Veo 3.1角色一致性工作流:五步打造专业级AI视频

基于Veo 3.1的五步工作流系统解决AI视频角色一致性问题
AI视频生成中角色一致性差的根源在于扩散模型缺乏持久角色记忆。一位创作者分享了基于Google Veo 3.1和Nano Banana Pro的升级版工作流,通过五个步骤——纯色背景创建角色、生成多角度联系表、九格场景网格生成、全分辨率帧提取、使用Ingredients模式生成动画——将角色一致性从碰运气变为可控的系统流程。
用AI生成视频时,角色一致性始终是最棘手的问题——同一个角色换个镜头就可能判若两人。这个问题的根源在于扩散模型(Diffusion Model)的工作机制:当前主流的视频生成模型本质上是从随机噪声中逐步"去噪"生成画面,每次生成都是一个独立的随机过程。模型并没有一个持久的"角色记忆"——它不会像人类画师那样记住"这个角色的鼻子长什么样"。每次生成新镜头时,模型只能依赖文本提示词和参考图像来推断角色外观,而文本描述天然存在模糊性(比如"棕色短发"可以对应无数种具体造型),这就导致同一角色在不同镜头中容易出现面部特征漂移、服装细节变化等问题。
最近,一位创作者分享了基于Google Veo 3.1的升级版工作流,通过五个清晰步骤,把角色一致性从"碰运气"变成了可控的系统流程。本文将完整拆解这套方法,帮你在实际项目中直接上手。
工具选择与核心思路
这套工作流的核心工具组合是:Google Veo 3.1(视频生成)+ Nano Banana Pro(图片生成),两者都集成在Google Flow平台中,所有操作在一个界面内完成,不需要在多个工具间来回切换。
Google Veo 3.1是Google DeepMind推出的视频生成模型,属于Veo系列的最新迭代版本。相比前代,3.1版本在时间一致性(temporal consistency)和物理运动合理性方面有显著提升,能够生成更长、更连贯的视频片段。Nano Banana Pro则是一款专注于高质量图像生成的模型,擅长根据参考图像生成风格一致的新图像。两者运行的Google Flow平台,本质上是Google提供的一站式AI创作环境,类似于一个集成了多种AI模型的工作台,用户可以在同一界面中调用不同模型完成图像生成、视频生成、图像编辑等任务,避免了在不同工具间导出导入的繁琐流程和质量损失。
整体思路并不复杂:先建立角色的视觉锚点,再通过联系表(Contact Sheet)固化角色特征,然后用场景网格批量生成一致的镜头,最后逐帧提取并转化为视频。每一步都有明确的输入和输出,形成一条可复现的生产流水线。
第一步:创建角色——纯色背景是关键
这是相比上一版工作流的第一个重要改进:生成角色参考图时,务必使用纯色背景。

听起来简单,但这个细节至关重要。当角色处于特定场景或复杂环境中时,AI模型容易将背景元素与角色特征混淆,导致后续生成时角色外观产生偏移。这种现象在技术上被称为"特征纠缠"(Feature Entanglement)——模型的注意力机制无法完全区分前景角色和背景环境的视觉特征,可能会把背景中的颜色、纹理信息错误地编码为角色属性的一部分。纯色背景让模型能够干净利落地"认识"你的角色——服装细节、面部特征、体型比例,一切都不会被环境干扰。
这一步的核心原则是:保持简洁明了。不要在角色创建阶段就加入复杂的场景设定,那是后面的工作。无论你的角色是超级英雄、消防员还是宇航员,这条原则都适用。
第二步:生成角色联系表——整个流程的灵魂
这是整个Veo 3.1角色一致性工作流中最重要的环节。所谓"角色联系表"(Character Contact Sheet),就是用主参考图像配合专门的提示词,生成一张展示角色各个角度的综合图。
Contact Sheet这个概念最早来自传统胶片摄影。摄影师冲洗胶卷后,会将整卷底片直接接触(contact)相纸进行曝光,得到一张缩略图总览,用于快速浏览和挑选照片。在动画和游戏行业中,这个概念演变为"角色设定表"(Character Sheet)或"角色转面图"(Character Turnaround),即在一张图上展示角色的正面、侧面、3/4角度、背面等多个视角,供建模师和动画师参考。在AI工作流中借用这个概念,本质上是将人类创作流程中的"角色设定"环节数字化——通过一张多角度的综合参考图,为AI模型提供比单张图片丰富得多的角色信息,从而大幅降低不同镜头间的外观偏差。
升级版的联系表提示词更加专注于确保角色与参考图像保持一致。生成结果会从正面、侧面、背面等多个视角呈现你的角色,相当于为AI建立了一份完整的"角色档案"。
在后续所有步骤中,你都需要同时使用主参考图和联系表这两张图片。这种双重参考机制是角色在不同场景中保持一致的核心保障——少了任何一张,一致性都会明显下降。
第三步:场景网格生成——为什么不用单张图片
对于每个场景,你需要准备三样东西:主参考图像、角色联系表、以及场景网格提示词。在提示词中有专门的区域填写场景描述,不需要太复杂,但值得包括大致的情绪、光线方向以及你想要的技术细节。

生成结果是一个九格网格——同一场景的九个不同镜头角度。很多人会问:为什么要用网格而不是直接生成单张图片?
九格网格(3×3 Grid)生成策略之所以能提升一致性,与扩散模型的注意力机制(Attention Mechanism)密切相关。当模型在同一张画布上同时生成九个画面时,这九个区域在去噪过程中会共享同一个潜在空间(Latent Space)的上下文信息。简单来说,模型在生成第五格的光影时,会"看到"其他八格的光影处理方式,从而自然地保持风格统一。这与单独生成九张图片有本质区别——后者每次生成都是独立的随机过程,即使使用完全相同的提示词,也可能产生色调偏差、光线方向不一致等问题。这种网格生成技巧在AI图像创作社区中被广泛使用,Midjourney的默认输出模式(四格网格)也是基于类似的原理。
具体来说,网格的优势体现在三个方面:
- 一致性更强:同一网格内的镜头在颜色、光线和技术风格上天然保持一致,比单独生成的镜头协调得多
- 选择更多:从一个网格中你可以挑选多帧,意味着同一场景可以产出多段视频镜头
- 效率更高:一次生成九个候选,远比逐张生成再筛选来得快
这里有一个效率技巧:生成第一张场景网格后,在Google Flow中点击"Reuse Text Prompt",只修改底部的场景描述,其余保持不变,就能快速批量生成不同场景的网格。这个小操作能省下大量时间。
第四步:帧提取——不是裁剪而是重新生成
从九格网格中提取单独帧时,直接在Photoshop中裁剪会导致分辨率下降。更好的做法是使用专门的提取提示词:输入面板编号,附上网格图片,让AI生成全分辨率的单帧。
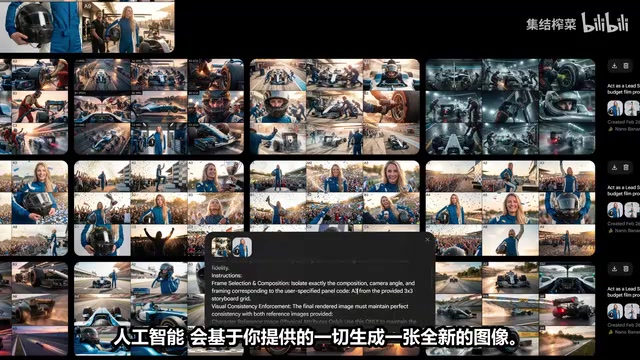
这里有一个关键细节:如果画面中包含角色,提取时一定要把场景网格和主参考图一并附上。这种组合能帮助AI在提取的帧中保持角色的一致性。
需要注意的是,这不是一个简单的裁剪工具——AI会基于你提供的所有素材生成一张全新的图像。这个过程本质上是一次"有条件的图像生成"(Conditional Image Generation),模型以网格中的特定区域为主要视觉条件,同时参考角色原始设定图来约束角色外观,最终输出一张全分辨率的独立画面。结果并非总是完美,但在大多数情况下效果足够好。要从同一网格提取更多图片,同样使用"Reuse Text Prompt"功能,切换面板编号即可。
第五步:动画生成——Ingredients与Frames的选择
将所有全分辨率镜头准备好后,就到了最激动人心的环节:让静态画面动起来。将每个镜头上传到Google Flow,撰写运动提示词,描述你希望相机和角色如何移动。

这里有一个高频问题:到底应该用Ingredients to Video还是Frames to Video?
答案是:大多数情况下使用Ingredients to Video。两者的区别反映了AI视频生成中"参考图像引导"的两种不同策略:
- Ingredients to Video:将你的图片作为拍摄的通用视觉参考,AI有更大的创作空间。这种模式更接近"风格/内容参考"——模型将输入图像理解为视觉灵感板(Mood Board),从中提取角色外观、场景氛围、色彩风格等高层语义信息,然后结合文本提示词自由生成视频
- Frames to Video:将图片按字面理解为视频片段的起始帧和结束帧,对画面约束更强。这种模式采用的是关键帧插值(Keyframe Interpolation)思路,模型需要从起始帧"变形"到结束帧,对输入图像的构图和角色姿态有严格要求
由于我们的图像并不是视频的真实首帧或末帧,Frames模式反而会产生不自然的扭曲或跳变。选错模式是很多人踩的坑,记住这个区别能省去不少返工。
还有一个省钱的实用建议:一次只生成一个片段。如果结果不理想,调整提示词再试。同时生成四个片段然后全部丢弃,等于浪费四倍的积分。这一点在实际项目中尤为重要——由于视频生成对算力的消耗远超图像生成(一段几秒钟的视频可能需要生成上百帧画面,每帧都要经历完整的扩散去噪过程),各平台通常按生成次数或视频时长收费。在行业实践中,一个几分钟的AI短片可能需要数百次生成尝试,积分费用可以从几十美元到数百美元不等,因此优化工作流、减少无效生成是AI视频创作者的必备技能。
工作流总结与实践建议
回顾整个Veo 3.1角色一致性工作流的五个步骤:
| 步骤 | 操作 | 关键要点 |
|---|---|---|
| 1 | 创建角色 | 纯色背景,保持简洁 |
| 2 | 生成联系表 | 多角度固化角色特征 |
| 3 | 场景网格 | 九格网格保证镜头一致性 |
| 4 | 帧提取 | 全分辨率,附上参考图 |
| 5 | 动画生成 | 使用Ingredients模式,逐帧处理 |
这套工作流的核心价值在于系统化。它不依赖运气或反复重试,而是通过结构化的步骤,将AI视频中的角色一致性从"看天吃饭"变成"可控的流程"。从技术角度看,这套方法本质上是在弥补当前扩散模型缺乏持久角色记忆的缺陷——通过在每个生成环节都提供充分的视觉参考,人为地为模型构建了一个"外部记忆系统"。对于想要用AI制作短片、广告或系列内容的创作者来说,这是一套值得深入实践的方法论。
AI生成仍然存在不确定性,不可能每次都完美。但有了这套框架,你至少知道在哪个环节可以调整、如何调整,而不是面对一堆不一致的素材束手无策。把流程跑通一遍,你会发现角色一致性这件事,远没有想象中那么难。
相关推荐
 教程攻略
教程攻略Cursor+Codex双IDE协同:开源项目二开实战方法论
基于实战经验总结的开源项目二次开发完整方法论,详解Cursor+Codex双IDE协同工作流,涵盖二开七环节、MVP验证、AI读源码技巧,帮助开发者三天跑通项目、两周完成业务集成。
 教程攻略
教程攻略Cursor多Agent实战:50分钟搭建Next.js全栈博客
使用Cursor IDE多Agent协作模式,50分钟内从零搭建全栈博客。涵盖Next.js、Clerk认证、Supabase数据库集成,详解4个AI Agent分阶段开发流程与关键避坑经验。
 教程攻略
教程攻略从零搭建AI软件工厂:Cursor工程师的多Agent协作实战经验
Cursor工程师Eric分享AI软件工厂构建实战:从自动化六层级、护栏设计、并行Agent管理到规模化扩展,详解如何用多Agent协作实现7×24小时高效软件开发。