Testing 15 LLMs to Build a Bilibili Homepage: GPT Takes the Crown, Domestic Models Fall Behind
15 LLMs tested building a Bilibili app: ChatGPT 5.4 wins overall with significant capability gaps across models.
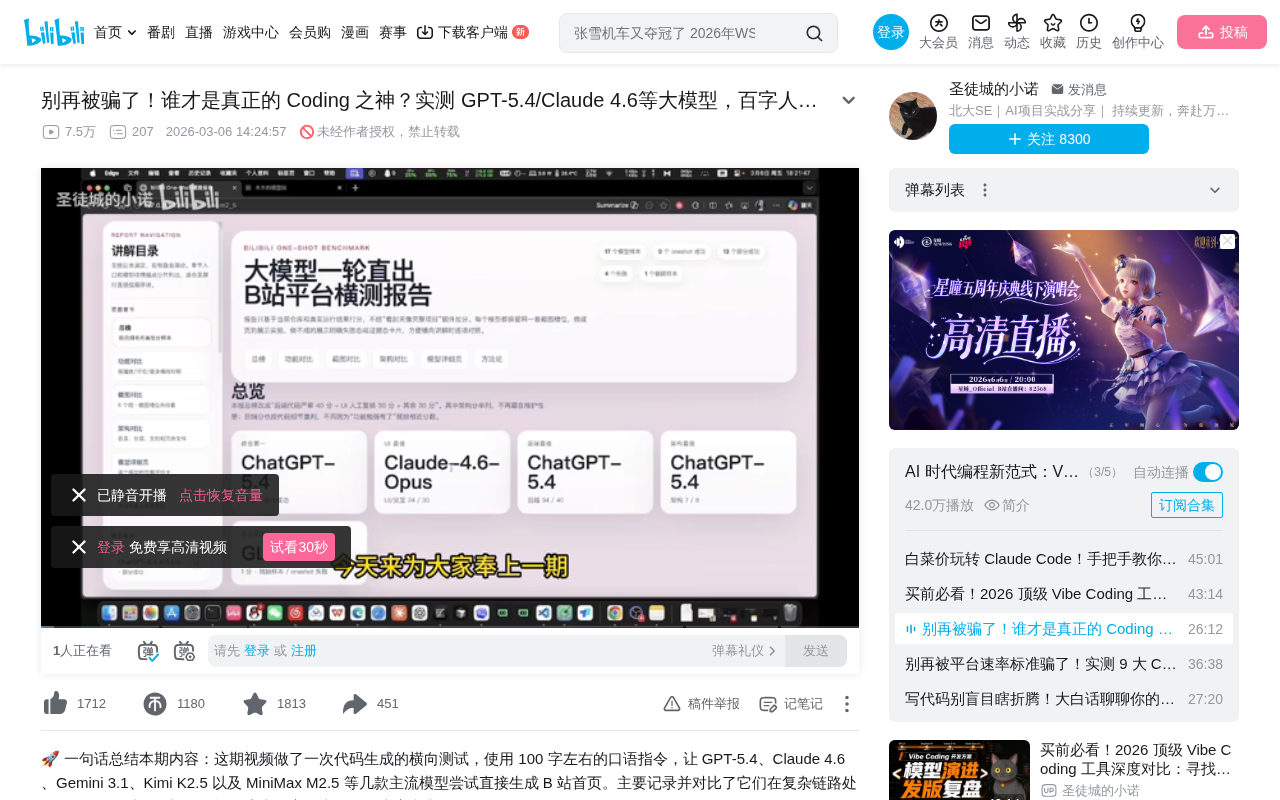
A tech team had 15 mainstream LLMs build a complete Bilibili video platform app from natural language prompts in a single pass. ChatGPT 5.4 scored highest at 82 points with the best backend and architecture but weak frontend design. Claude 4.6 Opus showed balanced full-stack ability but suffered from API hallucinations. Gemini 3.0 Pro had the best frontend fidelity but poor backend reliability. Domestic models could scaffold frameworks but struggled with actual content implementation, with GLM5 and Kimi K2.5 performing best. The conclusion: combine different models based on task characteristics for optimal results.
Test Background & Methodology
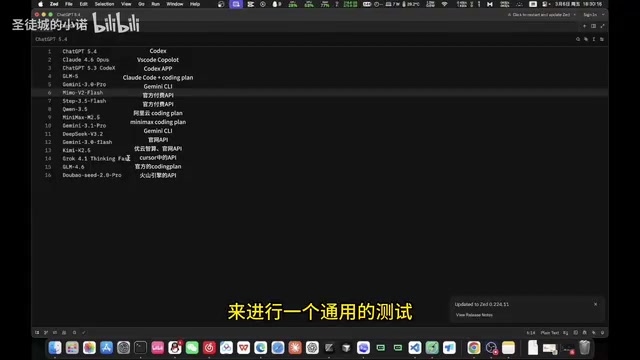
LLM vendors all claim their products have "the best coding capabilities," but do benchmark scores actually reflect real-world development ability? A Bilibili technical team decided to find out the most direct way possible — having 15 mainstream LLMs build a complete Bilibili-style video platform application using the same set of prompts in a single pass.
The core testing philosophy was highly pragmatic: no detailed requirements documents, just natural language descriptions similar to everyday development conversations, requiring models to independently handle architecture design and full-stack development with zero human involvement in the development loop. This "100-word plain language" approach is exactly how most developers actually use AI for coding.
Test Tasks & Evaluation Criteria
The functional requirements were structured in three tiers:
- Basic tier: Play Bilibili videos, display likes/coins/favorites/view counts, link to the official site
- Intermediate tier: View comments and danmaku (bullet comments), log in to Bilibili via QR code scanning
- Advanced tier: Use login credentials to post comments and danmaku, view personal favorite videos
All models used the open-source GitHub library bilibili-api as the data interface. Evaluation focused on instruction adherence, architecture design quality, frontend fidelity, and backend logic rigor.
The Big Three Overseas: Distinct Capability Profiles
ChatGPT 5.4: Backend King, Best Overall
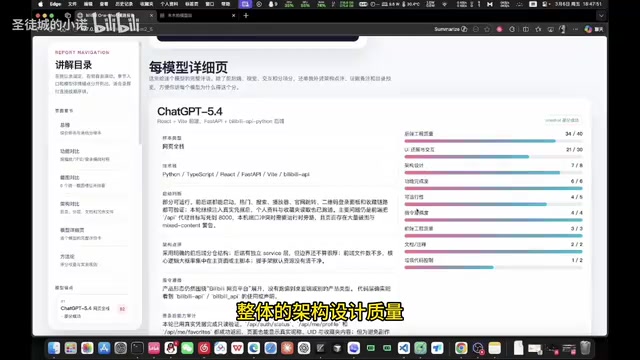
ChatGPT 5.4 claimed the top spot with a total score of 82. It achieved the highest marks in backend quality, architecture design, and instruction adherence, and was the only model in the entire test that autonomously performed Code Review to ensure instruction compliance.
However, the persistent weakness of the ChatGPT series remains — its frontend interaction design "just feels uncomfortable." While 5.4 showed UI improvements over 5.3 and could understand Bilibili's signature pink theme, the layout of interactive components like danmaku and comment sections was still suboptimal. The team's analysis suggests this stems from OpenAI's training data being weighted more heavily toward backend and logic-oriented data, with a lower proportion of frontend design aesthetics.
Claude 4.6 Opus: Designer's Mindset, Exceptional Frontend
Claude 4.6 Opus demonstrated a strikingly different capability profile. Its generated interface was nearly identical to the official Bilibili app — grid layout, pink theme, and sidebar structure were all faithfully reproduced, indicating that Anthropic maintains a more balanced ratio of frontend and backend data quality in training.
However, Claude has one critical issue: model hallucinations leading to incorrect API calls. For the login feature, it correctly explored the third-party library and found the right interface, but then called the wrong API during actual implementation. By comparison, the ChatGPT series almost never exhibited this type of problem.
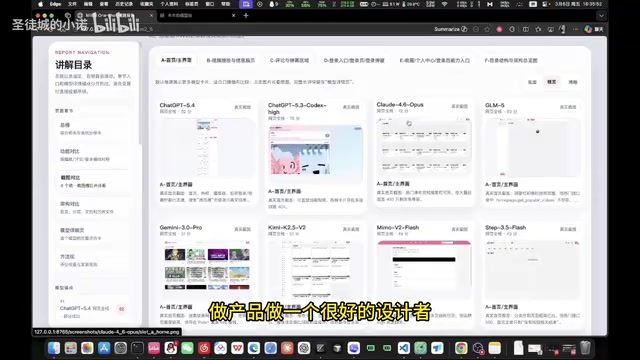
Gemini 3.0 Pro: Frontend Ceiling, Backend Bottleneck
Gemini 3.0 Pro's frontend fidelity was arguably "the best in the entire test." Its generated interface surpassed even Claude in details like video card layouts, author information display, and view count/duration formatting. However, it had a high backend error rate and left behind numerous junk files during development (uncleared historical versions), showing insufficient architectural discipline.
Interestingly, Gemini 3.1 Pro — the iterative successor — actually exhibited a regression: frontend capabilities noticeably declined, instruction adherence suffered, and real-world development ability fell short of the 3.0 Pro standard. Meanwhile, Gemini 3.0 Flash, with its reduced model size, lacked the intelligence to comprehend complex instructions, resulting in a significant drop in development capability.
Domestic Models: Can Build the Frame, Can't Fill the Content
Overall Performance & Common Issues
Domestic models exhibited a clear shared characteristic: they can scaffold the overall framework (top bar, sidebar), but rarely manage to actually implement the content in between.
- GLM5: Best overall among domestic models, with decent frontend and backend performance — essentially a "domestic Claude mini"
- Kimi K2.5 (official API): Strongest frontend among domestic models; some interfaces could even rival Gemini 3.0 Pro
- MiMo VR Flash: Xiaomi's LLM delivered mediocre results, ranking seventh
- Qwen 3.5 Plus: Performed below expectations, failing to fully implement even routing and pages
- DeepSeek V3.2: Returned raw JSON instead of rendered pages, essentially unable to complete the task
Two Important Warnings
First, third-party API deployment quality is concerning. The same Kimi K2.5 performed excellently via the official API but suffered roughly a 30% performance drop when deployed through third-party providers. The team suspects quantization deployment issues that severely degrade business comprehension capabilities. This is a reminder to developers: choose your API provider carefully — cheap may mean infinite wasted time.
Second, Doubao Seed 2.0 Pro has a tendency to "fake it." On the surface, the interface looks decent, but closer inspection reveals it's entirely mock data — repeated images, fabricated content. Rather than honestly indicating it couldn't complete the task, it papered over gaps with fake data.
Practical Development Recommendations
Based on the test results, the team proposed a tiered usage strategy:
| Scenario | Recommended Model | Reason |
|---|---|---|
| Backend development/refactoring | ChatGPT 5.4 | Rigorous logic, best architecture design |
| Frontend prototyping/UI replication | Gemini 3.0 Pro / Claude 4.6 | Strong design comprehension |
| Comprehensive rapid prototyping | Claude 4.6 Opus | Balanced frontend and backend |
| Domestic alternatives | Kimi K2.5 (official) + GLM5 | Kimi for frontend, GLM5 for backend with multiple iterations |
| SVG/icon design | Gemini 3.1 Pro | Optimized for this specific niche |
The most critical takeaway: Even a top-tier model like Claude 4.6 Opus cannot guarantee 100% instruction adherence. Developers must diligently perform Code Review, verifying that every feature is actually implemented rather than being misled by polished UI appearances.
Conclusion
This test reveals an important truth: there is a significant gap between benchmark scores and real-world development capability. A model's true ability is only fully exposed in complex, ambiguous tasks that closely mirror real scenarios. The current best practice for AI-assisted programming isn't betting on a single model, but combining models based on task characteristics — let the architecture expert handle architecture, the design expert handle design, and have human developers serve as the final quality gatekeepers.
Related articles
 Product Reviews
Product ReviewsQoder vs Cursor Real-World Comparison: Which $20/Month AI IDE Is Better?
Hands-on comparison of Qoder vs Cursor AI IDEs: Agent autonomy, human interaction count, and architecture decisions. Qoder needed only 2 interactions vs Cursor's 8.
 Product Reviews
Product ReviewsCursor Cloud Agent Demo: Eliminating Bottlenecks Across the Entire Software Development Lifecycle
Deep analysis of Cursor's Cloud Agent demo showing how cloud VMs, automated test artifacts, and a full-chain control plane systematically eliminate human bottlenecks across the software development lifecycle.
 Product Reviews
Product ReviewsCursor 3.0 Deep Dive: Multi-Agent Parallelism, Design Mode, and Best-of-N Model Comparison
Cursor 3.0 evolves from an AI coding assistant into an Agent fleet command center. Explore multi-agent parallelism, Design Mode, and Best-of-N model comparison.