Transformer本质解析:一个被拆解的文字接龙函数

Transformer本质是将复杂的文字接龙函数拆解为三大模块的高效架构
Transformer的核心目的是实现"输入文字序列,预测下一个字"的文字接龙函数。由于直接训练如此复杂的函数不可行,它被拆解为三大模块:Embedding(词转高维向量并加入位置编码)、Transformer Block(通过多头注意力机制融合词间信息)、Probabilities(输出下一个词的概率分布)。Transformer脱颖而出的关键在于它具备Scaling Law特性,规模越大能力越强。
Transformer的核心思想:文字接龙游戏
Transformer的本质目的非常简单——找到一个函数,输入一堆文字,输出下一个字。找到这个函数后,把输出重新作为输入,循环往复,就能持续生成文本。这种生成方式被称为自回归(Autoregressive)生成,GPT系列模型都采用这一范式。
但问题是,语言有无数种排列组合,这个函数极其复杂。直接用一个大神经网络暴力训练?以目前人类的数据和算力,还做不到。
答案就是拆解。
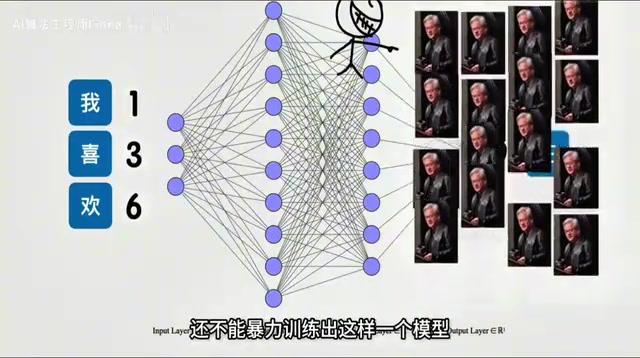
Transformer架构的三大模块
经过不断探索,人类发现将这个"文字接龙函数"拆解成Transformer架构,训练效果很好。整体分为三大块:
Embedding:把词转换为向量
把每个词从一个数字(编号)转换成一个向量(一组数字),提升信息维度。
具体来说,输入文本首先经过tokenizer(分词器)切分为token序列,每个token对应词表中的一个整数编号。然后通过一个可训练的嵌入矩阵,将每个编号映射为高维向量(如GPT-3使用12288维)。由于Transformer不像RNN那样逐步处理序列、天然感知顺序,还需要加入位置编码(Positional Encoding)来注入每个词的位置信息,让模型知道"谁在前谁在后"。
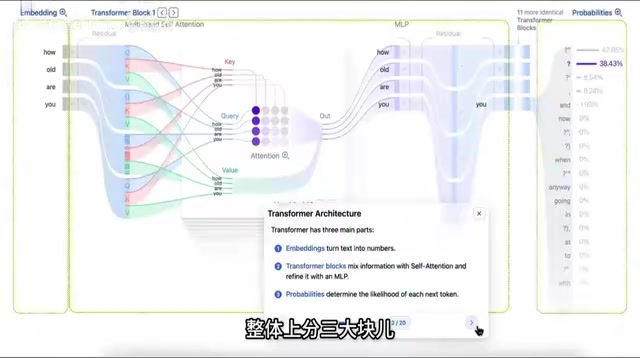
Transformer Block:通过注意力机制融合信息
通过注意力机制,让每个词向量都融入其他词向量的信息,实现"互相包含彼此的信息"。输出仍然是结构一样的词向量。
注意力机制的核心是Query-Key-Value结构:每个词生成查询(Q)、键(K)、值(V)三个向量,通过Q和K的点积计算词与词之间的相关性权重,再用这些权重对V加权求和。多头注意力(Multi-Head Attention)则是将这个过程并行执行多次,让模型能同时关注不同类型的语义关系(如语法关系、语义相似性等)。Transformer Block通常堆叠数十层甚至上百层,逐层提取越来越抽象的特征。
Probabilities:输出下一个词的概率
得到与词表大小相同的分数(logits),再根据温度、top-k等参数转换为概率,决定下一个词。
Logits是模型最后一层线性变换的原始输出,维度等于词表大小(如GPT-3的词表约5万个token)。温度(Temperature)参数控制概率分布的尖锐程度:温度接近0时模型几乎总选最高分的词,温度越高选择越随机、越有"创意"。Top-k采样则限制只从概率最高的k个词中选择,避免生成荒谬内容。这些都是推理时的解码策略,不影响训练过程。
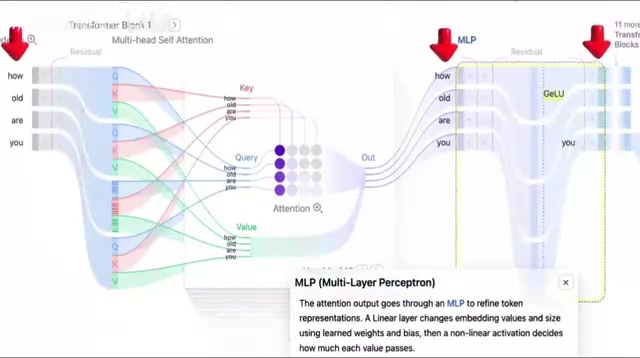
此外还有残差连接、层归一化、Dropout等训练技巧散布在各处。残差连接(Residual Connection)让每层的输入直接加到输出上,解决深层网络梯度消失问题;层归一化(Layer Normalization)稳定训练过程中各层的数值范围;Dropout则在训练时随机屏蔽部分神经元,防止过拟合。
为什么偏偏是Transformer?
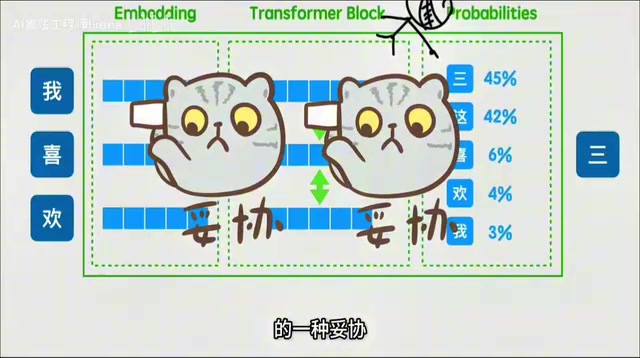
很多初学者都有这样的困惑:为什么一定是Transformer?
答案其实很朴素:能训练出效果,并且能产生规模效应(Scaling Law),就是好模型。 Transformer本质上是人类对算力和数据不足的一种妥协——如果算力无限,一个巨大的神经网络直接端到端训练就行了。
Scaling Law是OpenAI在2020年发表的重要发现:Transformer模型的性能与参数量、数据量、计算量之间存在可预测的幂律关系。只要持续增加规模,模型能力就会平滑且可预测地提升。这一特性让Transformer脱颖而出——早期的RNN、LSTM虽然也能处理序列,但扩大规模时收益递减明显,无法像Transformer这样"加资源就变强"。这也是GPT从1.17亿参数一路扩展到1750亿参数的理论依据。
当我们陷入模型细节时,往往忽略了它的输入输出任务本身非常简单明确。这个视角对理解深度学习模型至关重要。
核心要点
- Transformer的本质目的是实现一个文字接龙函数:输入文字序列,输出下一个字的概率
- 架构分三块:Embedding(词转向量+位置编码)、Transformer Block(多头注意力融合信息)、Probabilities(输出概率)
- Transformer是对"直接训练一个大函数"的拆解,本质是算力不足的妥协
- 好模型的标准:能训练出效果且具备Scaling Law特性——规模越大,能力可预测地越强
相关推荐
 深度解读
深度解读OpenClaw开源小龙虾AI Agent运作原理深度解析
深度解析OpenClaw(开源小龙虾)AI Agent的底层运作原理,涵盖System Prompt、工具调用、SubAgent分身、Skill系统、记忆机制与Context Engineering等核心概念,帮你彻底理解AI Agent与普通语言模型的本质区别。
 深度解读
深度解读Claude Code与普通AI对话的五大核心差异
详细对比Claude Code与普通AI对话工具在交互方式、上下文理解、执行力、记忆能力和工具调用五个维度的核心差异,帮你理解AI编程助手的真正价值。
 深度解读
深度解读MCP与A2A协议详解:智能体互联互通的USB时代
深入解析MCP(模型上下文协议)与A2A(智能体间协议)的架构原理、核心功能与协作关系,帮助开发者理解智能体如何通过通用协议实现即插即用的互联互通。