TRAE vs Claude Code实测:嵌入式内存溢出谁能修好?
Claude Code在嵌入式内存对齐难题中胜过TRAE,找到真正根因并修复。
一位开发者用NRF52840蓝牙模块的内存溢出崩溃问题,对比测试了Claude Code和TRAE(均使用DeepSeek V4 Pro模型)的排查能力。Claude Code经过一小时深度调试,精准定位到C++的new运算符不满足ARM Cortex-M4的8字节栈对齐要求这一根因,用Zephyr的k_malloc()替换后彻底解决。TRAE虽也接近真相,但最终选择了关闭硬件栈保护的折中方案,牺牲了安全性。
背景:一个棘手的嵌入式内存溢出难题
在嵌入式开发领域,AI编程工具的实际表现到底怎么样?一位开发者用亲身经历给出了答案。他在用NRF52840蓝牙模块开发蓝牙外设时,添加了一个Event Manager模块用于在不同Task之间传递消息。然而只要一启用该模块,单片机程序就会崩溃——之前用TRAE+Kimi、GPT-4等工具排查,结论都指向"内存溢出",但始终无法定位根因,最终被归结为"RTOS版本可能有Bug"。
这次,他决定做一个公平对比:TRAE + DeepSeek V4 Pro vs Claude Code + DeepSeek V4 Pro,同一个模型、不同的Agent框架,看谁能真正解决这个底层硬件问题。
实验环境与测试设计
硬件与工具链配置
- 芯片:NRF52840(ARM Cortex-M4内核)
- 调试器:J-Link,通过RTT和SWD进行固件下载与调试
- 操作系统:Zephyr RTOS
- 开发语言:C++(这是问题的关键伏笔)
- 模型:双方均使用DeepSeek V4 Pro,1M上下文窗口
关于NRF52840与ARM Cortex-M4的内存对齐机制
ARM Cortex-M4是一款广泛应用于嵌入式系统的32位处理器内核,其内存访问对对齐有严格要求。所谓"8字节对齐",是指某些数据结构或栈帧的起始地址必须是8的整数倍。这一要求源于ARM架构的AAPCS(ARM Architecture Procedure Call Standard)规范——在函数调用边界,栈指针(SP)必须保持8字节对齐,否则浮点运算、SIMD指令或某些原子操作会触发Usage Fault异常,导致程序崩溃。NRF52840作为Nordic Semiconductor的旗舰蓝牙SoC,集成了Cortex-M4F(带浮点单元),对对齐的敏感度更高。当Zephyr RTOS创建线程时,内核会严格校验传入的栈缓冲区地址是否满足对齐约束,一旦违反即触发硬件级异常——这正是本案例崩溃的底层物理原因。
对比规则
两个工具使用完全相同的提示词,从同一份未修复的代码仓库出发,独立排查并修复问题。由于只有一套硬件设备,Claude Code先行,TRAE随后。
Claude Code排查过程:一小时深度攻坚
初步分析与首次尝试
Claude Code首先定位到调用链,发现Event Manager启动时Task的栈大小为8192字节(8KB),并详细计算了各组件的内存占用:事件对象约50字节、Task信息约100字节、消息队列缓冲区约544字节,加上线程栈本身的8192字节,总量已经超标。
它建议将栈扩大到20KB。编译烧录后——依然崩溃。串口无输出,USB设备无法枚举。
深入调试与关键发现
Claude Code没有放弃,转而使用J-Link进行底层调试,捕获到了Usage Fault异常。经过反复的断点设置、代码回退验证、最小化测试,它逐步缩小了问题范围。
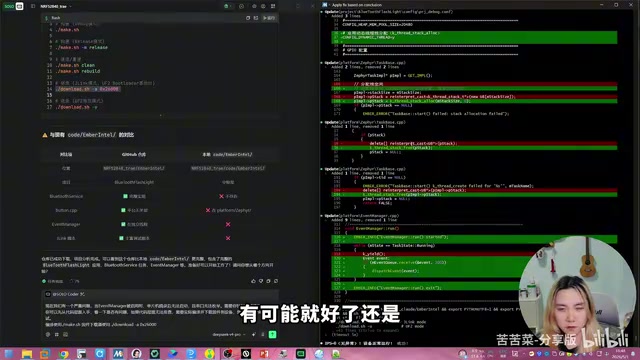
最终,Claude Code找到了真正的根因:C++的new运算符分配的内存不满足ARM Cortex-M的8字节栈对齐要求。在Zephyr RTOS中,线程栈有严格的对齐约束,而C++标准的new并不保证这种对齐,导致线程启动时发生非法内存访问。
修复方案与k_malloc的设计哲学
修复只改了两处:
- 将
new替换为Zephyr专用的k_malloc()分配函数 - 将
delete替换为k_free()
烧录验证——问题解决,设备正常工作。整个过程耗时约1小时。
为什么k_malloc()能解决问题?
Zephyr是Linux基金会旗下的开源实时操作系统,专为资源受限的嵌入式设备设计。
k_malloc()是Zephyr内核提供的堆内存分配函数,其内部实现会自动保证返回地址满足平台所需的对齐约束(通常为8字节或更高),同时与Zephyr的内存保护单元(MPU)和栈哨兵机制深度集成。相比之下,C++标准库的new运算符在裸机或RTOS环境下通常调用底层的malloc(),而许多嵌入式工具链的malloc()实现并不保证满足RTOS内核的严格对齐要求。这也是为什么Zephyr官方文档明确建议在内核上下文中优先使用k_malloc()而非C++标准分配器的根本原因。
TRAE排查过程:快速但略显潦草
第一轮:快速给出"能用"的方案
TRAE的分析路径与Claude Code大致相同,也发现了结构体对齐问题和8字节对齐要求。但在具体策略上,TRAE更倾向于目标导向——它很快找到了一个"能用"的方案:将Event Manager的start调用移到on_start之后,调整线程创建顺序。
设备确实恢复了工作,但这个方案不符合实际设计需求。开发者追问后,TRAE进入了第二轮排查。
第二轮:接近真相但走了另一条路
在进一步分析中,TRAE也触及到了new在Zephyr中可能不适用的问题,甚至在思考过程中写出了关键线索。但最终它选择了另一条路:关闭硬件栈保护(Stack Canary)。
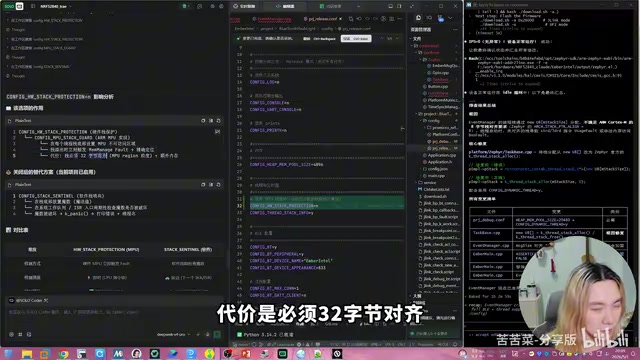
关闭栈保护后,C++的new分配的内存不再触发对齐检查,设备也能正常工作。TRAE还补充实现了软件栈哨兵机制——在栈底部放置魔术值,通过系统工作队列定期检查是否被破坏。
总耗时也约1小时,但中间经历了一次"强行结束"和人工追问。
Stack Canary与硬件MPU保护:两种机制的本质差异
栈保护是嵌入式系统防御栈溢出的两类主要机制,理解其差异对评估TRAE方案的风险至关重要。**Stack Canary(栈金丝雀)**是一种编译器插入的软件机制:在函数栈帧的返回地址前放置一个随机"哨兵值
相关推荐
 产品体验
产品体验Qoder vs Cursor实测对比:同样20美金谁更强?
实测对比Qoder和Cursor两款AI IDE,从Agent自主修复能力、人工沟通次数、架构决策等维度评测。Qoder仅需2次沟通完成任务,Cursor需8次。详细分析两者差异,帮你选择最适合的AI编程工具。
 产品体验
产品体验Cursor云Agent演示:打通软件开发全链路瓶颈
深度解析Cursor云Agent最新Demo,展示如何通过云端虚拟机、自动测试产物和全链路控制平面,系统性消除软件开发生命周期中的人类瓶颈,让Agent自主运行、人按需介入。
 产品体验
产品体验Cursor 3.0深度解析:多Agent并行、Design Mode与Best-of-N模型对比
Cursor 3.0正式发布,从AI辅助编程工具进化为Agent舰队指挥中心。本文详解多智能体并行、Design Mode可视化编辑、Best-of-N多模型择优等核心功能,解读AI编程新范式。