UpCtl技术实现详解:Tmux+SSH如何驱动AI Agent自动化部署
UpCtl通过Tmux、混合云架构和四级知识库实现AI Agent驱动的全自动开发部署平台
UpCtl是一套AI Agent驱动的全自动开发测试部署平台,其核心技术包括:利用Tmux的Session独立性和send-keys机制实现Agent的稳定运行与通信;基于Rust的Service层将Agent抽象化,支持本地直连、SSH远程和多跳隧道三种连接方式;通过NPS反向穿透构建混合云架构;以及用提示词模板、Memory知识库、项目描述和工作报告组成的四级知识体系替代传统RAG方案,通过Ticket驱动实现自动化闭环。
引言
在上一期视频中,开发者阿南介绍了自主研发的开源项目 UpCtl 的设计目标和技术架构。本期深入到具体的技术实现细节,看看这套 AI Agent 驱动的全自动开发测试部署平台在底层到底是怎么跑起来的。从 Tmux 的 Session 管理机制,到混合云架构下的 SSH 隧道穿透,再到四级知识库的设计思路,每一个技术选型背后都有明确的工程考量。
Tmux:AI Agent 稳定运行的基石
Session 与窗口的独立性
整个系统的核心设计之一,是将 AI Agent 运行在 Tmux 之上。Tmux(Terminal Multiplexer)是一款终端复用器,最早由 Nicholas Marriott 于 2007 年开发,作为 GNU Screen 的现代替代品。它的核心架构采用 C/S 模型:一个 Tmux Server 进程在后台运行,管理所有 Session,而用户通过 Tmux Client 连接到这些 Session。这种架构意味着即使所有客户端断开连接,Server 进程和其中运行的程序仍然存活——在 DevOps 和服务器运维领域,Tmux 被广泛用于保持长时间运行的任务不因 SSH 断连而中断。
Tmux 最大的特点在于 Session 和运行窗口彼此独立。举个例子,当你创建一个名为 "Test" 的 Tmux Session 后,可以在一个终端中运行它,同时在另一个终端通过 tmux attach 连接到同一个 Session——两个终端窗口会完全同步,效果类似纯文字版的 VNC。
这种特性对 UpCtl 系统至关重要。将 DeepSeek TUI 这个 Agent 运行在 Tmux Session 中,可以确保:
- 其他进程可以随时通过 Tmux attach 连接到 Agent 窗口
- 任何单个连接断开都不会导致 Session 本身被关闭
- Service 层可以稳定地从 Web 端获取 Ticket 并将 Prompt 发送给 Agent
Tmux 的文本发送能力
Tmux 还有一项关键能力:它可以通过 send-keys 命令向自己的 Session 发送文本信息。Service 层正是利用这一特性,通过 Tmux 命令向 DeepSeek TUI 窗口发送实际的 Prompt 并触发执行。换句话说,Service 层不需要跟 Agent 做复杂的 API 交互,只需要借助 Tmux 的文本注入机制就能完成通信。UpCtl 巧妙地将这一传统运维工具转化为 AI Agent 的运行时基础设施,这是一种非常规但极其实用的工程选择——它将进程间通信的复杂性降到了最低,同时保留了完整的可观测性(任何人都可以 attach 到 Session 实时观看 Agent 的工作过程)。
Service 层的抽象设计
Agent 作为抽象概念
在 UpCtl 的架构设计中,Service 层对 Agent 的认知是完全抽象的。它既不假设所使用的具体 Agent 是什么,也不假设 Service 和 Agent 部署在同一台主机上。Service 层只需要做三件事:
- 从外部端读取 Ticket 中的内容
- 连接到 Agent
- 使用 Tmux 命令发送 Prompt
至于 Agent 具体如何工作——比如它可能会调用其他 Agent(如 OpenAI Cloud)——Service 层完全不关心。这种解耦设计让系统具备了很高的灵活性和可扩展性。这里的 DeepSeek TUI 是一种 TUI(Text User Interface,文本用户界面)形态的 AI Agent,它在终端环境中以交互式方式接收输入并产生输出,与 Tmux 的文本发送机制天然兼容。在 AI Agent 架构领域,当前主流方案(如 LangChain、AutoGPT、CrewAI)通常通过 API 调用实现 Agent 编排,而 UpCtl 选择基于终端文本交互的方式驱动 Agent,本质上是一种 Unix 哲学的回归——将复杂系统拆解为通过文本流通信的简单组件。
三种 Agent 连接方式
在 UpCtl SVC 这个开源项目中,有一个专门的抽象 Agent 模块负责适配各种部署环境。目前默认支持三种连接方式:
- 本地 Tmux 托管的 Agent 直连:Agent 和 Service 运行在同一台主机,直接 Tmux attach 即可
- SSH 远程登录:Agent 在不同主机上,通过 SSH 登录后调用 Tmux 命令
- SSH 多跳隧道穿透:适用于更复杂的网络拓扑,支持跳板机场景(即通过 SSH 的 ProxyJump 或 ProxyCommand 机制,经由一台或多台中间主机逐级跳转到目标主机)
整个 Service 中间层基于 Rust 实现。Rust 语言以内存安全和零成本抽象著称,在 Service 中间层这类需要长期稳定运行、处理并发连接的场景中,其所有权系统从编译期就消除了数据竞争和内存泄漏的可能性,无需垃圾回收器的运行时开销。Rust 生态中的 tokio 异步运行时和 SSH 相关库(如 russh)为构建高并发的 SSH 连接管理提供了成熟的基础设施,这使得 Service 层在处理多个 Agent 连接时能保持极低的资源占用和极高的稳定性。值得一提的是,这个 Service 层是由开发者提出需求后,AI 自我迭代开发完成的。
混合云架构的实际部署
NPS 反向穿透方案
在实际业务环境中,UpCtl 采用了一套混合云部署架构。以项目 Demo 为例:
- Agent(DeepSeek TUI) 部署在本地的 Mac Studio 上,因为这台主机性能强劲,适合执行高性能计算任务
- Service 层和 Web 端 部署在公网云主机上
- 通过 NPS 将局域网内的 Mac 主机暴露给云主机
NPS 是由 cnlh 开发的基于 Go 语言的轻量级内网穿透工具,支持 TCP/UDP 隧道、HTTP 代理、SOCKS5 代理等多种穿透模式。它解决的核心问题是让没有公网 IP 的内网设备能够被外部访问。其工作原理是:内网客户端主动向公网服务端建立长连接,当外部请求到达服务端时,服务端通过已建立的连接将流量转发到内网客户端。相比 ngrok、Cloudflare Tunnel 等商业方案,NPS 完全开源自托管,适合对数据安全和网络控制有要求的场景。
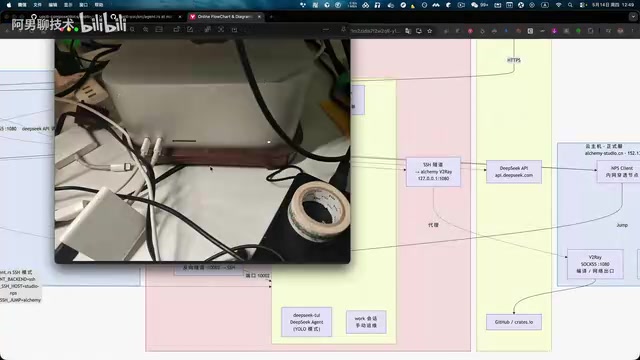
云主机部署 NPS Server,本地主机部署 NPS Client,实现反向穿透。这样云主机上的 Service 层就可以通过 SSH 反向登录到局域网内的 Mac 主机,调用其上的 Agent。NPS 的资源占用非常小,性能也不错,很适合混合云场景。
这种架构的好处在于:Agent 既能访问云主机上的所有资源(包括代码仓库和部署服务),又能充分利用本地强大的计算能力。这实际上是一种"计算在边缘、调度在云端"的混合部署模式,在 AI 推理和开发编译等计算密集型任务中尤其有价值。
Ticket 工作流的完整链路
创建与分发
一个典型的 Ticket 工作流程如下:
- 创建 Ticket:填写标题、工作内容,可上传 PDF、Word、截图等附件
- 关联项目:选择在项目管理中维护的关联项目,项目信息包含仓库地址和必要的 Memory 信息(如部署环境等)
- 审批与执行:Ticket 创建后需要批准,系统自带定时脚本会定期查找已批准但未处理的 Ticket,通过 Tmux 机制发送给 Agent
Agent 容器内还有默认的 Health Check 机制,持续检查 Tmux Agent Session 的可用性。此外,Ticket 页面还提供了"直接开始处理"按钮,点击后会立即向 Agent 发送 Prompt 开始工作。
自动化闭环
当 Agent 接收到 Prompt 并开始工作后,整个流程是全自动的:
- Agent 通过 Service 层自动在 Ticket 下添加评论
- 工作完成后,Agent 通过 Service 层关闭 Ticket
- 在 Ticket 下撰写完整的工作报告
这种 Ticket 驱动的自动化闭环与传统 CI/CD 流水线(如 Jenkins、GitLab CI、GitHub Actions)有本质区别:传统流水线执行的是预定义的确定性步骤,而 UpCtl 的 Ticket 系统驱动的是一个具备推理能力的 AI Agent,它可以根据 Ticket 描述自主决定开发、测试和部署的具体步骤,具备处理模糊需求和异常情况的能力。
四级知识库:不用向量数据库的 RAG 替代方案
提示词模板的作用
Agent 接收到的 Prompt 并不只是 Ticket 正文内容,前面还会插入一大段前置内容——也就是提示词模板。这个模板会固定插入到每轮对话的开头,主要用来保证测试、开发和部署行为的稳定性。
模板中只放最核心的内容,不宜过长。由于提示词模板不会经常更新,属于每轮固定插入的内容,配合 DeepSeek 大模型使用时缓存命中率很高,能有效降低推理成本。这里的缓存机制类似于 Anthropic 推出的 Prompt Caching 技术——当 Prompt 的前缀部分在多次请求中保持不变时,模型服务端可以缓存该部分的 KV Cache(键值缓存),后续请求只需计算变化的部分,从而大幅减少计算量和响应延迟,通常可节省 80%-90% 的前缀处理成本。
四级知识体系
整套系统没有使用向量数据库构建传统的 RAG 知识库,而是通过四级知识库协同配合。传统 RAG(Retrieval-Augmented Generation,检索增强生成)方案通常依赖向量数据库(如 Pinecone、Milvus、Weaviate)将文档切片后转化为高维向量,在推理时通过语义相似度检索相关片段注入上下文。然而 RAG 存在若干工程痛点:向量化过程中的信息损失、检索精度与召回率的平衡、chunk 切分策略的调优,以及向量数据库本身的运维成本。UpCtl 选择的四级知识库方案本质上是一种结构化的上下文工程(Context Engineering),通过人工组织和分层管理知识,以确定性的方式将信息注入 Prompt,避免了向量检索的不确定性。
| 层级 | 名称 | 说明 |
|---|---|---|
| 第一级 | 提示词模板 | 固定插入的核心指令,保证行为稳定性 |
| 第二级 | Memory 知识库 | 指定目录下的详细文档,以 Markdown 形式保存,方便 AI 调取参考 |
| 第三级 | 项目描述信息 | 在项目管理中维护的仓库地址、部署环境等结构化信息 |
| 第四级 | Ticket 工作报告 | 历史 Ticket 的执行记录和总结 |
Memory 文档本身也是一个项目,随着开发进度和部署环境的变化需要不断更新——而这个更新过程同样由 Ticket 系统自我迭代完成,人只需要创建 Ticket 并指导 Agent 完成工作。这种"知识库自我维护"的设计形成了一个正向飞轮:Agent 在执行任务的过程中积累经验,这些经验又反哺到知识库中,使后续任务的执行质量不断提升。
实际效果与项目定位
从实际使用效果来看,Agent 的行为比较可控,通过这套项目的部署大幅提高了团队的工作效率,开发测试部署的自动化程度有了明显提升。
但开发者也坦诚指出:这套项目本质上是一套流水线工具,它并不能替代人的思考以及使用者的工程判断能力。 人的角色是创建 Ticket 并指导 Agent 完成工作,而非完全放手。这一定位与当前 AI Agent 领域的共识一致——在 Human-in-the-Loop(人在回路中)的协作模式下,AI 负责执行重复性和规范化的工作,人负责决策、审核和异常处理,两者形成互补而非替代关系。
项目已开源,提供了详细的文档和一键部署方案,感兴趣的开发者可以 clone 到本地快速体验。
核心要点
- UpCtl 利用 Tmux 的 Session 独立性和文本发送能力,实现了 AI Agent 的稳定运行和通信机制
- Service 层将 Agent 抽象化,支持本地直连、SSH远程和SSH多跳三种连接方式,基于 Rust 实现
- 通过 NPS 反向穿透构建混合云架构,将本地高性能主机的 Agent 与云端 Service 无缝连接
- 采用提示词模板、Memory知识库、项目描述和工作报告四级知识体系替代传统向量数据库 RAG 方案
- 整套系统定位为流水线工具,通过 Ticket 驱动 Agent 自动完成开发测试部署,但不替代人的工程判断
相关推荐
 教程攻略
教程攻略Cursor+Codex双IDE协同:开源项目二开实战方法论
基于实战经验总结的开源项目二次开发完整方法论,详解Cursor+Codex双IDE协同工作流,涵盖二开七环节、MVP验证、AI读源码技巧,帮助开发者三天跑通项目、两周完成业务集成。
 教程攻略
教程攻略Cursor多Agent实战:50分钟搭建Next.js全栈博客
使用Cursor IDE多Agent协作模式,50分钟内从零搭建全栈博客。涵盖Next.js、Clerk认证、Supabase数据库集成,详解4个AI Agent分阶段开发流程与关键避坑经验。
 教程攻略
教程攻略从零搭建AI软件工厂:Cursor工程师的多Agent协作实战经验
Cursor工程师Eric分享AI软件工厂构建实战:从自动化六层级、护栏设计、并行Agent管理到规模化扩展,详解如何用多Agent协作实现7×24小时高效软件开发。