NVIDIA免费调用DeepSeek V4 Pro教程:API密钥获取与编程工具接入

DeepSeek V4发布Pro与Flash两款模型,可通过NVIDIA NIM免费调用API。
DeepSeek V4正式上线,推出1.6万亿参数的旗舰Pro和2840亿参数的轻量Flash两款MoE架构模型,均支持100万Token上下文窗口。开发者可通过NVIDIA NIM平台免费获取API密钥进行原型开发,API完全兼容OpenAI标准,可直接接入Cursor、Kline等主流编程工具。推理努力值参数支持灵活调整推理深度,Pro适合复杂推理和智能体编程,Flash适合轻量快速任务。
DeepSeek V4 正式上线,带来了旗舰级的 V4 Pro 和轻量级的 V4 Flash 两款模型。更让开发者兴奋的是,通过 NVIDIA NIM 平台可以几乎免费地调用这两款模型,无需自建 GPU 环境,也无需立即按 Token 付费。本文将详细介绍 DeepSeek V4 的模型特性、API 密钥获取流程以及在主流编程工具中的实际接入方法。
DeepSeek V4 两款模型对比:Pro vs Flash
V4 Pro:1.6万亿参数的旗舰大模型
DeepSeek V4 Pro 采用混合专家模型(MoE)架构,总参数量高达 1.6万亿,激活参数量约为 490亿,支持高达 100万 Token 的上下文窗口。这个规模相当惊人,适用于高难度推理、编程、长上下文处理、智能体(Agent)、工具调用、文档分析等追求极致体验的场景。
混合专家模型(Mixture of Experts, MoE)是一种稀疏激活的神经网络架构,其核心思想是将模型拆分为多个"专家"子网络,每次推理时只激活其中一小部分专家来处理输入。这就是为什么 V4 Pro 虽然总参数量高达 1.6 万亿,但实际激活参数仅约 490 亿——一个门控网络(Gating Network)会根据输入内容动态选择最相关的专家组合。这种设计的优势在于:模型可以拥有海量知识储备(体现在总参数量上),同时保持合理的计算开销(体现在激活参数量上)。Google 的 Switch Transformer 和 Mixtral 都采用了类似架构。MoE 的挑战在于训练稳定性和专家负载均衡——如果某些专家被过度使用而其他专家闲置,模型效率会大打折扣。DeepSeek 在 V3 时代就在这方面做了大量优化工作,包括引入辅助损失函数来确保专家被均匀调用。
V4 Flash:轻量高效的速度之选
V4 Flash 的总参数量为 2840亿,激活参数约为 130亿,同样支持 100万 Token 上下文窗口,但在设计上更追求速度与效率。适合文档总结、小脚本编写、快速对话响应、路由分发等轻量任务。
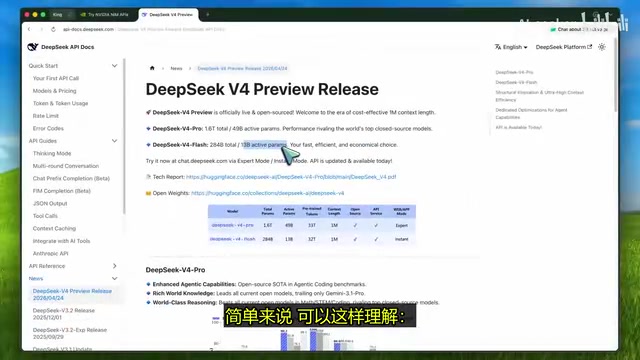
简单来说:追求最佳质量选 Pro,追求速度和低成本选 Flash。并非所有任务都需要 1.6万亿参数的模型——如果只是总结文档或写个小脚本,Flash 可能是更明智的选择。但面对大型代码库排查、疑难 Bug 调试、复杂计划制定或智能体编程,Pro 版本则是首选。
通过 NVIDIA NIM 免费获取 API 密钥
NVIDIA NIM(NVIDIA Inference Microservices)是 NVIDIA 于 2024 年推出的推理服务平台,旨在让开发者能够以标准化的方式部署和调用各种 AI 模型。NIM 将模型打包为优化过的容器镜像,内置了 TensorRT-LLM 等推理加速引擎,可以在 NVIDIA GPU 上实现接近硬件极限的推理性能。build.nvidia.com 是其云端托管版本,开发者无需自行配置 GPU 服务器即可通过 API 调用模型。NVIDIA 提供免费的开发者计划额度,本质上是为了推广其 GPU 生态和推理技术栈——当开发者验证完原型后,如果要上生产环境,自然会考虑购买 NVIDIA GPU 或使用其商业推理服务。
注册流程与密钥获取步骤
整个流程非常简洁:
- 访问 build.nvidia.com,搜索 "DeepSeek V4"
- 你会看到 DeepSeek V4 Pro 和 DeepSeek V4 Flash 两个模型卡片
- 点击进入模型页面(如有第三方模型警告,阅读后继续即可)
- 可以先在浏览器中直接测试模型,确认运行正常
- 点击 "获取 API 密钥",系统会引导你登录或注册 NVIDIA 账户
- 此操作会自动为你注册 NVIDIA 开发者计划,获取免费开发权限
- 复制 API 密钥并妥善保存
需要特别强调的是,NVIDIA 将此定义为通过开发者计划免费调用 NIM 端点进行原型开发。这意味着它非常适合测试应用、编写工作流或制作演示 Demo,但不应将其作为无限制的生产环境后端。免费 API 的模型可用性、速率限制及服务条款可能随时变动。
API 调用方式(兼容 OpenAI 标准)
该 API 完全兼容 OpenAI 接口标准,这意味着你可以直接使用 OpenAI SDK 进行调用:
- Base URL:
integrate.api.nvidia.com/v1 - Chat Completions 端点:
integrate.api.nvidia.com/v1/chat/completions - 模型名称(NVIDIA 平台):
deepseek-ai/deepseek-v4-pro和deepseek-ai/deepseek-v4-flash
OpenAI 的 Chat Completions API 格式(包括 /v1/chat/completions 端点、messages 数组结构、role/content 字段等)已经成为大语言模型行业的事实标准。几乎所有主流 LLM 提供商——包括 Anthropic(通过适配层)、Google Gemini、Mistral、以及各种开源模型的托管服务——都提供了与 OpenAI 格式兼容的 API。这种标准化带来的好处是巨大的:开发者只需编写一次集成代码,就可以在不同模型之间自由切换,而无需重写调用逻辑。LiteLLM、OpenRouter 等中间件项目正是基于这一标准构建的,它们进一步简化了多模型管理的复杂度。
⚠️ 注意命名差异:在 DeepSeek 官方 API 上,模型名称是 deepseek-v4-pro 和 deepseek-v4-flash;而在 NVIDIA NIM 中,模型名称带有提供商前缀。一旦名称输入错误,工具可能会报错或无法识别。
推理努力值(Reasoning Effort)参数详解
这是 DeepSeek V4 端点支持的一个非常实用的参数,可以在不切换模型的情况下灵活调整推理深度:
| 值 | 说明 | 适用场景 |
|---|---|---|
| None | 关闭思考过程,响应速度最快 | Flash 轻量任务 |
| High(默认) | 标准推理能力 | 日常编程、一般任务 |
| Max | 最强推理表现,但速度较慢 | 高难度推理、复杂调试 |
推理努力值参数的底层机制与"思维链"(Chain-of-Thought, CoT)推理密切相关。当设为 Max 时,模型会在生成最终答案前进行更长、更深入的内部推理过程,类似于人类面对难题时会花更多时间思考。这一特性源自 DeepSeek R1 引入的强化学习训练范式——通过奖励模型在推理过程中展现出的逐步分析能力,使模型学会了"慢思考"。设为 None 时则跳过这个推理过程,直接生成答案,大幅提升响应速度但牺牲了复杂问题的准确性。这个参数本质上是在推理质量和延迟之间提供了一个可调节的旋钮,让开发者无需为不同难度的任务部署不同的模型。
同款模型可根据不同推理努力值灵活调整表现。对于 Flash,通常选 None 或 High;对于 Pro,写普通代码设为 High,遇到难题就设为 Max。
关于 Token 限制的提醒
虽然模型支持 100万 Token 的上下文窗口,但 NVIDIA 端点目前将输出 Token 上限设为 16384。不同托管平台提供的上限可能不同,即便底层模型支持超大上下文也是如此。
100 万 Token 的上下文窗口意味着模型理论上可以一次性处理约 75 万个英文单词或数百万行代码。但在实际应用中,存在多重限制。首先是计算成本:注意力机制的计算复杂度与上下文长度呈二次方关系(尽管 FlashAttention、Ring Attention 等技术在缓解这一问题),处理超长上下文的推理时间和 GPU 显存消耗都非常可观。其次是"大海捞针"问题——研究表明,当上下文过长时,模型对中间位置信息的关注度会下降(即"Lost in the Middle"现象)。此外,各托管平台出于成本和稳定性考虑,通常会设置远低于理论上限的实际限制。
AI 编程工具通常不会发送完整代码库,而是通过文件分块、总结上下文或设定提示词长度限制来处理——这本质上是一种 RAG(检索增强生成)策略,只将最相关的代码片段送入模型。因此,100万上下文应视为该系列模型的理论上限,实际使用中受工具和端点的约束。
在编程工具中接入 DeepSeek V4
Kline CLI 接入方法
操作最为简洁:
- 打开 Kline CLI,运行配置命令
- 选择 NVIDIA 作为提供商
- 粘贴 NVIDIA API 密钥
- 运行 Models 命令,选择 DeepSeek V4 Pro 或 V4 Flash
连接一次后,即可在模型间自由切换。
通用接入方法(适用于 Cursor、Roo Code、Aider 等)
如果工具内置的 NVIDIA 接口尚未更新模型列表,可以手动选择 OpenAI 兼容模式进行配置:
- Base URL:
integrate.api.nvidia.com/v1 - API Key:你的 NVIDIA Key
- Model:
deepseek-ai/deepseek-v4-pro或deepseek-ai/deepseek-v4-flash
这种方法适用于所有支持自定义 OpenAI 兼容接口的工具,包括 Cursor、Roo Code、Aider、LiteLLM 等。这也正是 OpenAI 兼容 API 的核心价值——虽然模型不同、厂商也不同,但集成方式完全一致。对于开发者而言,这意味着评估新模型的成本极低:只需修改 Base URL 和模型名称,无需改动任何业务代码。
V4 Pro 与 V4 Flash 使用场景选择指南
V4 Flash 的典型场景
- 快速解读代码库、微调代码片段
- 总结文档、编写简单测试用例
- 生成 Git 提交信息
- 从长文本中提取关键内容
- 作为路由模型,将复杂任务分发给 Pro 处理
V4 Pro 的典型场景
- 真正的智能体编程:审视项目、梳理架构、理解现有模式
- 实现完整功能并运行测试
- 调试棘手问题(跨文件、跨模块的复杂 Bug)
- 处理海量上下文:长篇设计文档、API 文档、多语言文件
对比测试建议
想真正了解两款模型的差异,不要只随手问个问题。建议将它们放到同样的实际工作流中对比:让它们实现同一个功能、修复同一个 Bug、总结同一份长文档,然后对比速度、准确性以及后续需要花多少精力去修补。这比单纯跑基准测试有意义得多。
DeepSeek V4 发布为何值得关注
DeepSeek 由中国量化投资公司幻方量化(High-Flyer)创立,自 2023 年以来迅速崛起为全球最具影响力的开源 AI 实验室之一。其发展路径极具标志性:DeepSeek V2 首次展示了 MoE 架构在降低推理成本方面的巨大潜力;V3 以极低的训练成本(据报道约 550 万美元)达到了与 GPT-4 级别模型相当的性能,震动了整个行业;R1 则证明了通过强化学习可以让模型自主发展出推理能力,其开源权重被广泛用于学术研究和商业应用。DeepSeek 的每次发布都在挑战一个行业假设——即只有拥有数十亿美元预算的公司才能训练出顶级大模型。这种"高效训练"的路线对 OpenAI、Google 等巨头形成了显著的竞争压力,也为全球开发者社区提供了可替代的高质量选择。
从 V3、R1 彻底改变市场风向,到 V3.2 提升长上下文与注意力机制表现,再到 V4 将重心转向长上下文智能体、代码编写、工具调用以及复杂推理工作流——每一步都在推动行业前进。
NVIDIA 通过 NIM 托管该模型,让测试变得极其简单。开发者无需等待各类编程工具逐一适配 DeepSeek V4,只要工具支持 OpenAI 兼容端点,通常都能直接接入。对于学生、独立开发者以及想要快速验证想法的团队来说,这是一个零成本试用顶级大模型的绝佳机会。
核心要点
- DeepSeek V4 推出 Pro(1.6万亿参数)和 Flash(2840亿参数)两款模型,均支持100万Token上下文窗口
- 通过 NVIDIA NIM 平台可免费调用这两款模型的 API,适用于原型开发和测试,但不适合生产环境
- API 完全兼容 OpenAI 标准,可直接用于 Cursor、Kline、Roo Code 等主流编程工具
- 推理努力值(None/High/Max)参数允许在同一模型上灵活调整推理深度与响应速度
- NVIDIA 端点输出 Token 上限为 16384,实际使用中需注意各平台的限制差异
相关推荐
 教程攻略
教程攻略Cursor+Codex双IDE协同:开源项目二开实战方法论
基于实战经验总结的开源项目二次开发完整方法论,详解Cursor+Codex双IDE协同工作流,涵盖二开七环节、MVP验证、AI读源码技巧,帮助开发者三天跑通项目、两周完成业务集成。
 教程攻略
教程攻略Cursor多Agent实战:50分钟搭建Next.js全栈博客
使用Cursor IDE多Agent协作模式,50分钟内从零搭建全栈博客。涵盖Next.js、Clerk认证、Supabase数据库集成,详解4个AI Agent分阶段开发流程与关键避坑经验。
 教程攻略
教程攻略从零搭建AI软件工厂:Cursor工程师的多Agent协作实战经验
Cursor工程师Eric分享AI软件工厂构建实战:从自动化六层级、护栏设计、并行Agent管理到规模化扩展,详解如何用多Agent协作实现7×24小时高效软件开发。