SourceCheck:用引用替代拷贝,构建可验证的LLM可信输出

SourceCheck通过引用协议替代复述,构建可验证的LLM输出。
SourceCheck是一个开源工具项目,旨在解决大语言模型的幻觉问题。其核心理念是"用引用替代拷贝"——让LLM输出极简的元数据(行号、字符串边界)来定位引用来源,再由确定性程序校验引用的合法性。系统通过绿色/红色标注区分验证通过与幻觉内容,支持多来源佐证和置信度评估,实现LLM输出的可追溯验证。
为什么我们需要 SourceCheck?
随着大语言模型(LLM)的普及,越来越多人习惯说"我问了AI,得到的结果是……"。但从LLM进入大众视野的第一天起,幻觉问题、知识偏移,以及低质量网页内容对模型输出的污染,都在持续侵蚀着LLM输出的可信度。
大语言模型的「幻觉」(Hallucination)是指模型生成看似合理但实际上不准确或完全捏造的内容。这一现象源于LLM的本质:它们是基于概率的文本预测系统,通过在海量语料上训练来学习语言模式,而非真正「理解」或「记忆」事实。当模型遇到训练数据中覆盖不足的问题时,它倾向于用统计上「听起来合理」的内容填充输出,而非承认不确定性。研究表明,即使是GPT-4这类顶级模型,在特定领域的幻觉率仍可达到15%-30%。
SourceCheck 正是为解决这一痛点而生的开源工具项目。它延续了此前 ReviewDeck(代码审查项目)中的核心思路,将"如何让LLM可信地切分代码"扩展为更通用的命题——如何构建可验证的LLM输出。
其核心理念可以用一句话概括:用引用的方式替代拷贝。不再让LLM用大段的 output token 去复述来源和原文,而是通过一套新的协议格式,让模型输出极简的元数据来描述"引用了哪个文档的哪个段落",再由确定性程序来校验引用的合法性。这种设计哲学与学术引用规范高度契合——论文引用不复制全文,而是给出精确的「作者、年份、页码」定位,由读者自行查阅原文核实。将这一人类知识体系中成熟的可信机制移植到LLM输出层,是SourceCheck最核心的范式创新。
SourceCheck 的引用格式是怎么工作的?
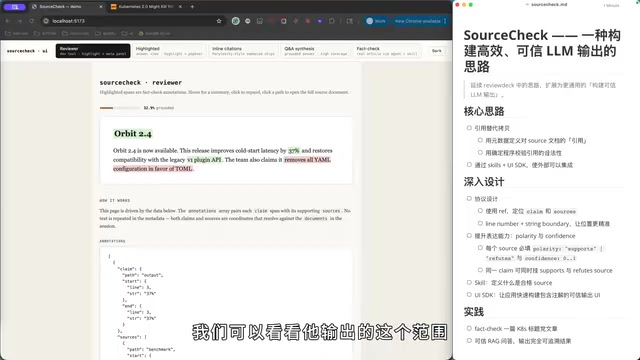
以一个实际 Demo 为例:假设我们有一段关于"Orbit 2.4"版本的描述,其中包含"2.4版本""37%"等具体数字,以及"VE Plugin API"等技术概念。这些信息都来自特定文档。
SourceCheck 的工作方式是:
- 绿色标注(验证通过):check 通过的事实,点击后可以看到来源。例如"Orbit 2.4"来源于 ChangeLog 文档中"2.4.0"的明确描述,LLM 评估两者 90% 相关。
- 红色标注(幻觉检测):被判定为幻觉的内容。例如原文写的是"继续使用 YAML,没有 format change",而输出中却出现了"YAML 变成了 TOML",系统即判定为幻觉。
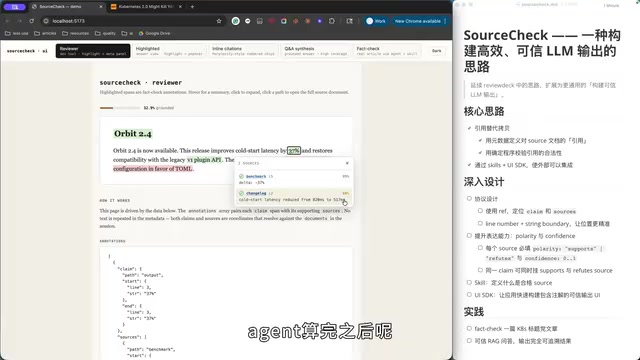
- 多来源佐证:"37%"这个数字可能来自两个地方——ChangeLog 中 latency 从 820ms 降到 517ms(Agent 计算后认为接近 37%,给出 80% 置信度),以及 Benchmark 结果中明确的"减少 37%"。
关键在于,不管是通过还是未通过的事实,都可以通过引用追溯到判定依据。元数据中只包含行号和起止字符串的描述,不会大段复述原文——在LLM的计费模型中,输出token(Output Token)的成本通常高于输入token,大段复述原文不仅浪费成本,还会因模型的改写倾向引入新的失真。确定性程序负责检测这个 range 是否真实存在于原文中。
SourceCheck 的四大核心模块详解
协议设计:统一的 Reference 定位体系
SourceCheck 自定义了一套协议,使用 Reference 这一核心概念来同时定位两类内容:
- Claim(声明)——LLM 输出中需要验证的具体声明
- Source(来源)——支撑或驳回该声明的原始文档片段
两者都使用统一的 Reference 格式进行定位,这种设计带来了极强的一致性和扩展性。
相比 ReviewDeck 中仅支持行号定位(对代码场景足够),SourceCheck 做了重要升级:在纵向的 line number 定位之外,增加了横向的 string boundary(字符串边界)能力。这是因为在通用文本场景中,经常需要跨行定位或在同一行内找到更精确的片段。
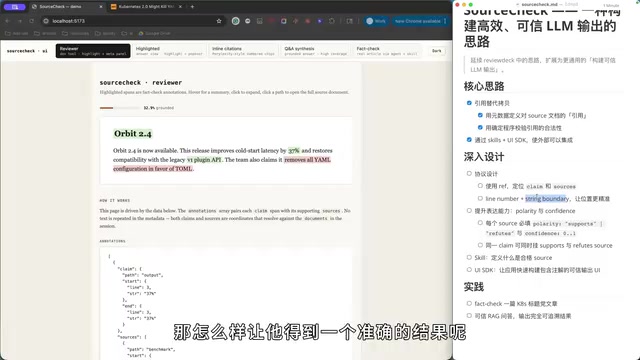
那如果字符串没有匹配到,或者同一字符串在某行中出现了多次怎么办?这正是确定性程序要解决的问题。「确定性程序」(Deterministic Program)特指不依赖概率模型、每次执行结果完全可预测的传统算法程序。与LLM的随机性输出相对,确定性程序对字符串匹配、行号校验等操作给出明确的「通过/失败」判定,没有模糊地带。这种「LLM负责语义理解,确定性程序负责事实校验」的分工架构,是当前AI工程领域的重要设计模式。
它会对这些边界情况做校验,校验不通过时通过 Skill 引导 Agent 重新输出更精准、更唯一的 Reference。这种"输出→校验→反馈→重新输出
相关推荐
 教程攻略
教程攻略Cursor+Codex双IDE协同:开源项目二开实战方法论
基于实战经验总结的开源项目二次开发完整方法论,详解Cursor+Codex双IDE协同工作流,涵盖二开七环节、MVP验证、AI读源码技巧,帮助开发者三天跑通项目、两周完成业务集成。
 教程攻略
教程攻略Cursor多Agent实战:50分钟搭建Next.js全栈博客
使用Cursor IDE多Agent协作模式,50分钟内从零搭建全栈博客。涵盖Next.js、Clerk认证、Supabase数据库集成,详解4个AI Agent分阶段开发流程与关键避坑经验。
 教程攻略
教程攻略从零搭建AI软件工厂:Cursor工程师的多Agent协作实战经验
Cursor工程师Eric分享AI软件工厂构建实战:从自动化六层级、护栏设计、并行Agent管理到规模化扩展,详解如何用多Agent协作实现7×24小时高效软件开发。