VS Code AI Toolkit 2.0详解:Agent构建器+免费用GPT-5
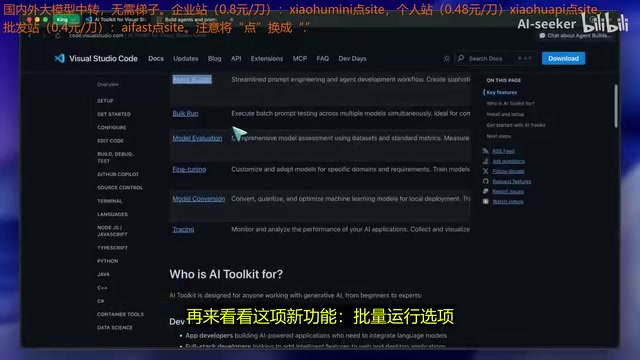
VS Code AI Toolkit 2.0重大更新,新增Agent构建器、模型评估等功能并可免费用GPT-5。
微软VS Code AI Toolkit迎来2.0重大更新,从简单的模型对话工具进化为综合性AI开发平台。核心新功能包括:零代码Agent构建器(支持MCP工具集成)、批量运行多模型对比、自定义模型评估体系、IDE内模型微调,以及通过GitHub Models免费使用GPT-5、Claude等顶级模型。此外,本地运行不注入额外系统提示,保证了原生性能。
微软的 VS Code AI Toolkit 迎来了一次重大更新。这款 VS Code 扩展不仅支持本地和云端模型的无缝切换,还新增了 Agent 构建器、批量测试、模型评估等一系列实用功能。更值得关注的是,通过 GitHub Models 选项,开发者可以免费使用 GPT-5、Claude 等顶级模型。本文将逐一拆解这次更新的核心亮点。
AI Toolkit 是什么?
如果你还不了解 Microsoft AI Toolkit,它本质上是一个 VS Code 扩展插件,能让开发者通过 Ollama、LM Studio 等运行时轻松地在本地运行大语言模型,同时也支持云端模型的接入。
这里有必要解释一下这些运行时的技术背景。Ollama 是一个开源的本地大模型运行框架,它将模型的下载、量化、推理封装为简单的命令行操作,支持 Llama、Mistral、Gemma 等主流开源模型。LM Studio 则提供了图形化界面,让非技术用户也能在本地运行 GGUF 格式的量化模型。这些运行时的共同特点是利用本地 GPU 或 CPU 进行推理,数据不离开本机,兼顾了隐私性和低延迟。AI Toolkit 将这些运行时统一纳入管理,相当于在 IDE 层面提供了一个抽象层,开发者无需关心底层推理引擎的差异。
安装后,VS Code 侧边栏会出现工具包选项,左侧用于导航,右侧展示各功能页面。它的定位有点像集成在代码编辑器中的 LM Studio,但功能远不止于此——它将模型管理、对话测试、Agent 构建、模型评估等能力整合到了开发者最熟悉的 IDE 环境中。
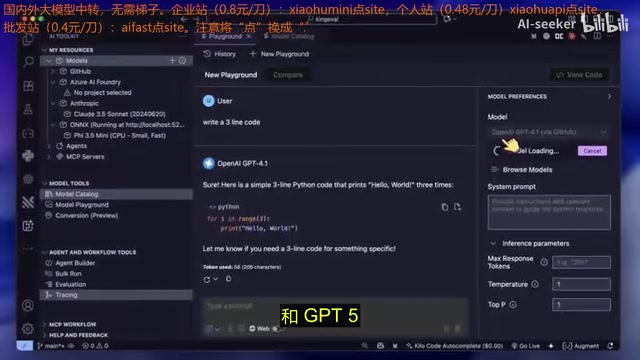
在模型管理方面,你可以通过 Ollama、Yanks 或 Azure Foundry 等多个运行时添加模型,也可以接入任何 OpenAI 兼容的 API。如果你已登录 GitHub 账号,还能直接浏览并使用 GitHub Models 提供的各种模型,包括 GPT-4.1、GPT-5 等,而且完全免费。
Agent 构建器:零代码创建 AI 代理
Agent 构建器是本次更新最令人兴奋的新功能。它提供了一个图形化界面,让开发者无需编写复杂的框架代码,就能快速创建自己的 AI 代理。
要理解这项功能的价值,需要先了解 AI Agent 的技术范式。AI Agent(智能代理)是当前大模型应用的核心范式之一,与传统的单轮问答有本质区别。Agent 具备自主规划、工具调用和多步推理的能力。一个典型的 Agent 工作流包括:接收用户指令→分解任务→选择合适的工具执行→观察结果→决定下一步行动,这个循环被称为 ReAct(Reasoning + Acting)模式。AI Toolkit 的 Agent 构建器将这一复杂流程图形化,开发者只需定义系统指令和可用工具,框架会自动处理工具调用的编排逻辑。
创建流程详解
创建 AI Agent 的流程非常直观:
- 选择模型:从已添加的可用模型中选择一个作为 Agent 的底层驱动
- 编写系统指令:告诉 AI 代理它的角色和任务是什么
- 设置动态变量:在指令中使用双大括号
{{变量名}}语法,生成包含变量的提示模板,每次使用时输入相应的值即可 - 配置工具:为 Agent 添加可调用的外部工具
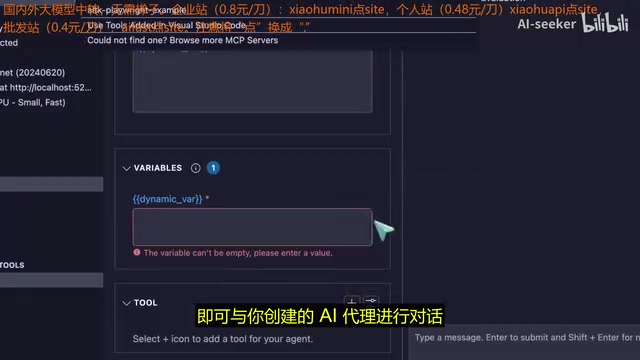
MCP 工具集成与自定义扩展
工具选项是 Agent 构建器的核心所在。你可以通过两种方式为 Agent 赋能:
- MCP 服务器:在左侧边栏的 MCP 服务器选项中设置任意 MCP 服务器,设置完成后即可在 Agent 中调用。这意味着你可以接入文件系统、数据库、API 等各种外部资源。
- 自定义工具:自己编写代码定义工具逻辑,满足更高级和个性化的需求。
MCP(Model Context Protocol,模型上下文协议)是由 Anthropic 于 2024 年底推出的开放标准协议,旨在为大语言模型提供统一的外部工具和数据源接入方式。在 MCP 出现之前,每个 AI 应用都需要为不同的数据源编写定制化的集成代码,导致大量重复工作。MCP 采用客户端-服务器架构:MCP 服务器负责暴露特定的工具能力(如文件读写、数据库查询、API 调用),MCP 客户端(如 AI Toolkit)则通过标准化的 JSON-RPC 协议与服务器通信。这种设计类似于 USB 协议之于外设——一个标准接口即可连接无数设备。目前 MCP 生态已涵盖 GitHub、Slack、PostgreSQL、文件系统等数百个服务器实现,AI Toolkit 对 MCP 的原生支持意味着开发者可以直接利用这个快速增长的工具生态。
工具包内置了一些实用示例,比如网页抓取器(基于 Playwright)、代码解释器等。有开发者将其配合深度维基和网络搜索工具使用,把 Agent 当作一个上下文引擎来获取和整理信息,效果相当不错。
批量运行与模型评估:数据驱动的模型选型
对于需要频繁测试和比较不同模型的开发者来说,批量运行和模型评估功能堪称利器。
批量运行多模型对比
批量运行选项允许你创建包含大量提示的表格,然后一次性对多个模型运行所有提示。这对于模型测试人员来说极为实用——你可以输入所有测试用例,系统会自动比较不同模型在相同提示下的性能表现。
自定义模型评估体系
模型评估功能更进一步,它允许你构建自己的评估体系:
- 构建数据集:输入问题和预期答案(真实值)
- 自动评分:系统会检查模型回答与预期答案的相似度并打分
- 多维度指标:可以衡量工具调用准确性等多种指标
- 可定制评分标准:评估设置可以根据需求自行修改
在实际的 AI 工程实践中,模型选型是一个系统性工程问题。不同模型在不同任务类型(如代码生成、文本摘要、逻辑推理、多语言处理)上的表现差异显著,且模型的性能还受到提示词设计、温度参数、上下文长度等因素影响。传统的评估方式依赖公开基准测试(如 MMLU、HumanEval、MT-Bench),但这些基准往往无法反映特定业务场景的真实需求。AI Toolkit 的自定义评估体系允许开发者构建领域专属的测试集,用真实业务数据衡量模型表现,这种做法在业界被称为"领域特定评估"(Domain-Specific Evaluation),是将 AI 从实验室推向生产环境的关键环节。
这套评估体系让开发者能够用数据说话,选择最适合特定任务的模型,而不是凭直觉做决策。
更多实用功能亮点
模型微调
现在你可以直接在 VS Code 里微调模型,只需点击几下即可完成设置。这大大降低了模型微调的门槛,开发者不再需要切换到专门的训练环境。
模型微调(Fine-tuning)是指在预训练模型的基础上,使用特定领域的数据进行进一步训练,使模型更好地适应目标任务。常见的微调技术包括全参数微调(Full Fine-tuning)和参数高效微调(PEFT),后者的代表方法是 LoRA(Low-Rank Adaptation),它通过在模型权重矩阵中注入低秩分解矩阵来大幅减少可训练参数量,使得在消费级 GPU 上微调数十亿参数的模型成为可能。传统微调流程涉及数据预处理、训练脚本编写、超参数调优、显存管理等多个环节,技术门槛较高。AI Toolkit 将这些步骤封装为图形化操作,是降低微调门槛的重要尝试。
追踪与调试
追踪选项可以让你收集和可视化追踪数据,深入了解 AI 应用和 Agent 的运行日志、行为模式和性能表现。这对于调试复杂的 Agent 工作流尤其重要。
通过 GitHub Models 免费使用 GPT-5
通过 GitHub Models 选项,开发者可以免费访问 GPT-5、Claude 等顶级模型。GitHub Models 是 GitHub 于 2024 年推出的模型目录服务,依托 Azure AI 基础设施,为开发者提供主流大模型的免费试用额度。其免费层(Free Tier)通常包含每分钟请求数和每日 Token 总量的限制,适合开发测试和原型验证场景。支持的模型涵盖 OpenAI 的 GPT 系列、Anthropic 的 Claude 系列、Meta 的 Llama 系列、Mistral 等。开发者只需拥有 GitHub 账号即可获取 API 访问令牌,且接口兼容 OpenAI SDK 格式,迁移成本极低。这一策略本质上是微软通过 GitHub 开发者生态为 Azure AI 服务导流的重要举措。
在 Playground 中,你不仅可以进行文本对话,还可以附加图片、文档、代码,甚至让模型帮你搜索网页。生成的代码可以一键添加为新文件,还能获取 OpenAI SDK 脚本直接用于项目。
原生模型运行不注入额外提示
值得一提的是,AI Toolkit 在本地运行模型时不会注入额外的系统提示。这一点非常关键——很多工具会添加冗长的系统提示,导致本地模型运行缓慢。AI Toolkit 的做法是直接运行原生模型,保证了响应速度。
从技术角度来看,系统提示(System Prompt)会占用模型的上下文窗口(Context Window),而本地运行的小参数模型(如 7B、13B)的上下文窗口通常有限(4K-8K tokens)。冗长的系统提示不仅会压缩用户实际可用的输入空间,还会增加每次推理的计算量,导致首次响应时间(Time to First Token, TTFT)显著增加。此外,对于量化后的小模型而言,过长的系统提示还可能干扰模型对用户指令的理解,降低输出质量。因此,AI Toolkit 保持原生运行的设计在本地推理场景中具有实际的性能优势。
总结与评价
VS Code AI Toolkit 2.0 的更新可以说是一次质的飞跃。它从一个简单的模型对话工具,进化为一个集模型管理、Agent 开发、批量测试、模型评估、微调训练于一体的综合性 AI 开发平台。
最适合的使用场景包括:
- 偏好在代码编辑器中直接使用 AI 模型的开发者
- 需要频繁测试和比较不同模型性能的研究人员
- 想要快速构建 AI Agent 原型的产品团队
- 希望利用 MCP 生态扩展 AI 能力的技术爱好者
作为一款免费的 VS Code 扩展,AI Toolkit 2.0 的功能丰富度和易用性都令人印象深刻。如果你日常工作中频繁使用 VS Code,这款扩展值得立即安装体验。
核心要点
- AI Toolkit 2.0 新增 Agent 构建器,支持通过图形界面创建自定义 AI 代理,并可集成 MCP 服务器和自定义工具
- 通过 GitHub Models 选项,开发者可免费使用 GPT-5、Claude 等顶级模型进行开发和测试
- 批量运行和模型评估功能支持对多个模型进行系统化的性能测试和准确率评分
- 支持直接在 VS Code 中进行模型微调,并提供追踪功能用于可视化分析模型行为
- 本地模型运行不注入额外系统提示,保证原生性能和响应速度
相关推荐
 产品体验
产品体验Qoder vs Cursor实测对比:同样20美金谁更强?
实测对比Qoder和Cursor两款AI IDE,从Agent自主修复能力、人工沟通次数、架构决策等维度评测。Qoder仅需2次沟通完成任务,Cursor需8次。详细分析两者差异,帮你选择最适合的AI编程工具。
 产品体验
产品体验Cursor云Agent演示:打通软件开发全链路瓶颈
深度解析Cursor云Agent最新Demo,展示如何通过云端虚拟机、自动测试产物和全链路控制平面,系统性消除软件开发生命周期中的人类瓶颈,让Agent自主运行、人按需介入。
 产品体验
产品体验Cursor 3.0深度解析:多Agent并行、Design Mode与Best-of-N模型对比
Cursor 3.0正式发布,从AI辅助编程工具进化为Agent舰队指挥中心。本文详解多智能体并行、Design Mode可视化编辑、Best-of-N多模型择优等核心功能,解读AI编程新范式。