WhichLLM:一键检测你的电脑最适合跑哪个本地大模型

WhichLLM:一条命令自动推荐最适合你硬件的本地大模型
WhichLLM是一个开源工具,能自动检测用户硬件配置,结合Hugging Face最新模型数据和多个权威评测基准,综合推荐最适合本地运行的大语言模型及其量化版本。它不仅考虑模型能否装进显存,还过滤虚假评测数据、对旧模型降权,支持模拟任意硬件配置辅助购买决策,并能一键下载部署推荐模型直接开聊,大幅降低了本地大模型的选择和部署门槛。
选本地模型,为什么这么难?
玩本地大模型的人都有过这样的经历:想在自己的电脑上跑一个大语言模型,结果光是选模型就折腾了半天——算显存够不够、查各种量化版本的区别、翻遍评测对比帖,最后可能还是选错了,要么模型太大跑不动,要么选了个小模型效果拉胯。

这里所说的「量化版本」,是本地部署大模型时绑不开的核心概念。原始的大模型权重通常以 FP16 或 BF16 格式存储,每个参数占用 2 字节——一个 70B 参数的模型仅权重就需要约 140GB 空间,远超消费级显卡的显存容量。量化技术通过将权重从高精度浮点数压缩为低精度整数表示(如 INT8、INT4 甚至更低),大幅缩小模型体积。目前最流行的量化格式是 GGUF(由 llama.cpp 项目推动的标准格式),其中 Q2_K、Q3_K、Q4_K、Q5_K、Q6_K、Q8_0 等标识代表不同的量化位数,数字越大精度越高、文件越大、质量损失越小。一般来说,Q5 量化被社区认为是质量与体积的「甜蜜点」,模型大小约为原始 FP16 的 30-35%,而在主流评测上的性能损失通常仅在 1-3% 以内。但不同模型对量化的敏感度不同,选错量化等级可能导致输出质量断崖式下降,这正是选择困难的根源之一。
很多人选模型的逻辑很简单粗暴:参数量越大越好。70B 肯定比 7B 强,对吧?但现实是,一个跑不满显存、疯狂 swap 内存的 70B 模型,体验远不如一个流畅运行的高质量 27B 量化模型。这背后的技术原因在于 GPU 显存(VRAM)与系统内存(RAM)之间巨大的带宽差距。以 RTX 4090 为例,其显存带宽高达 1 TB/s,而 DDR5 系统内存的带宽通常只有 50-80 GB/s,相差十几倍。大语言模型的推理过程本质上是「内存带宽受限」(memory-bandwidth bound)的任务——每生成一个 Token,都需要将模型的全部权重从存储中读取一遍。当模型无法完全加载到显存中时,部分网络层会被卸载(offload)到系统内存甚至硬盘,推理速度可能从每秒 30+ Token 骤降到个位数,对话体验变得难以忍受。真正影响使用体验的,是模型质量、量化精度、推理速度的综合平衡,而不是单纯的参数量。
现在,一个叫 WhichLLM 的开源工具,试图用一条命令解决这个问题。
WhichLLM 是什么?
WhichLLM 是一个在 GitHub 上已获得 700+ Star 的开源项目,它的核心功能非常明确:自动检测你的硬件配置,然后从海量模型中推荐最适合你电脑运行的本地大模型。
具体来说,它的工作流程是这样的:
- 自动检测硬件:识别你的显卡型号、显存大小、系统内存等关键参数
- 拉取最新模型数据:从 Hugging Face 获取最新的模型列表和量化版本信息
- 综合评测排序:结合多个权威评测基准的真实数据,对可运行的模型进行综合评分排序
- 给出最佳推荐:直接告诉你,你的硬件配置下,哪个模型是最优选择
这里值得展开说说 Hugging Face 的角色。Hugging Face 是当前 AI 领域最大的开源模型托管平台,类似于代码领域的 GitHub。截至 2025 年,平台上托管的模型数量已超过 100 万个,其中仅大语言模型的 GGUF 量化版本就有数万个。几乎所有主流开源模型(Llama、Qwen、Mistral、Gemma 等)的官方权重和社区量化版本都会第一时间发布在 Hugging Face 上。WhichLLM 选择从这个平台拉取数据,意味着它能覆盖到几乎所有值得考虑的本地模型选项,并且始终保持与最新发布同步。
比如,如果你用的是 RTX 4090(24GB 显存),WhichLLM 可能会推荐 Qwen3.6 27B 的 Q5 量化版本,预计推理速度约为每秒 27 Token——这是一个在质量和速度之间取得了很好平衡的选择。
核心亮点:不只是"能不能装下"
智能评分而非简单匹配
市面上也有一些工具可以帮你计算显存占用,但 WhichLLM 的思路更进一步。它不只是看模型能不能塞进你的显存,而是综合了多个权威评测基准的数据来做推荐。这意味着它推荐给你的,是真正在评测中表现优秀的模型,而不是"能跑的最大的那个"。
更值得一提的是,WhichLLM 还会过滤虚假评测数据,并自动给过时的旧模型降权。这一设计直击大模型评测领域的一个顽疾。目前主流的评测基准包括 MMLU(大规模多任务语言理解)、HumanEval(代码生成)、GSM8K(数学推理)、ARC(科学推理)等,它们从不同维度衡量模型能力。然而,由于这些评测集是公开的,部分模型开发者会针对测试题目进行「数据污染」——在训练数据中混入评测题目或其变体,导致模型在榜单上的分数虚高,但实际使用中表现平平。这种现象在开源社区被称为「刷榜」或「benchmark hacking」。此外,大模型领域迭代极快,半年前的顶级模型可能已经被新模型全面超越。WhichLLM 通过算法层面的处理——包括交叉验证多个评测基准的一致性、检测异常高分、根据模型发布时间施加时间衰减因子等手段——尽量保证推荐结果的真实可靠性,避免用户被虚假的榜单数据误导。
模拟任意硬件配置
如果你正在考虑升级显卡,或者想帮朋友推荐方案,WhichLLM 还支持模拟任意硬件配置。你不需要真的拥有一块 RTX 5090,就可以提前看看这块卡能跑什么级别的模型,从而做出更理性的购买决策。
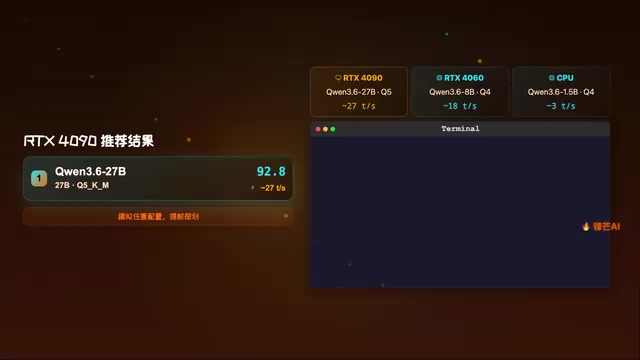
这个功能对于预算有限、需要精打细算的用户来说非常实用。与其买完显卡再发现跑不了想要的模型,不如提前用 WhichLLM 模拟一下。举个实际例子:RTX 4060(8GB 显存)和 RTX 4060 Ti 16GB 版之间差价约 1500-2000 元,但后者能运行的模型级别可能从 7-8B 跃升到 14-15B,质量差距显著。通过模拟功能,你可以清楚地看到这笔额外投入换来了多大的模型能力提升,从而判断是否值得。
一键开聊,开箱即用
WhichLLM 最"狠"的功能是:推荐完模型后,一条命令就能直接开始对话。它会自动下载推荐的模型、自动配置运行环境,真正做到开箱即用。
要理解这个功能解决了多大的痛点,需要了解本地大模型推理的工具链现状。目前最主流的本地推理方案包括 llama.cpp(一个纯 C/C++ 实现的推理引擎,支持 CPU 和 GPU 混合推理,是 GGUF 格式的发源地)和 Ollama(基于 llama.cpp 封装的更高层工具,提供类似 Docker 的模型管理体验)。虽然这些工具已经大幅简化了本地部署流程,但对新手来说仍然存在不少门槛:需要选择正确的模型文件、配置 GPU 层数分配(n_gpu_layers)、设置上下文长度、处理可能的依赖冲突等。WhichLLM 将「选模型→下载→配置→运行」这条完整链路打通为一条命令,对于不想折腾工具链配置的用户来说,大大降低了入门门槛。
安装与使用
WhichLLM 的安装非常简单,支持两种方式:
# 方式一:pip 安装
pip install whichllm
# 方式二:使用 uvx 一行搞定
uvx whichllm
其中 uvx 是 Python 新一代包管理工具 uv 提供的命令,它可以在临时的隔离环境中直接运行 Python 包,无需预先安装,也不会污染你的系统 Python 环境——特别适合这种「用一次就行」的工具场景。如果你还没有安装 uv,可以通过 curl -LsSf https://astral.sh/uv/install.sh | sh(macOS/Linux)快速安装。
安装完成后,直接在终端运行即可获得针对你当前硬件的模型推荐结果。整个过程无需手动配置任何参数,工具会自动完成所有检测和计算工作。
适合谁用?
- 本地大模型新手:不知道自己电脑能跑什么模型,WhichLLM 直接给答案
- 硬件升级决策者:想知道某块显卡能跑什么级别的模型,用模拟功能提前规划
- 效率优先的开发者:不想花时间在选模型上,一条命令搞定推荐+部署
- 多机器管理者:需要为不同配置的机器快速确定最优模型方案
写在最后
在本地大模型生态日益繁荣的今天,模型数量爆炸式增长,量化版本五花八门,选择困难症只会越来越严重。WhichLLM 的价值在于,它把"选模型"这件原本需要大量经验和时间的事情,变成了一条命令就能完成的自动化流程。
当然,任何自动推荐工具都有其局限性——它无法完全了解你的具体使用场景(比如你是写代码还是写文章,是需要长上下文还是快速响应)。不同任务对模型能力的侧重点差异很大:代码生成更依赖模型的逻辑推理和指令遵循能力,创意写作更看重语言流畅度和想象力,而 RAG(检索增强生成)场景则对长上下文窗口有硬性要求。这些细分需求目前还需要用户根据自身情况做二次筛选。但作为一个快速筛选的起点,WhichLLM 已经做得相当出色。
追星不盲从,实测出真知。 与其在论坛里问"我的显卡能跑什么模型",不如自己跑一下 WhichLLM,用数据说话。
相关推荐
 产品体验
产品体验Qoder vs Cursor实测对比:同样20美金谁更强?
实测对比Qoder和Cursor两款AI IDE,从Agent自主修复能力、人工沟通次数、架构决策等维度评测。Qoder仅需2次沟通完成任务,Cursor需8次。详细分析两者差异,帮你选择最适合的AI编程工具。
 产品体验
产品体验Cursor云Agent演示:打通软件开发全链路瓶颈
深度解析Cursor云Agent最新Demo,展示如何通过云端虚拟机、自动测试产物和全链路控制平面,系统性消除软件开发生命周期中的人类瓶颈,让Agent自主运行、人按需介入。
 产品体验
产品体验Cursor 3.0深度解析:多Agent并行、Design Mode与Best-of-N模型对比
Cursor 3.0正式发布,从AI辅助编程工具进化为Agent舰队指挥中心。本文详解多智能体并行、Design Mode可视化编辑、Best-of-N多模型择优等核心功能,解读AI编程新范式。