算中极为方便,后续所有涉及 Sigmoid 的求导都会直接用到这个结论。
神经网络的完整结构与反向传播求导
两层神经网络的构建
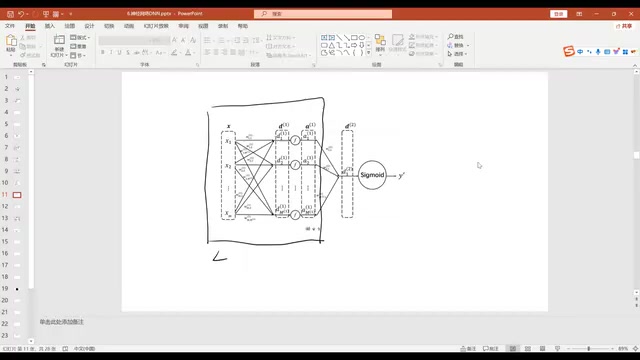
以一个最简单的两层神经网络为例:输入层有 X1、X2 两个特征,隐藏层有 3 个神经元(A1、A2、A3),输出层做二分类。
每个隐藏层神经元的计算过程是:
- 加权求和:$Z = W_1X_1 + W_2X_2 + b$
- 激活变换:$A = \sigma(Z)$
隐藏层输出的 A1、A2、A3 作为新特征,再送入输出层做逻辑回归,得到最终预测 $\hat{Y}$。
前半部分是特征组合,后半部分就是一个标准的逻辑回归。所有的权重参数都通过梯度下降法学习得到——我们只需要告诉网络"你需要对特征进行组合",至于怎么组合、权重取多少,由训练任务和数据来决定。
链式法则:反向传播的数学基础
求解神经网络参数的关键在于链式法则。对于复合函数 $z = g(k \cdot y)$,$y = f(w \cdot x)$:
$$\frac{\partial z}{\partial w} = \frac{\partial z}{\partial y} \cdot \frac{\partial y}{\partial w}$$
这就是反向传播算法的数学本质:从输出层开始,沿着计算图逐层向前传递梯度,每一层的梯度都是后一层梯度与当前层局部梯度的乘积。
反向传播算法(Backpropagation)由Rumelhart、Hinton和Williams在1986年的经典论文中正式提出并推广,被认为是深度学习发展史上最重要的算法突破之一。其核心思想是利用链式法则,从输出层到输入层逐层计算梯度,避免了重复计算。现代深度学习框架(如PyTorch、TensorFlow)通过计算图(Computational Graph) 自动实现反向传播:前向传播时构建计算图,记录每一步操作;反向传播时沿计算图反向遍历,自动计算所有参数的梯度。这就是PyTorch中调用 loss.backward() 时背后发生的事情。理解反向传播的手动推导过程,有助于在模型调试中快速定位梯度异常(如梯度爆炸、梯度消失)的根因。
掌握了链式法则和 Sigmoid 导数,就具备了手推任意神经网络梯度的能力。现在大厂面试甚至会要求对 Transformer 的 Attention 机制求导——如果连基础的 Sigmoid 求导都推不出来,更复杂的结构就无从谈起。
总结
从线性回归到逻辑回归,再到神经网络,本质上是一条清晰的演进路线:线性模型 → 加 Sigmoid 变分类器 → 加隐藏层做特征组合 → 加非线性激活获得高阶表达能力 → 用梯度下降法端到端学习所有参数。
这些基础看似简单,却是理解 DNN、Attention、Transformer 乃至整个大模型体系的底层法则。掌握这些基本功,无论是应对技术面试还是设计实际系统架构,都能让你游刃有余。
核心要点
相关推荐
AI Agent核心架构拆解:从概念到企业级智能体搭建
深度解析AI Agent智能体的三大核心架构:感知模块、大脑模块与行动模块,详解RAG记忆系统、工具调用机制及Chain of Thought推理能力,附企业级智能体开发技能路线图。
200行Python代码从零搭建AI Agent智能体实战教程
用200行Python代码从零搭建AI Agent智能体,逐步拆解提示词、记忆、工具调用、RAG检索增强和Skill技能五大核心模块,适合Python开发者快速入门Agent开发。
Anthropic撤回Claude隐形限制AI研究者的争议政策
Anthropic因Claude Fable/Mythos模型隐形限制前沿LLM开发请求的政策遭社区强烈反对后迅速撤回。本文详解事件始末、隐形安全措施的争议本质、Anthropic的修正方案及对AI行业透明度的深远启示。