v0新增权限模式:AI代码助手的安全控制升级
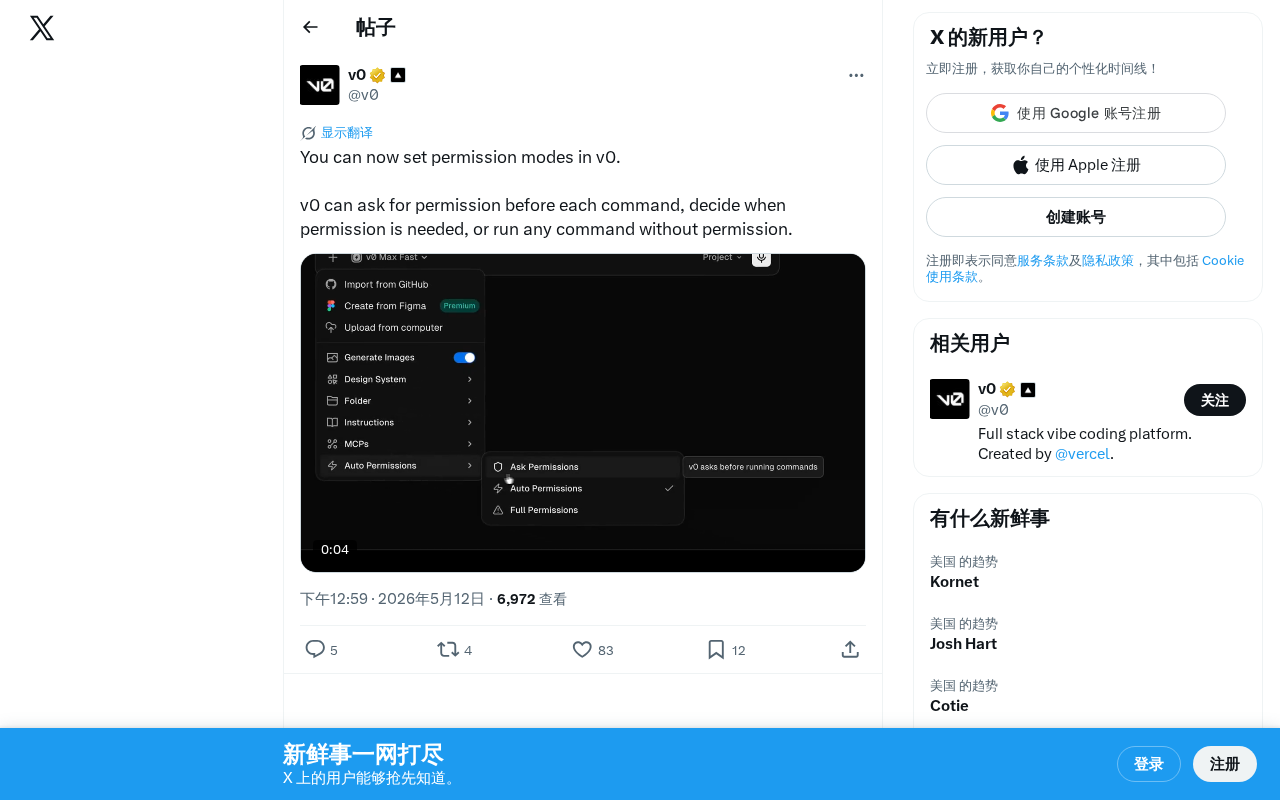
v0 权限模式功能上线
Vercel 旗下的 AI 编程工具 v0 近日推出了全新的权限模式(Permission Modes)功能,允许用户精细化控制 AI 在执行命令时的权限级别。这一更新标志着 AI 编程助手在安全性和用户控制方面迈出了重要一步。
v0 是 Vercel 于 2023 年推出的 AI 驱动开发工具,最初以生成 UI 组件和前端代码著称,用户只需用自然语言描述需求,v0 即可生成基于 React、Tailwind CSS 和 shadcn/ui 的可用代码。这里值得展开说明的是,这三项技术构成了当前前端开发的主流技术栈之一:React 是 Meta 开源的声明式 UI 框架,以组件化和虚拟 DOM 机制著称,目前在全球前端框架中占据最大市场份额;Tailwind CSS 是一种"实用优先"(utility-first)的 CSS 框架,通过预定义的原子类名直接在 HTML 中完成样式编写,极大提升了 AI 生成样式代码的可预测性和一致性;shadcn/ui 则是一套基于 Radix UI 原语构建的可复用组件库,其独特之处在于组件代码直接复制到项目中而非作为 npm 依赖安装,这使得 AI 生成的代码更易于定制和维护。
随着产品迭代,v0 逐渐从单纯的代码生成工具演变为具备终端命令执行、文件系统操作等能力的全栈 AI 编程代理。Vercel 本身是全球领先的前端云平台,为 Next.js 等框架提供部署和托管服务。Next.js 是 Vercel 核心维护的 React 全栈框架,支持服务端渲染(SSR)、静态站点生成(SSG)和增量静态再生(ISR)等多种渲染策略,是目前企业级 React 应用的首选框架。Vercel 推出 v0 是将 AI 能力深度整合到开发工作流中的战略举措——从代码生成到部署上线形成闭环,开发者可以在 Vercel 生态内完成从创意到上线的全流程。此次权限模式的上线,正是 v0 从代码生成工具向完整 AI Agent 演进过程中的关键安全基础设施。
三种权限模式详解
根据官方发布的信息,v0 现在提供三种不同的权限控制模式:
1. 逐条询问模式
v0 在执行每一条命令之前都会向用户请求许可。这是最保守的模式,适合对安全性要求极高的场景,或者用户希望完全掌控 AI 行为的情况。每一步操作都需要人工确认,确保不会出现意外的文件修改或系统操作。
这种模式的设计理念类似于操作系统中的 UAC(用户账户控制)机制——在 Windows 系统中,当程序试图进行可能影响系统的操作时,会弹出确认对话框要求用户授权。UAC 自 Windows Vista 引入以来,虽然曾因频繁弹窗被用户诟病,但它有效降低了恶意软件获取管理员权限的风险,成为操作系统安全架构的标准组件。在 AI Agent 的语境下,这意味着人类始终保持在决策回路中(human-in-the-loop)。Human-in-the-loop 是 AI 安全领域的核心设计模式,其核心思想是在 AI 系统的关键决策节点引入人类审核,确保 AI 的每一个动作都经过显式批准。这一模式在自动驾驶(L3 级别需要驾驶员随时接管)、医疗 AI(诊断建议需医生确认)等高风险领域已被广泛采用,如今正被移植到 AI 编程代理的权限管理中。
2. 智能判断模式
v0 自行判断何时需要请求权限。这是一种平衡效率与安全的中间方案——对于常规的、低风险的操作(如读取文件、生成代码片段),AI 可以自主执行;而对于可能产生重大影响的操作(如删除文件、修改配置、执行系统命令),则会暂停并征求用户同意。
智能判断模式的核心在于 AI 需要对操作进行风险评估分类。这通常通过以下方式实现:系统预定义一套操作风险分级规则(如只读操作为低风险,写入/删除操作为高风险),同时结合上下文语义理解来判断操作的潜在影响范围。例如,在项目根目录执行 rm -rf 与在临时目录中删除缓存文件,虽然都是删除操作,但风险等级截然不同。前者可能导致整个项目不可恢复地丢失,后者则是常规的清理操作。这种区分要求 AI 不仅理解命令本身的语义,还需要理解命令执行的上下文——包括当前工作目录、目标文件的重要性、操作是否可逆等因素。
这种模式本质上是一种"最小权限原则"(Principle of Least Privilege)的动态实现。最小权限原则是信息安全领域的基石概念之一,由 Jerome Saltzer 在 1974 年提出,其核心主张是:系统中的每个主体(用户、进程或程序)应当仅被授予完成其合法任务所需的最小权限集合。在传统软件工程中,这一原则体现为数据库用户的只读/读写权限分离、微服务之间的最小 API 暴露、容器运行时的非 root 用户配置等实践。将这一原则应用于 AI Agent,意味着 AI 在默认状态下只拥有最低限度的系统访问权限,仅在必要时通过显式授权获得更高权限。
智能判断模式还要求 AI 具备元认知能力——即对自身操作后果的预判能力。这是当前大语言模型研究中的前沿课题:模型不仅需要知道"如何做",还需要知道"做了之后会怎样"以及"这样做是否安全"。这种能力的实现可能依赖于模型的内部推理链(Chain of Thought),在执行操作前先进行一轮"后果模拟",评估操作的风险等级后再决定是否需要请求用户确认。
3. 自由执行模式
v0 可以在不请求任何权限的情况下运行任意命令。这种模式适合对 AI 高度信任的开发者,或者在沙盒环境中进行快速原型开发时使用。它提供了最高的工作效率,但相应地也承担了更大的风险。
所谓沙盒环境(Sandbox),是指与生产系统隔离的受控执行环境,即使 AI 执行了破坏性操作,影响范围也被限制在沙盒内部,不会波及真实的代码库或线上服务。沙盒技术在软件安全领域有着悠久的历史:浏览器使用沙盒隔离网页脚本以防止恶意代码访问本地文件系统,移动操作系统通过应用沙盒限制 App 之间的数据访问。在 AI 编程场景中,Docker 容器是最常用的沙盒载体——Docker 通过 Linux 内核的 namespace 和 cgroup 机制实现进程级隔离,AI Agent 在容器内拥有完整的文件系统和网络栈,但这些资源与宿主机完全隔离。此外,虚拟机(如基于 Firecracker 微虚拟机的方案)提供了更强的硬件级隔离,而 Git 分支则提供了版本控制层面的"逻辑沙盒"——AI 在独立分支上的所有操作都可以通过 git reset 一键回滚。v0 作为云端工具,很可能在后端采用了类似的容器化隔离方案,使得自由执行模式在受控环境下具备可接受的安全性。
为什么权限控制很重要
随着 AI 编程助手能力的不断增强,它们不再仅仅是代码补全工具,而是能够执行终端命令、修改文件系统、甚至与外部服务交互的智能代理(AI Agent)。
AI Agent 是指能够自主规划、执行多步骤任务的 AI 系统,区别于传统的单轮问答模型。从技术架构上看,AI Agent 通常由以下核心组件构成:一个大语言模型(LLM)作为"大脑"负责推理和决策;一套工具调用接口(Tool Use / Function Calling)使其能够与外部系统交互;一个规划模块(Planning)将复杂任务分解为可执行的子步骤;以及一个记忆系统(Memory)用于维护任务上下文。与传统的代码补全工具(如早期的 GitHub Copilot)相比,AI Agent 的本质区别在于"自主性"——它不仅能回答问题或补全代码片段,还能主动规划执行路径、调用多种工具、处理中间错误并迭代修正。这种自主性使得 AI Agent 的能力边界大幅扩展,但也意味着其行为的不可预测性显著增加。
当 AI Agent 被赋予执行终端命令、读写文件系统、调用 API 等能力时,它本质上获得了与人类开发者类似的系统访问权限。这带来了"对齐"(Alignment)问题的实际延伸——即如何确保 AI 的行为始终符合用户意图。AI 对齐是当前 AI 安全研究的核心议题,最初由 Stuart Russell 等学者在讨论超级智能风险时提出,指的是确保 AI 系统的目标和行为与人类价值观和意图保持一致。在 AI 编程代理的场景中,对齐问题表现得更为具体和紧迫:用户说"清理项目",AI 是应该删除 node_modules 和构建缓存,还是可能误解为删除整个项目目录?用户说"更新依赖",AI 是应该保守地进行补丁版本更新,还是激进地升级到最新主版本?这些看似简单的指令在实际执行中充满歧义,而权限控制机制正是解决这一问题的工程化方案。
权限控制类似于操作系统中的用户权限管理(如 Linux 的 sudo 机制),通过在 AI 与系统资源之间设置访问控制层来降低风险。Linux 的 sudo(superuser do)机制允许普通用户临时获取 root 权限执行特定命令,每次使用都需要密码验证,且所有操作都会被记录到系统日志中。这种"默认低权限、按需提权、全程审计"的设计哲学,正是 v0 权限模式所借鉴的安全模型。
在这种背景下,权限控制变得至关重要:
- 安全性:防止 AI 误操作导致数据丢失或系统损坏。近期已有多起案例报告显示,AI 编程助手在缺乏约束的情况下可能执行非预期的破坏性操作,例如误删关键配置文件或覆盖未提交的代码更改。在社区讨论中,有开发者报告 AI Agent 在尝试修复构建错误时,错误地修改了
.env环境变量文件导致生产数据库连接信息丢失;也有案例显示 AI 在执行git操作时意外地强制推送(force push)覆盖了团队成员的提交历史。这些事件凸显了权限控制的紧迫性。 - 可审计性:在逐条询问模式下,用户可以清楚了解 AI 的每一步操作,这对于合规要求严格的企业环境尤为重要。在金融、医疗、政府等受监管行业,SOC 2、ISO 27001 等安全合规框架要求所有系统变更都必须有完整的审计追踪(Audit Trail)。操作日志不仅记录了"谁在什么时间做了什么",还能在安全事件发生后用于根因分析和责任追溯。AI Agent 的操作审计日志可以作为安全审计的依据,证明所有代码变更都经过了人类审批。
- 灵活性:不同场景下可以选择不同的控制粒度,兼顾效率与安全。
行业趋势观察
这一功能的推出与当前 AI 编程工具领域的整体趋势一致。无论是 Cursor、Claude Code 还是其他 AI 编程助手,都在探索如何在赋予 AI 更大自主权的同时,保持人类对关键操作的最终控制权。
在具体实现上,各产品采取了不同策略。Cursor 是由 Anysphere 公司开发的 AI 原生代码编辑器(基于 VS Code 的分支),其 Agent 模式同样提供了类似的权限分级,允许用户设置自动执行或逐步确认。Cursor 的独特之处在于它深度集成了代码库索引功能,AI 在执行操作前能够理解整个项目的代码结构和依赖关系,这为更精准的风险评估提供了上下文基础。
Anthropic 的 Claude Code 采用了"允许列表"(Allowlist)机制,用户可以预先批准特定类型的操作(如 bash 命令、文件编辑),未在列表中的操作则需要逐次确认。这种白名单方式的设计哲学是"默认拒绝,显式允许"(deny by default, explicitly allow),与网络安全中防火墙规则的设计思路一脉相承。Claude Code 还引入了"逃逸键"机制,用户可以在 AI 执行过程中随时按 Escape 键中断操作,提供了一道额外的安全防线。
GitHub Copilot 的 Agent 模式也引入了类似的信任层级概念,并且借助 GitHub 平台的天然优势,可以将权限控制与仓库的分支保护规则、代码审查流程(Pull Request Review)相结合,形成从 AI 代码生成到人工审核再到合并部署的完整安全链条。
这些设计反映了行业共识:AI 编程代理需要在自主性和可控性之间找到平衡点,而将选择权交给用户是目前最务实的方案。这一共识的形成也受到了学术界关于"AI 可控性"(Controllability)研究的影响——斯坦福大学 HAI(Human-Centered AI)研究所等机构持续倡导,AI 系统的设计应当确保人类能够在任何时刻理解、干预和纠正 AI 的行为。
v0 的三级权限模式提供了一个清晰的框架,让用户可以根据自己的信任程度和使用场景灵活选择。
对于开发者而言,建议在生产环境相关的操作中使用逐条询问模式,在日常开发中使用智能判断模式,而将自由执行模式保留给隔离的实验环境。这种分层策略能够在保障安全的前提下最大化 AI 辅助编程的效率。随着 AI Agent 能力的持续提升,权限控制机制也将不断演进——未来可能出现更细粒度的权限配置(如按文件路径、按命令类型设置不同权限)、基于历史行为的动态信任评估(类似于信用评分系统,AI 的可信度随着无误操作的积累而逐步提升),以及团队级别的权限策略管理(允许技术负责人为团队统一配置 AI 权限策略,类似于企业 MDM 移动设备管理中的策略下发机制)等高级功能。
核心要点
相关推荐
Codex编程智能体全解析:和ChatGPT到底有什么区别?
深入解析OpenAI Codex编程智能体的核心能力,对比Codex与ChatGPT在编程场景中的本质区别,帮助开发者理解AI编程智能体如何改变软件开发模式。

Databricks开源Omni:统一管理所有AI Agent的元框架
Databricks以Apache 2.0协议开源Omni项目,通过元框架统一管理Claude Code、Codex等多个AI Agent。支持统一会话、跨供应商交叉审查、安全策略强制执行和实时协作,彻底解决多Agent协同与供应商锁定问题。
一句话提示词生成10款网页游戏:Claude Code实战体验
资深开发者用Claude Code命令行工具,仅凭一句话自然语言提示词,在一小时内生成2048、五子棋、俄罗斯方块等10款可玩网页游戏并部署上线。深度解析AI编程的真实能力与局限。