vLLM与SGLang本地部署教程:性能提升3-8倍的实战指南

用vLLM/SGLang替代LM Studio/Ollama,通过Docker+AI助手高效部署本地大模型推理框架。
文章指出LM Studio和Ollama在推理性能上远不及专业框架vLLM和SGLang,后者在吞吐量、显存利用率和量化方案上全面领先。vLLM稳定性和兼容性更强,SGLang性能更极致但稳定性不足。部署方面,推荐通过Docker容器化方案配合AI助手指导,可大幅降低复杂环境配置的难度,实现三步高效部署。
为什么要抛弃LM Studio和Ollama?
对于大多数本地大模型玩家来说,LM Studio和Ollama是入门首选——安装简单,下载模型后直接加载即可使用。但当你对推理性能有更高要求时,这两个工具的短板就暴露无遗了。
专业推理框架vLLM和SGLang在多个维度上全面超越前者:
- 吞吐量提升3-8倍:vLLM和SGLang面向生产环境设计,支持多前端并发调用,吞吐量远超LM Studio
- 显存利用率更高:智能管理KV Cache,将无用缓存及时释放并重新利用,多轮对话场景下显存节省40%-60%
- 量化方案更灵活:支持NVFP4等英伟达专属量化策略,可直接加载原版模型,精度远优于GGUF格式的Q4量化
KV Cache与显存管理机制
KV Cache(键值缓存)是Transformer架构中的核心优化机制。在自回归生成过程中,模型每生成一个新Token都需要访问所有历史Token的注意力键值对。KV Cache通过将这些中间计算结果缓存起来避免重复计算,但代价是显存占用随上下文长度线性增长。vLLM引入的PagedAttention技术借鉴操作系统虚拟内存的分页思想,将KV Cache切分为固定大小的物理块动态分配,使显存碎片率从传统方案的60%-80%降至不足4%,这正是其在多轮对话场景下能节省40%-60%显存的根本原因。
NVFP4量化与GGUF格式对比
NVFP4是英伟达专为Blackwell架构(RTX 50系列)设计的4位浮点量化格式,与传统整数量化不同,它保留了浮点数的动态范围表示能力,在极低比特位宽下仍能维持接近BF16的推理精度。相比之下,GGUF格式的Q4量化(如Q4_K_M)采用整数量化加分组缩放因子的方案,虽然CPU/GPU通用性强,但在精度保留上存在明显损失,尤其在数学推理和代码生成任务中表现差距显著。NVFP4依赖Tensor Core的FP4计算单元,因此只能在支持该指令集的GPU上运行,这也是它目前仅限于5090等新卡的原因。

有用户甚至直言:跟vLLM和SGLang比起来,LM Studio和Ollama"连玩具都算不上"。当然,代价就是部署难度呈指数级上升——很多人折腾几天都找不到问题所在。
vLLM vs SGLang:该选哪个推理框架?
SGLang:极致性能但稳定性存疑
SGLang的推理性能比vLLM还要强10%-20%,在多轮对话和复杂推理场景中优势尤为明显。但它也有几个明显短板:
- 稳定性不足:开发节奏过于激进,部分功能不够成熟
- 新模型适配较慢:模型支持的更新速度不如vLLM及时
- 兼容性问题:例如Qwen3的27B NVFP4 MTP-XS模型,SGLang目前无法运行,而vLLM已经支持
vLLM:兼容性强、社区成熟的主流方案
vLLM在模型兼容性和运行稳定性上更胜一筹,对于大多数用户来说是更务实的选择。在5090(32GB显存)上部署Qwen3 27B NVFP4模型,vLLM可以支持约70K的上下文长度,基本满足日常使用需求。
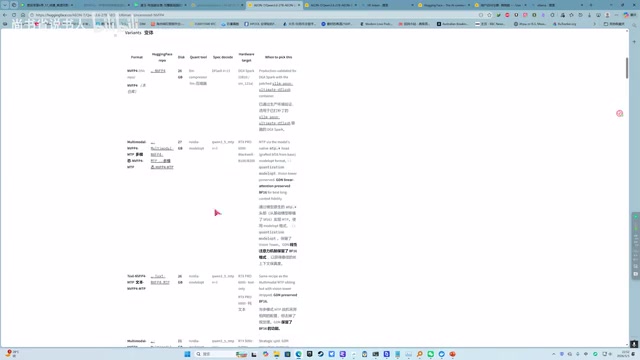
选型建议:追求极致性能且目标模型在SGLang支持列表中,选SGLang;更看重稳定性和广泛的模型兼容性,选vLLM。
Docker+AI助手:三步完成部署
传统的命令行手动部署方式极其痛苦,这里分享一个借助AI辅助的高效部署方案,核心思路是让大模型帮你部署大模型。
第一步:准备一个可靠的AI助手
给DeepSeek充值50-100元,或者申请小米创作者计划获取免费Token额度。关键是要有一个能力足够的AI助手(通过Cherry Studio等前端调用),让它全程指导你完成部署。
千万不要自己从网上找教程然后一行行往命令行里粘——你会被各种环境依赖问题折磨到崩溃。
第二步:安装Docker和WSL环境
两个软件必须提前装好:
- WSL(Windows Subsystem for Linux):Windows下的Linux子系统环境
- Docker Desktop(强烈推荐):容器化部署工具,可以直接拉取vLLM或SGLang的官方镜像,省去大量手动配置
WSL2与GPU直通机制
WSL2基于轻量级Hyper-V虚拟机实现,运行完整的Linux内核。微软与英伟达合作开发的WDDM GPU虚拟化技术允许WSL2内的Linux进程直接访问宿主机的GPU资源,CUDA调用通过paravirtualization层转发至Windows驱动,性能损耗通常低于5%。这意味着在WSL2中运行的Docker容器可以获得接近原生Linux的GPU推理性能,使Windows用户无需双系统即可运行生产级推理框架。
Docker容器化部署的技术价值
Docker通过Linux命名空间(Namespace)和控制组(cgroups)技术实现进程级隔离,将应用及其所有依赖打包为镜像。对于vLLM和SGLang这类依赖链极其复杂的推理框架(涉及CUDA版本、cuDNN、PyTorch、Flash Attention等数十个相互耦合的组件),容器化的价值在于将「环境配置」问题转化为「镜像拉取」问题。官方维护的Docker镜像已预先完成所有依赖的版本锁定和编译优化,用户无需手动处理CUDA工具链与Python包之间的版本冲突,这正是本方案能将部署成功率大幅提升的核心原因。
⚠️ 重要提醒:务必提前将Docker的数据目录(ext4.vhdx文件)迁移到非C盘的SSD上!部署过程中会产生大量缓存,几个小时就能写入100GB以上,C盘很容易被撑爆。
安装过程本身不复杂,直接告诉AI助手"帮我在Docker里安装vLLM"或"帮我在Docker里安装SGLang
相关推荐
 教程攻略
教程攻略Cursor+Codex双IDE协同:开源项目二开实战方法论
基于实战经验总结的开源项目二次开发完整方法论,详解Cursor+Codex双IDE协同工作流,涵盖二开七环节、MVP验证、AI读源码技巧,帮助开发者三天跑通项目、两周完成业务集成。
 教程攻略
教程攻略Cursor多Agent实战:50分钟搭建Next.js全栈博客
使用Cursor IDE多Agent协作模式,50分钟内从零搭建全栈博客。涵盖Next.js、Clerk认证、Supabase数据库集成,详解4个AI Agent分阶段开发流程与关键避坑经验。
 教程攻略
教程攻略从零搭建AI软件工厂:Cursor工程师的多Agent协作实战经验
Cursor工程师Eric分享AI软件工厂构建实战:从自动化六层级、护栏设计、并行Agent管理到规模化扩展,详解如何用多Agent协作实现7×24小时高效软件开发。