五大AI模型做游戏实测对比:零基础编程谁最强

五大AI模型横评:Claude Sonnet 3.7在零基础游戏编程中表现最佳
B站UP主通过让五款AI模型(DeepSeek R1、Claude Sonnet 3.7、ChatGPT o3 Mini、Grok 3、通义千问2.5 Max)生成贪吃蛇网页游戏并增加弹球反弹机制,横向对比其编程能力。结果显示Claude Sonnet 3.7表现最突出,不仅功能正确还自主优化了UI设计;DeepSeek和ChatGPT中规中矩;通义千问和Grok 3未能正确理解弹球运动需求。测试证明零基础用户已可借助AI制作简单网页游戏。
前言:零基础也能做游戏的时代来了
各大AI模型在推理和编程能力上突飞猛进,一个完全没有游戏开发经验的小白,能否借助AI实现零成本的独立游戏制作?B站UP主九龄用一次横向对比测试给出了答案。
本次测试选取了五款当前顶尖的AI模型:DeepSeek R1、Claude Sonnet 3.7、ChatGPT o3 Mini、Grok 3、通义千问2.5 Max,通过统一的提示词,让它们各自生成可运行的网页版贪吃蛇游戏,并在此基础上增加自定义玩法,考验各模型的理解力和编程能力。
测试方法:记事本+浏览器的极简方案
测试方案极其简洁——让AI生成HTML网页游戏代码,将代码粘贴到记事本中保存为.html文件,用浏览器直接打开即可运行。
HTML(超文本标记语言)是构建网页的基础技术,配合CSS(层叠样式表)和JavaScript(脚本语言),可以在浏览器中实现完整的交互式应用。网页游戏之所以成为AI编程测试的理想载体,是因为它不需要安装任何开发环境、编译器或游戏引擎——所有现代浏览器都内置了JavaScript运行时和Canvas/SVG渲染能力。这意味着一个.html文件就是一个完整的可执行程序,极大降低了验证AI代码输出的门槛。这种方式对使用者的技术门槛几乎为零,完美适合验证AI的"开箱即用"能力。
提示词的设计也非常简单直白:要求生成一个贪吃蛇游戏,需要同时适配PC端和手机端。有意思的是,AI每次输出的结果会有差异,部分模型第一次生成的代码无法直接运行,需要多试几次。比如DeepSeek第一次就跑不通,Claude Sonnet 3.7也是在开启思考模式后第二次才运行成功。
这种输出不确定性有其技术原因:大语言模型在生成文本时采用基于概率的采样策略,其中temperature(温度参数)和top-p(核采样)等超参数决定了输出的随机程度。即使输入完全相同的提示词,模型每次采样的token序列都可能不同。在代码生成场景中,这种随机性可能导致变量命名、逻辑结构甚至功能完整性的差异,因此多次尝试是合理的使用策略。
基础贪吃蛇测试结果
在经典贪吃蛇的基础功能上,五款模型都能实现核心玩法,UI界面各有差异。但由于贪吃蛇过于经典,网上现成代码太多,各模型可能直接参考了已有方案,难以体现真正的推理能力差异。
进阶挑战:自定义弹球机制的理解与实现
为了真正拉开差距,测试增加了一个自定义需求:
游戏开始后每隔5秒钟从边界发射一颗弹球,弹球一直存在于游戏内,碰到边界后发生反弹;如果蛇头被任意一颗球击中,游戏结束。
这个需求考验的是AI对复杂游戏逻辑的理解——不仅要实现弹球的生成和物理反弹,还要处理碰撞检测,同时保持原有贪吃蛇玩法不受影响。
从编程实现角度来看,弹球反弹机制属于基础物理模拟。其核心逻辑是:为弹球对象维护位置坐标(x, y)和速度向量(vx, vy),每帧更新位置(x += vx, y += vy);当检测到弹球触及边界时,将对应方向的速度分量取反(如碰到左右边界则vx = -vx)。碰撞检测则需要在每帧计算蛇头坐标与所有弹球坐标的距离,判断是否小于碰撞阈值。这个需求虽然对人类程序员来说是入门级别,但它要求AI同时理解"定时生成"、"持续运动"、"边界反弹"和"碰撞判定"四个独立的逻辑模块并正确组合,是检验AI推理能力的有效手段。
各AI模型表现详解
DeepSeek R1:中规中矩,功能达标
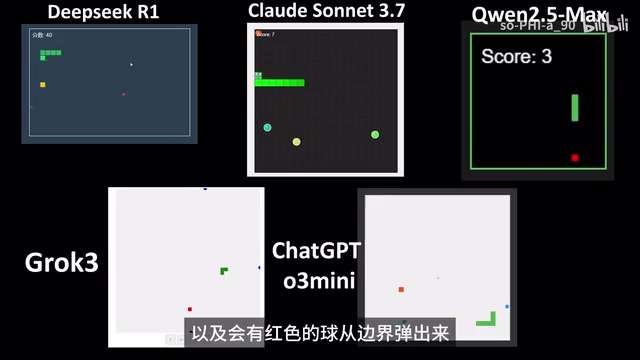
DeepSeek成功实现了核心需求——蛇在吃黄色食物点的同时,红色弹球从边界弹出并持续反弹。基本满足游戏设计思路,但整体呈现比较朴素,没有额外的视觉设计。
Claude Sonnet 3.7:惊喜最大,设计感突出
这是本次测试中表现最亮眼的模型。Claude Sonnet 3.7是Anthropic公司推出的中高端模型,属于Claude 3系列的"Sonnet"层级(介于轻量级Haiku和旗舰级Opus之间)。该模型在代码生成任务上表现突出,部分原因在于Anthropic在训练过程中对代码理解和生成进行了专项优化,同时其RLHF(基于人类反馈的强化学习)流程强调输出的完整性和实用性。
整个作品的完成度非常高:彩色渐变的弹球、蛇头的渐变色设计、精致的UI界面——这些细节完全没有在提示词中要求,是模型自主发挥的结果。它不仅理解了游戏逻辑,还主动进行了美学层面的优化。文中提到的"思考模式"(Extended Thinking)是Claude的一项特色功能,允许模型在生成最终答案前进行更长的内部推理链,类似于Chain-of-Thought提示的内化版本,这有助于处理复杂的多步骤编程任务。
通义千问2.5 Max:理解偏差,弹球不动
千问的模型出现了明显的理解错误——弹球虽然在边界生成了,但完全不动。它没有正确理解"发射"和"反弹"的含义,只是将球静态放置在了边界位置。从技术角度分析,模型很可能只实现了弹球的创建和定位逻辑,但遗漏了为弹球赋予初始速度向量以及在游戏主循环中持续更新弹球位置的关键步骤。
Grok 3:同样存在理解问题
与千问类似,Grok 3也出现了蓝色弹球在边界生成但不移动的问题。两款模型在理解"弹球物理运动"这一需求上都出现了偏差。这说明在面对需要将自然语言描述转化为具体物理模拟逻辑的任务时,不同模型的推理深度存在显著差异。
ChatGPT o3 Mini:功能正确,缺乏设计感
与DeepSeek R1的表现类似,能正确理解游戏设计思路并实现功能,但视觉呈现比较基础,没有额外的设计加分项。
五大AI模型编程能力综合评价
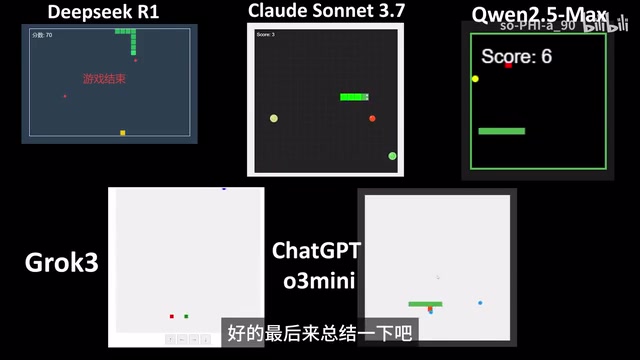
需要说明的是,AI每次运行的结果都不完全一样,本次展示的并非各模型的最佳表现。但经过多次使用和对比,可以得出以下结论:
AI编程能力分层排名
| 层级 | 模型 | 表现 |
|---|---|---|
| 第一梯队 | Claude Sonnet 3.7 | 理解准确 + 编程能力强 + 自主设计感 |
| 第二梯队 | DeepSeek R1、ChatGPT o3 Mini | 功能正确,中规中矩 |
| 第三梯队 | 通义千问、Grok 3 | 存在理解偏差,核心功能未完整实现 |
Claude Sonnet 3.7为何脱颖而出?
- 理解能力:准确把握了所有游戏机制的含义
- 编程能力:代码质量高,运行稳定
- 设计延展:在未被要求的情况下主动优化UI和视觉细节
- 综合体验:最适合零基础用户进行游戏或软件原型设计
零基础AI游戏开发实用建议
对于想要尝试AI游戏制作的零基础用户:
- 首选Claude Sonnet 3.7,综合体验最佳
- 如果第一次生成的代码无法运行,不要放弃,多试几次或切换中英文指令
- 从简单游戏开始(如贪吃蛇),逐步增加自定义需求
- 部分AI平台自带网页预览功能(如Claude的Artifacts功能),可以省去手动保存文件的步骤
AI辅助开发的行业趋势与未来展望
AI辅助编程正在经历从"代码补全"到"完整应用生成"的范式转变。GitHub Copilot、Cursor等工具已经证明AI可以显著提升专业开发者的效率,而本文测试的场景则代表了另一个方向——让非技术用户直接通过自然语言获得可运行的软件。目前这一能力主要局限于前端网页应用和简单脚本,因为这类程序的运行环境统一(浏览器)、依赖少、反馈即时。对于需要数据库、网络通信、多文件架构的复杂应用,AI仍然难以一次性生成完整可用的代码,通常需要人工介入进行调试和集成。
这次测试证明,AI辅助游戏开发已经从概念走向了实用。虽然目前还局限于简单的网页游戏,但随着模型能力的持续提升,零基础用户制作更复杂游戏(如塔防、自走棋)的可能性正在快速打开。
核心要点
- Claude Sonnet 3.7在零基础游戏制作测试中表现最突出,不仅功能正确还能自主优化UI设计
- 通义千问和Grok 3在理解自定义弹球反弹机制时出现偏差,未能完整实现需求
- DeepSeek R1和ChatGPT o3 Mini表现中规中矩,能正确实现功能但缺乏设计感
- 零基础用户仅用记事本和浏览器即可通过AI生成可运行的网页游戏
- AI生成代码存在不稳定性,可能需要多次尝试或调整中英文指令才能成功运行
相关推荐
 产品体验
产品体验Qoder vs Cursor实测对比:同样20美金谁更强?
实测对比Qoder和Cursor两款AI IDE,从Agent自主修复能力、人工沟通次数、架构决策等维度评测。Qoder仅需2次沟通完成任务,Cursor需8次。详细分析两者差异,帮你选择最适合的AI编程工具。
 产品体验
产品体验Cursor云Agent演示:打通软件开发全链路瓶颈
深度解析Cursor云Agent最新Demo,展示如何通过云端虚拟机、自动测试产物和全链路控制平面,系统性消除软件开发生命周期中的人类瓶颈,让Agent自主运行、人按需介入。
 产品体验
产品体验Cursor 3.0深度解析:多Agent并行、Design Mode与Best-of-N模型对比
Cursor 3.0正式发布,从AI辅助编程工具进化为Agent舰队指挥中心。本文详解多智能体并行、Design Mode可视化编辑、Best-of-N多模型择优等核心功能,解读AI编程新范式。