Spring AI 2.0实战:一小时搭建RAG知识库问答系统

基于Spring AI 2.0构建企业级RAG知识库问答系统的实战项目介绍
本文介绍了一个基于Spring AI 2.0框架的企业级RAG问答系统实战项目。系统采用Spring Boot + Vue 3架构,结合Ollama本地部署千问3大模型和Redis向量数据库,实现了文档上传解析、自动分片向量化、语义检索和智能问答等核心功能。项目支持本地化部署以保护数据隐私,是Java开发者入门AI应用开发的参考案例。
项目概述:用Spring AI 2.0构建企业级RAG问答系统
RAG(Retrieval-Augmented Generation,检索增强生成)已经成为企业落地大模型应用时绕不开的核心技术。这一技术诞生于2020年Meta AI Research的论文《Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks》,其核心动机是解决纯生成式大模型的两大痛点:知识截止日期(训练数据有时效性)和幻觉问题(模型倾向于自信地生成错误信息)。简单来说,RAG让大模型在回答问题时不再"凭空编造",而是先从企业知识库中检索相关内容,再基于真实资料生成回答——这正是企业最需要的"靠谱AI"。在企业场景中,这意味着AI可以基于公司内部文档、产品手册、规章制度等私有知识库进行问答,而无需将敏感数据上传到模型训练集。
本文介绍的这个实战项目,基于Spring AI 2.0框架搭建了一套完整的RAG企业知识库问答系统,并借助Cursor AI编程工具大幅提升开发效率。整个项目采用Spring Boot后端 + Vue 3前端的经典架构,结合Ollama本地大模型和Redis向量数据库,是Java开发者入门AI应用开发的绝佳参考案例。

技术栈与架构设计
后端:Spring Boot + Spring AI 2.0
后端基于Spring Boot + Spring AI 2.0构建。Spring AI是Pivotal/VMware团队于2023年推出的Java AI开发框架,其设计哲学与Spring生态一脉相承——通过抽象层屏蔽底层差异,让开发者用统一的API对接不同的AI服务商。Spring AI 2.0在1.x基础上大幅完善了向量数据库支持(涵盖Redis、Pinecone、Weaviate、Chroma等十余种)、函数调用(Function Calling)、多模态输入等能力。对Java开发者而言,Spring AI最大的价值在于:无需学习Python生态(LangChain/LlamaIndex),即可在熟悉的Spring Boot体系内完成RAG、Agent等AI应用的完整开发,是目前Java生态中最成熟的AI开发框架。
数据库方面采用MySQL 8存储业务数据,密码使用MD5加密(默认密码123456),会话缓存则交给Redis处理。
大模型接入支持两种方式:
- 百度云平台:适合没有本地GPU资源的开发者,通过API调用即可
- Ollama本地部署:本项目主要演示的方案,使用千问3(4B参数版本),对显卡要求不高,普通开发机就能跑起来
Ollama是2023年兴起的本地大模型运行框架,类似于大模型领域的"Docker"——通过简单的命令行即可拉取、运行各类开源模型。它底层基于llama.cpp实现,支持CPU和GPU混合推理,使得在没有高端显卡的普通开发机上运行中小规模模型成为可能。千问3(Qwen3)是阿里云推出的开源大模型系列,4B参数版本在8GB内存的机器上即可流畅运行,在中文理解和代码生成方面表现尤为出色。本地部署的核心价值在于数据隐私保护——企业敏感文档的向量化和问答推理全程在本地完成,不经过任何外部API,满足金融、医疗、政务等对数据合规有严格要求的行业需求。
嵌入模型(Embedding Model)同样使用千问3系列,负责将文档内容转化为向量表示。向量数据库选用Redis Vector Store,通过Docker Desktop运行,部署过程非常简单。Redis从7.2版本起通过RedisSearch模块原生支持向量存储与检索,相比Pinecone等专用向量数据库,Redis的优势在于部署简单、与现有缓存基础设施复用,非常适合中小规模企业知识库场景(百万级以下向量)。
前端:Vue 3 + Vite
前端采用Vue 3 + Vite构建,界面设计简洁美观,集成了丰富的数据可视化图表。系统区分管理员和普通用户两种角色,提供差异化的操作界面和功能权限。
核心功能模块详解
知识库文档管理
系统支持四种常见格式的知识库文件上传与解析:
- TXT:纯文本文件
- DOCX:Word文档
- PDF:PDF文档
- Markdown:Markdown格式文件
文档上传后,系统会自动完成解析、分片、向量化三个步骤,最终将向量数据存入Redis向量数据库。其中"分片"(Chunking)步骤看似简单,实则是RAG系统质量的关键决定因素之一。分片过大会导致检索到的上下文包含大量无关信息,超出大模型的上下文窗口限制;分片过小则可能切断完整语义,导致检索结果缺乏足够上下文。常见的分片策略包括:固定长度分片(按字符数或Token数切割)、语义分片(按段落、章节等自然边界切割)、以及滑动窗口分片(相邻分片有重叠区域以保留边界语义)。Spring AI 2.0内置了多种TokenTextSplitter实现,开发者可根据文档类型灵活配置分片大小和重叠比例。
管理员可以在后台查看每个文档的向量片段详情,也可以按分类对文档进行管理。项目还贴心地提供了测试文档,涵盖API规范、产品使用指南、公司规章制度、技术规范等典型企业知识库场景。
RAG智能问答系统
这是整个项目的核心所在。向量数据库的检索原理是:嵌入模型将文本转化为高维浮点数向量(通常512到4096维),语义相近的文本在向量空间中距离更近,系统通过HNSW(分层可导航小世界图)等近似最近邻算法在毫秒级完成语义相似度搜索。当用户提出一个问题时,系统会按以下流程处理:
- 通过嵌入模型将用户问题转化为向量
- 在Redis向量数据库中检索语义最相关的文档片段
- 将检索到的上下文信息与用户问题拼接,一起发送给大模型
- 大模型基于真实的知识库内容生成准确回答
- 同步展示引用的原文片段,方便用户追溯验证
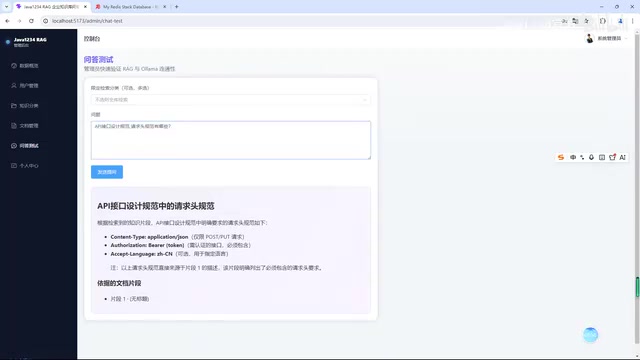
系统还支持多文档选择检索——用户可以指定只在某几个文档范围内搜索,也可以选择全库检索。每条回答都会标注引用来源,让AI的回答"有据可查
相关推荐
 教程攻略
教程攻略Cursor+Codex双IDE协同:开源项目二开实战方法论
基于实战经验总结的开源项目二次开发完整方法论,详解Cursor+Codex双IDE协同工作流,涵盖二开七环节、MVP验证、AI读源码技巧,帮助开发者三天跑通项目、两周完成业务集成。
 教程攻略
教程攻略Cursor多Agent实战:50分钟搭建Next.js全栈博客
使用Cursor IDE多Agent协作模式,50分钟内从零搭建全栈博客。涵盖Next.js、Clerk认证、Supabase数据库集成,详解4个AI Agent分阶段开发流程与关键避坑经验。
 教程攻略
教程攻略从零搭建AI软件工厂:Cursor工程师的多Agent协作实战经验
Cursor工程师Eric分享AI软件工厂构建实战:从自动化六层级、护栏设计、并行Agent管理到规模化扩展,详解如何用多Agent协作实现7×24小时高效软件开发。