Stagehand教程:兼顾可控与智能的AI浏览器自动化框架
Stagehand融合代码与AI,实现灵活可控的浏览器自动化
Stagehand是一个混合模式的浏览器自动化框架,融合了Playwright等传统代码框架的稳定性与大模型驱动工具的灵活性。它提供Act(自然语言执行动作)、Extract(结构化数据抽取)、Observe(先侦察再行动)和Agent(全自动)四大核心能力,开发者可自主选择代码与AI的使用比例,在可控性与灵活性之间取得最佳平衡,同时通过Observe机制显著降低Token消耗。
浏览器自动化的两难困境
当前浏览器自动化工具主要分为两大阵营:
传统代码框架(如 Playwright、Puppeteer)完全由代码驱动,执行稳定可靠,但学习成本高、开发周期长,且一旦目标网页结构发生变化,就需要重新调整选择器代码,维护成本居高不下。Playwright 由微软开发,Puppeteer 由 Google Chrome 团队维护,两者都通过 CDP(Chrome DevTools Protocol)或类似协议与浏览器进行通信。它们的核心工作原理是通过 CSS 选择器、XPath 或 ARIA 属性精确定位页面元素,然后执行点击、输入、截图等操作。这种方式的稳定性来源于确定性——相同的选择器在相同的页面结构下必然定位到相同的元素。但现代 Web 应用大量使用动态生成的 class 名称(如 CSS Modules、Tailwind 的哈希类名)和频繁迭代的前端组件,导致选择器极易失效,这也是传统框架维护成本高的根本原因。
大模型驱动工具(如 Browser Use)则走向另一个极端——用户只需输入自然语言指令,AI 全权接管浏览器操作。虽然上手极其简单,但执行结果难以控制,每一步都依赖大模型推理,Token 消耗巨大,运行耗时也相当可观。具体来说,Browser Use 等工具在每一步操作时,都需要将当前页面的 DOM 结构(或截图)发送给大模型进行推理,由模型判断下一步该做什么。一个典型的网页 DOM 可能包含数千个节点,序列化后轻松超过数万 Token。如果一个自动化流程包含 10-20 步操作,累计 Token 消耗可能达到数十万,按 GPT-4o 的定价计算,单次流程成本可能高达数美元。此外,每次大模型调用都有网络延迟和推理耗时,通常在 2-10 秒之间,这使得整个自动化流程的执行时间远超传统代码方案。
那有没有一种方案,能让开发者自主选择哪些步骤用代码编写、哪些步骤用自然语言描述,从而兼顾稳定性与灵活性?这正是 Stagehand 要解决的问题。
Stagehand 的四大核心能力
Stagehand 的设计哲学非常清晰,它将浏览器自动化拆解为四个原子操作:Act、Extract、Observe 和 Agent。开发者可以根据实际场景自由组合,在代码可控性和 AI 灵活性之间找到最佳平衡点。
这种混合模式的核心理念源自软件工程中的「关注点分离」原则。在实际的浏览器自动化项目中,大约 70-80% 的操作是结构化的、可预测的(如导航到固定 URL、等待页面加载、处理已知的弹窗),这些操作用传统代码实现最为高效可靠。剩余 20-30% 的操作涉及动态内容理解(如识别验证码类型、理解不同网站的搜索框位置、解析非结构化的页面内容),这些才是大模型真正发挥价值的场景。Stagehand 的混合模式让开发者能够精确控制 AI 介入的边界,避免了「全交给 AI」带来的不可控性,也避免了「全用代码」带来的脆弱性。
Act:将自然语言翻译为具体动作
Act 是 Stagehand 最基础的操作单元。你用自然语言描述一个动作,框架会将其转化为真实的浏览器操作。例如:
click the Login button→ 点击登录按钮fill the search box with "stagehand"→ 在搜索框中输入内容scroll down→ 向下滚动页面select an option from the menu→ 在菜单中选择选项
它本质上是在代码流程中嵌入自然语言指令,让 AI 帮你完成那些「用 CSS 选择器定位元素太麻烦」的操作,同时整体流程仍然由你的代码控制。
Extract:按 Schema 结构化抽取页面数据
Extract 用于从网页中提取数据,并按照你预定义的 Zod Schema 返回结构化的 JSON 结果。比如你可以要求它「提取页面中所有搜索结果的标题」,它会返回一个字符串数组,输出格式完全可控。
Zod 是 TypeScript 生态中最流行的运行时类型校验库,它允许开发者用代码定义数据结构(Schema),并在运行时验证数据是否符合预期格式。在 Stagehand 的 Extract 功能中,Zod Schema 扮演着「契约」的角色:开发者预先声明期望的返回数据结构,大模型的输出必须严格匹配该结构,否则会触发校验错误。这种机制解决了大模型输出不确定性的核心痛点——即使模型的自然语言理解存在偏差,只要输出格式不符合 Schema,系统就能立即发现问题,而不是让错误数据悄悄流入下游逻辑。
这在自动化数据采集场景中非常实用,省去了手动解析 DOM 的繁琐工作。
Observe:先侦察再行动
Observe 是 Stagehand 中最具巧思的设计。它不直接执行操作,而是先扫描当前页面,返回所有可执行的操作列表,包括元素描述、可用方法(如 click)以及精确的 CSS selector。
Observe 的底层实现结合了 DOM 分析和大模型语义理解。它首先对当前页面进行可交互元素的扫描,识别出所有可点击、可输入、可选择的元素,然后将这些元素的上下文信息(如文本内容、ARIA 标签、位置关系)发送给大模型,由模型判断哪些元素与用户的指令相关。返回的结果中包含精确的 CSS selector,这意味着后续操作可以完全绕过大模型,直接通过 Playwright 的原生 API 执行。这种设计本质上是将大模型的「智能」集中在元素定位阶段,而将执行阶段回归到确定性的代码操作,实现了智能与效率的最优分配。
这种「先侦察再行动」的机制带来了三个关键优势:
1. 操作验证:在执行前先确认目标元素是否存在。比如你想点击「退出登录」按钮,但用户可能尚未登录,通过 Observe 先检查按钮是否存在,可以避免无效操作和脚本报错。
2. 大幅节省 Token:Observe 一次性定位所有目标元素后,后续的 Act 操作可以直接使用返回的 selector,不再需要与大模型交互。举个例子,如果用 Act 逐个填写表单字段(用户名、密码、邮箱……),每次填写都会消耗一次大模型调用;而用 Observe 一次性找到所有输入框,后续填写就是纯 Playwright 代码操作,Token 成本几乎为零。
3. 缩小数据抽取范围:先用 Observe 定位到页面中的特定区域(如一个数据表格),再将该区域的 selector 传给 Extract,让数据抽取只在局部范围内进行,进一步降低 Token 消耗并提升抽取精度。
Agent:全自动模式
Agent 模式类似 Browser Use 的工作方式,你只需下达一条自然语言指令,AI 会自动编排所有操作步骤。但实测发现,Agent 模式目前稳定性不佳,可能出现页面卡住或闪退等问题,建议优先使用 Act + Extract + Observe 的组合方式来构建自动化流程。
实战:从零搭建 Stagehand 项目
下面通过一个完整的实战案例,演示如何用 Stagehand 实现百度搜索自动化。
环境准备与依赖安装
首先创建一个 Next.js 项目并安装所需依赖:
npx create-next-app LearnStageHand
cd LearnStageHand
npm install -D ts-node
npm install @browserbasehq/stagehand playwright zod
npx playwright install chromium
各依赖的作用说明:
ts-node:用于直接运行 TypeScript 代码,无需额外编译步骤。它在 Node.js 运行时中注册 TypeScript 编译器,实现即时编译执行,非常适合开发调试阶段快速验证脚本逻辑。@browserbasehq/stagehand:Stagehand 核心框架,由 BrowserBase 团队开发维护。BrowserBase 本身是一个云端浏览器基础设施服务商,Stagehand 既可以连接其云端浏览器集群运行,也支持纯本地模式。playwright:底层浏览器驱动引擎,Stagehand 在其之上构建了 AI 增强层,所有最终的浏览器操作(点击、输入、导航等)都通过 Playwright 的 API 执行。zod:数据 Schema 校验工具,配合 Extract 使用,确保大模型返回的数据严格符合预定义的结构。- 最后一步安装 Chromium 浏览器驱动,这是 Playwright 控制浏览器所必需的二进制文件。
配置环境变量
创建 .env 文件,需要配置以下 Key:
- OPENAI_API_KEY:大模型 API Key(国内用户可替换为 DeepSeek)
- BROWSERBASE_API_KEY 和 BROWSERBASE_PROJECT_ID:云端运行环境的配置(可选,本地运行无需配置)
国内用户推荐使用 DeepSeek API 作为替代方案,访问 DeepSeek 官网创建 API Key 即可。DeepSeek 是国内领先的大模型服务商,其 DeepSeek-V3 和 DeepSeek-R1 模型在多项基准测试中表现接近甚至超越 GPT-4 级别。对于国内开发者而言,使用 DeepSeek API 有三个显著优势:一是网络延迟更低,无需科学上网即可稳定访问;二是价格优势明显,API 调用成本通常仅为 OpenAI 的十分之一甚至更低;三是对中文场景的理解更为准确,在处理中文网页的元素定位和数据抽取时,往往能获得更好的效果。Stagehand 框架通过模型名称前缀(如 deepseek/deepseek-chat)来路由不同的模型提供商,切换过程对业务代码几乎透明。
编写自动化脚本
创建 src/lab-stagehand.ts,核心代码逻辑如下:
// 创建 Stagehand 实例,使用本地浏览器
const stagehand = new Stagehand({ env: "local" });
await stagehand.init();
const page = stagehand.page;
// 导航到目标页面
await page.goto("https://www.baidu.com");
// Act:在搜索框中输入内容
await page.act({ action: `fill the search box with "stagehand"` });
// Act:点击搜索按钮
await page.act({ action: "click the search button" });
// Extract:提取搜索结果
const searchResult = await page.extract({
instruction: "extract the search results as an array",
schema: z.object({ results: z.array(z.string()) })
});
console.log(searchResult);
注意:使用 DeepSeek 时需要在初始化时指定 modelName: "deepseek/deepseek-chat" 并传入对应的 API Key。
Observe 的进阶用法
// 先侦察:找到搜索按钮
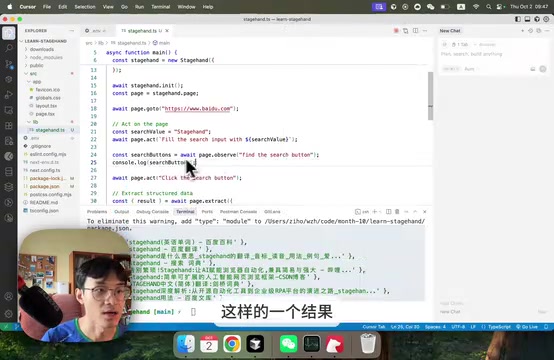
const searchButtons = await page.observe({
instruction: "find the search button"
});
console.log(searchButtons);
// 返回包含 description、method、selector 的操作列表
// 再执行:直接使用 observe 返回的结果,无需额外消耗 Token
if (searchButtons.length > 0) {
await page.act(searchButtons[0]);
}
这种「先侦察再行动」的模式,让每一步操作都有据可依,大幅提升了自动化流程的可控性和可调试性。
Stagehand vs Playwright vs Browser Use:横向对比
| 维度 | Playwright(传统框架) | Browser Use(AI 驱动) | Stagehand(混合模式) |
|---|---|---|---|
| 上手难度 | 高 | 低 | 中 |
| 执行稳定性 | 高 | 低 | 高 |
| Token 消耗 | 无 | 极高 | 可控 |
| 灵活性 | 低 | 高 | 高 |
| 可控性 | 高 | 低 | 高 |
| 维护成本 | 高(页面变动需改代码) | 低 | 中 |
Stagehand 的核心价值在于将选择权交还给开发者:结构清晰、逻辑固定的部分用 Playwright 代码编写;需要理解页面语义、动态定位元素的部分用自然语言描述交给 AI 处理。这种混合模式既保留了代码的确定性,又充分利用了大模型的语义理解能力。
它的应用场景非常广泛:自动化数据采集、日常重复性工作的批量执行,以及作为大模型 Agent 操控浏览器的底层基础设施。对于想要构建可靠浏览器自动化流程的开发者来说,Stagehand 的 Act + Extract + Observe 三件套,是目前兼顾效率与可控性的最优解。
核心要点
- Stagehand 融合了传统代码框架的稳定性与大模型工具的灵活性,开发者可自主选择代码与自然语言的使用比例
- 四大核心功能:Act(执行动作)、Extract(结构化数据抽取)、Observe(先侦察再行动)、Agent(全自动模式)
- Observe 功能通过预先定位元素,可显著减少大模型调用次数,节省 Token 消耗并提升运行速度
- 国内用户可使用 DeepSeek API 替代 OpenAI,本地运行无需配置 BrowserBase 云端服务
- Agent 模式目前稳定性不足,推荐优先使用 Act + Extract + Observe 的组合方式
相关推荐
 教程攻略
教程攻略Cursor+Codex双IDE协同:开源项目二开实战方法论
基于实战经验总结的开源项目二次开发完整方法论,详解Cursor+Codex双IDE协同工作流,涵盖二开七环节、MVP验证、AI读源码技巧,帮助开发者三天跑通项目、两周完成业务集成。
 教程攻略
教程攻略Cursor多Agent实战:50分钟搭建Next.js全栈博客
使用Cursor IDE多Agent协作模式,50分钟内从零搭建全栈博客。涵盖Next.js、Clerk认证、Supabase数据库集成,详解4个AI Agent分阶段开发流程与关键避坑经验。
 教程攻略
教程攻略从零搭建AI软件工厂:Cursor工程师的多Agent协作实战经验
Cursor工程师Eric分享AI软件工厂构建实战:从自动化六层级、护栏设计、并行Agent管理到规模化扩展,详解如何用多Agent协作实现7×24小时高效软件开发。