Vibe Coding陷阱:AI为什么只给你最小交付?

一句话需求的隐患:能用≠好用
用AI做Vibe Coding(氛围编程)时,很多人都踩过同一个坑:给AI一句简单的需求描述,它确实能交付一个"能用"的东西——但往往也仅仅是"能用",离"好用"差了十万八千里。B站UP主破王在实战中就遇到了一个教科书级的案例。
Vibe Coding是由OpenAI联合创始人Andrej Karpathy在2025年初提出的概念,指的是一种全新的编程范式——开发者不再逐行编写代码,而是通过自然语言向AI描述需求,由AI生成代码,开发者只需要"感受氛围",看结果是否符合预期。这种方式极大降低了编程门槛,但也带来了新的挑战:当开发者对底层实现缺乏掌控时,很容易出现"看起来能用,实际上有坑"的情况。
事情的起因很简单:他之前用一句话需求让AI实现了一个BGM(背景音乐)功能,测试通过,一切正常。然而在实际使用中,当他上传一个MP3格式的音频文件作为BGM时,功能直接罢工了。排查后发现,AI实现的BGM功能仅支持WAV格式,其他格式一概不认。

这就引出了一个核心问题:作为使用者,我们默认认为一个音频功能"应该"支持常见格式(MP3、WAV、FLAC等),但AI并不会主动替你考虑这些。你没说要支持MP3,它就只实现最基础的WAV支持——这就是最小交付的典型表现。
技术分析:多格式支持与单一格式的本质区别
发现问题后,破王没有急于让AI直接改代码,而是先做了一轮技术层面的沟通。他向AI抛出了两个关键问题:
- 音频剪辑场景下,多格式支持和单一格式支持有什么本质区别?
- MP3转WAV的过程中,是否会造成音质损坏?
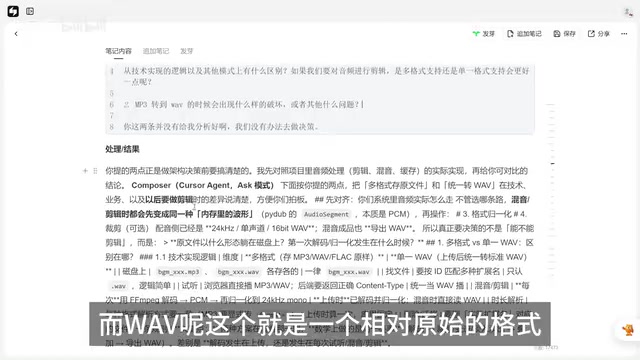
AI给出的解释是:MP3是有损压缩格式,WAV是无损的原始格式。在音频剪辑场景中,通常使用WAV进行处理,因为它保留了完整的音频数据,处理起来更稳定。项目中音频合成、混合等环节也都统一基于WAV格式。
要理解这个技术选择,需要了解这几种格式的本质差异。WAV(Waveform Audio File Format)是微软和IBM联合开发的音频格式,以PCM(脉冲编码调制)方式存储原始音频数据,不进行任何压缩,因此文件体积大但音质完整。MP3(MPEG Audio Layer III)则采用有损压缩算法,通过心理声学模型去除人耳不易感知的音频信息,将文件体积压缩到WAV的约1/10。在音频处理管线中,WAV因为数据完整、无需解码,处理效率更高且不会引入额外的编解码误差。而MP3每次解码再编码都会累积损失,这就是为什么专业音频处理通常以WAV作为中间格式。FLAC(Free Lossless Audio Codec)则是无损压缩格式,兼顾了文件体积和音质保真,但在实时处理场景中仍需先解压为PCM数据。
基于这个分析,最终确定的方案是:在用户上传环节支持多种音频格式,上传后自动转换为WAV格式再进行后续处理。这是一个兼顾用户体验和技术稳定性的折中方案——用户不用关心格式问题,底层处理又能保持一致性。
在工程实现层面,这类音频格式转换通常依赖FFmpeg这一开源多媒体框架,它支持几乎所有主流音频和视频格式的编解码。在Python生态中,开发者常用pydub库(底层调用FFmpeg)或soundfile库来实现格式转换。一个典型的实现流程是:用户上传任意格式的音频文件→后端检测文件格式(通过文件头魔数或MIME类型判断)→调用FFmpeg将其转码为WAV格式→存储转码后的文件供后续处理使用。这个过程中还需要注意采样率、位深度和声道数的统一,否则在后续的音频混合、剪辑环节可能出现不兼容问题。
多工具协作:Cursor + Claude + DeepSeek的组合拳
这个案例中另一个值得关注的点是破王的多AI工具协作流程。这套方法论非常实用,值得借鉴。
在展开具体流程之前,有必要了解这几个工具各自的特点。Cursor是一款基于VS Code的AI原生代码编辑器,内置了与大语言模型的深度集成,支持在编辑器内直接与AI对话、生成和修改代码,特别适合快速迭代的开发场景。Claude是Anthropic公司开发的大语言模型,以长上下文理解能力和安全对齐著称,擅长处理复杂的分析和推理任务。DeepSeek是深度求索公司推出的大模型系列,其推理模型(如DeepSeek-R1)在数学推理和代码生成方面表现突出,且具有较强的指令遵从性。三者的组合使用体现了当前AI开发的一个重要趋势:没有单一模型能在所有任务上表现最优,多模型协作(Multi-Model Orchestration)正在成为高效开发的标准实践。
第一步:Cursor做轻量级沟通
在Cursor中与AI进行初步的需求沟通和技术分析。Cursor适合处理轻量级的对话任务,快速理清思路、确认方案方向。沟通完成后,让AI将方案整理成Markdown文档。
第二步:DeepSeek做深度审核
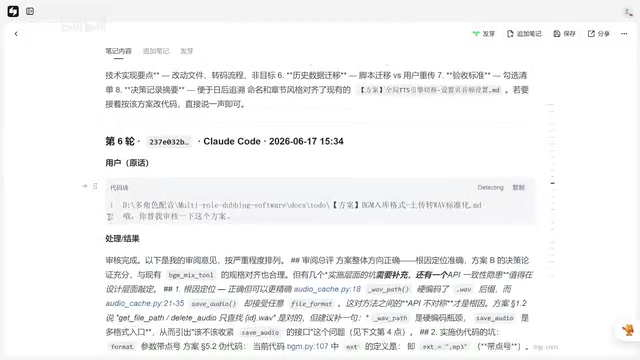
方案文档整理好后,提交到Claude(通过CloudClub)背后的DeepSeek进行深度推理和方案审核。DeepSeek审核后会提出一系列问题和改进建议,然后让它自己修改完善——"你提出的问题你自己改"。DeepSeek的指令遵从性更好,基本上能独立搞定深度优化任务。
第三步:回到Cursor执行实施
审核完善后的方案再交回Cursor进行代码实施。实施完成后进行自测和审查,确保功能符合预期。
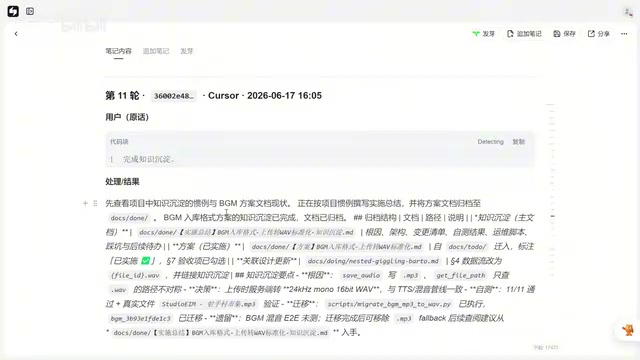
这套组合的核心逻辑是:用轻量工具做沟通,用重量工具做推理审核,再用轻量工具做执行落地。比单纯依赖某一个AI工具,整体效率和交付质量都要高出不少。
AI的最小交付思维:为什么它不多做一步
这个案例揭示了AI编程中一个非常重要的规律:AI倾向于给你最小可行交付(Minimum Viable Delivery)。
这一行为模式有其深层的技术原因。最小可行交付的概念源自精益创业方法论中的MVP(Minimum Viable Product,最小可行产品),由Eric Ries在《精益创业》一书中系统阐述。MVP的核心思想是用最少的资源构建一个刚好能验证假设的产品版本。AI在代码生成中表现出类似的行为模式,但原因不同:大语言模型的训练目标是根据输入生成最合理的输出,当输入(即需求描述)信息不足时,模型倾向于选择最保守、最确定的实现路径,而非自行推测用户的隐含需求。这种行为在NLP领域被称为"指令跟随"(Instruction Following),模型严格遵循字面指令而非推断意图。
具体表现为:
- 你说"实现BGM功能",它就实现一个最基础的、能播放音频的功能
- 你没说要支持多格式,它就只支持最简单的一种格式
- 你没提到异常处理,它就不会主动加上错误提示
- 你没要求用户体验优化,它就不会考虑交互细节
这并不是AI在"偷懒",而是它的底层工作逻辑——严格按照指令执行,不做额外假设。从某种角度看,这其实是一种"安全"的行为模式,避免过度解读需求导致方向跑偏。但对使用者来说,这意味着一个残酷的现实:
你的需求描述越模糊,AI交付的东西就越"最小化"。你不说的,它绝对不做。
实战建议:五个策略避开最小交付陷阱
基于这个教训,在进行Vibe Coding时可以采取以下策略:
1. 需求描述要具体化
不要只说"实现BGM功能",而要说"实现BGM功能,支持MP3/WAV/FLAC等常见音频格式,上传后自动转换为统一格式处理"。把你脑子里默认的"应该"变成白纸黑字的"必须"。
2. 主动列出边界条件
告诉AI需要考虑哪些异常情况、兼容性要求、用户使用场景。比如"如果用户上传了不支持的格式,需要给出明确的错误提示"。
3. 分阶段审查
实现后不要急于投入使用,先用不同的输入条件进行测试。用MP3试一下、用FLAC试一下、传个损坏文件试一下——把边界情况都跑一遍。
4. 善用多工具协作
用不同的AI工具互相审核方案,一个AI的盲区可能被另一个AI发现。Cursor负责沟通和执行,DeepSeek或Claude负责深度审核,形成互补。
5. 建立需求模板
对于常见的功能模块,提前准备好详细的需求描述模板,避免每次都遗漏关键点。把踩过的坑沉淀成模板,下次就不会再踩。
归根结底,Vibe Coding的核心矛盾在于:我们希望用最少的话让AI做最多的事,但AI的逻辑是你说多少它做多少。找到这个平衡点,才是高效AI编程的关键所在。
相关推荐
DeepSeek V4 Flash免费使用教程:Cherry Studio与CC Switch配置指南
DeepSeek V4 Flash限时免费,输入输出token零计费。本文详解OpenModel平台注册流程,以及在Cherry Studio和CC Switch中的完整配置方法,附模型映射与使用场景推荐。

1FlowBase实战:为DeepSeek V4挂载视觉工具实现多模态能力
详解如何通过1FlowBase编排平台,将视觉模型MIMO 2.5作为工具挂载到DeepSeek V4上,实现Fusion多模态入口。涵盖开始节点配置、LM节点设置、工具挂载与条件触发等完整搭建步骤。
Chrome DevTools MCP实测:用AI自动操控浏览器写文章并发布
实测Chrome DevTools MCP服务配合Claude Code,实现AI自动打开浏览器、撰写文章、填写标签并一键发布的全流程。详细拆解技术方案、操作步骤及优缺点分析。