XAI发布Grok Build编程模型,Gemini Spark向Ultra用户开放
概述
AI领域多项重要更新集中发布。XAI正式开放Grok Build 0.1编程模型的公测版本,谷歌Gemini Spark智能体向Ultra订阅用户全面开放,OpenAI的Codex Computer Use功能登陆Windows平台,通应实验室发布视觉语言动作模型,而DeepSeek则因资源紧张继续缩减服务功能。
XAI发布Grok Build 0.1编程模型
XAI宣布Grok Build 0.1现已通过XAI API以公开测试版的形式提供。这是与Grok Build CLI(Command Line Interface,命令行界面——开发者最常用的编程交互方式)同款的模型,专注于编程领域,定位为高性价比的代码生成工具。XAI选择先通过CLI工具让开发者在真实编码场景中验证模型能力,再将经过实战检验的模型开放为API,这种"先验证后开放"的路径有助于建立开发者信任。
在定价方面,Grok Build 0.1的百万token输入价格为1美元,输出价格为2美元,这一价格在当前编程模型市场中具有相当的竞争力。Token是大语言模型处理文本的基本单位,一个token大约对应英文中的3/4个单词或中文中的1-2个字符。模型的API定价通常按百万token(M tokens)计费,分为输入(用户发送给模型的内容)和输出(模型生成的内容)两个维度。在编程场景中,开发者通常需要将大量代码上下文作为输入,而模型生成的代码补全或重构建议则构成输出,因此较低的token价格对于需要频繁调用API的自动化编程工作流尤为重要。
作为对比,OpenAI的GPT-4o输入价格为$2.5/M tokens,Anthropic的Claude 3.5 Sonnet为$3/M tokens,而专注编码的模型如Codestral等也在类似价位区间。Grok Build的定价明显低于主流竞品,体现了XAI以价格优势快速获取开发者市场的策略。对于开发者而言,这意味着可以用较低的成本将专业编程能力集成到自己的应用和工作流中。
值得关注的是,XAI选择将CLI工具中验证过的模型开放为API服务,说明该模型已经在实际编程场景中经过了充分测试,具备一定的成熟度。目前该模型已经开放使用,开发者可以直接通过API接入。
谷歌Gemini Spark面向Ultra用户开放
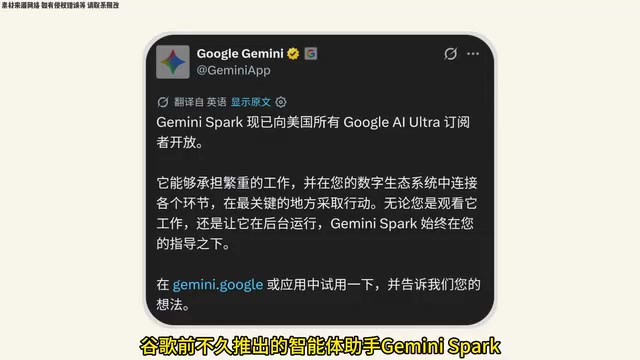
谷歌此前推出的智能体助手Gemini Spark,现已面向美国所有Google AI Ultra订阅用户开放使用。Google AI Ultra是谷歌面向高端用户推出的订阅计划,月费约$249.99,定位为提供最强AI能力的付费层级。这一定价远高于ChatGPT Plus($20/月)和Claude Pro($20/月),反映了谷歌对高端企业用户和重度AI使用者的定位策略。始终在线的智能体需要持续占用计算资源,不同于按次调用的对话模式,高价订阅有助于覆盖持续运行的基础设施成本。该智能体的定位类似于Anthropic的Claude,但其核心差异化优势在于深度融入谷歌生态系统。
AI智能体(AI Agent)与传统对话式AI存在本质区别:对话式AI被动响应用户提问,而智能体能够自主规划任务、调用工具、持续执行复杂工作流。从技术实现上看,智能体通常包含规划模块(将复杂目标分解为子任务)、记忆模块(维护长期上下文和用户偏好)、工具调用模块(与外部API和应用交互)以及反思模块(评估执行结果并调整策略)。Gemini Spark的发布标志着谷歌正式进入"始终在线AI智能体"的竞争赛道。
核心特点
- 全天候在线工作:作为始终在线的AI助手,可以持续处理用户任务,不需要用户反复发起对话。这意味着模型在后台保持活跃状态,能够监控事件触发条件并主动执行预设任务
- 生态整合:对Gmail、Google Calendar、Google Docs、Google Drive等谷歌主流工具具有原生级别的支持和友好度,能够直接读取、编辑和管理用户在这些平台上的数据。这种深度集成通过谷歌内部API实现,相比第三方应用通过OAuth授权访问,具有更低的延迟和更完整的数据权限
- 智能体定位:不仅是对话AI,更是能够主动执行任务的智能代理,可以自主完成多步骤的复杂工作流
这一策略体现了谷歌在AI竞争中的独特优势——利用其庞大的产品生态形成护城河。谷歌的产品矩阵覆盖了用户数字生活的几乎所有环节(搜索、邮件、日历、文档、云存储、地图、YouTube等),全球活跃用户超过20亿。当AI助手能够直接操作用户的邮件、日历、文档等工具时,它就不再是一个孤立的聊天窗口,而是一个真正嵌入用户工作流的数字助理,其实用价值将远超单纯的对话能力。这也构成了强大的用户锁定效应——一旦用户习惯了AI助手管理其谷歌生态中的数据,迁移到其他平台的成本将非常高。
OpenAI Codex Computer Use登陆Windows
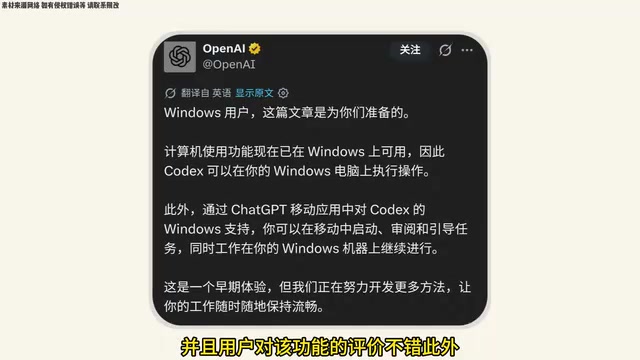
OpenAI宣布Codex中的Computer Use功能现已上线Windows系统。此前该功能已在macOS中测试了一段时间,用户反馈良好。
Computer Use(计算机使用)是当前AI Agent领域最前沿的能力之一,其核心思路是让AI像人类一样通过观察屏幕画面、移动鼠标、点击按钮、输入文字来操控计算机完成任务。这一概念最早由Anthropic在2024年10月随Claude 3.5 Sonnet推出时引起广泛关注,随后OpenAI、谷歌等厂商纷纷跟进。技术实现上,Computer Use依赖多模态模型的视觉理解能力——模型需要"看懂"屏幕截图中的UI元素,理解当前应用状态,然后生成精确的操作指令(如点击坐标、键盘输入等)。
值得注意的是,Computer Use与传统的RPA(Robotic Process Automation,机器人流程自动化)有本质区别。RPA依赖预设的规则和固定的UI元素定位(如按钮ID、XPath路径),一旦界面发生变化就会失效。而基于多模态AI的Computer Use通过视觉理解来识别界面元素,具备对UI变化的适应能力,能够处理未预见的弹窗、布局调整等情况。这使得AI驱动的计算机操控更接近人类的灵活性,但也面临准确率和延迟方面的挑战——当前的Computer Use在复杂操作中仍存在误点击、理解错误等问题,尚未达到完全可靠的程度。
此外,用户现在也可以在ChatGPT移动端访问Windows版本的Codex进行工作,进一步扩展了该功能的使用场景。从macOS扩展到Windows具有重要的商业意义:全球桌面操作系统市场中Windows占据约72%的份额,macOS约占15%,因此Windows版本的上线意味着Codex Computer Use的潜在用户群体扩大了数倍,覆盖了绝大多数桌面用户群体。对于企业用户而言,Windows环境中存在大量仅在该平台运行的行业专用软件(如财务系统、ERP、工业控制软件等),Computer Use在Windows上的可用性将显著扩大其实际应用场景。
通应实验室发布Coin VLA视觉语言动作模型
通应实验室推出了Coin VLA(Vision-Language-Action,视觉-语言-动作)视觉语言动作模型,这是一款专注于通用具身智能的模型。具身智能(Embodied AI)指的是AI不仅存在于数字世界中,还能通过物理载体(如机器人、机械臂、无人机)与真实世界交互,是连接AI与物理世界的关键技术方向。与纯数字AI不同,具身智能需要处理物理世界的不确定性——光照变化、物体遮挡、接触力反馈等,这使得问题的复杂度远超文本或图像生成任务。
技术架构
该模型将不同机器人任务统一建模为三个核心步骤:
- 观察:通过摄像头等传感器感知环境信息,获取视觉输入。通常包括RGB图像、深度图像,部分系统还会融合力觉传感器和本体感觉(关节角度、速度)信息
- 理解:基于语言模型进行推理,将视觉信息与自然语言指令结合,形成对任务的理解。这一步骤的关键在于跨模态对齐——模型需要将"把红色杯子放到桌子左边"这样的语言指令与视觉场景中的具体物体和空间关系对应起来
- 行动:通过专用动作解码器(Action Decoder)将语言模型的抽象表征转化为具体的关节角度、末端执行器位移等物理动作参数,输出机器人可执行的控制指令。动作解码器需要考虑机器人的运动学约束和动力学特性,确保生成的动作在物理上可行
在机器人控制领域,传统方法通常采用模块化流水线:感知模块负责识别物体,规划模块负责路径计算,控制模块负责执行动作,各模块独立开发和优化。这种方法的缺点是模块间的信息损失和误差累积。VLA模型的突破在于采用端到端(End-to-End)方法,将视觉感知、语言理解和动作生成统一到一个神经网络中训练,让模型自主学习从原始视觉输入到最终动作输出的映射关系,实现了"看-想-做"的闭环。
模型以Coin 3.54B(35.4亿参数)为底座,属于轻量级架构。35.4亿参数的规模在大语言模型中属于较小级别(对比GPT-4估计超过1万亿参数,LLaMA 3最大版本为405B),但对于需要在机器人端侧部署的场景尤为重要,因为机器人的计算资源通常远不如云端服务器——边缘设备上的GPU(如NVIDIA Jetson系列)算力有限,且实时控制要求推理延迟在毫秒级别。搭配专用动作解码器,该模型在多项基准测试中表现优秀,超越了此前的最佳专用模型。目前详细的技术报告、代码和论文均已公开发布,这种开源策略有助于推动具身智能社区的快速迭代。
DeepSeek继续缩减服务功能
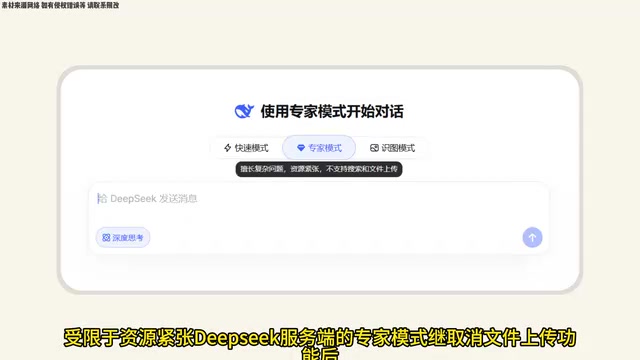
受限于资源紧张,DeepSeek服务端的专家模式在此前取消文件上传功能后,近日又取消了智能搜索功能。官方未明确说明恢复时间。
这一情况的背后反映了AI行业普遍面临的算力供需矛盾。DeepSeek自2024年底发布R1推理模型后用户量激增,但其作为一家相对年轻的AI公司,GPU集群规模远不及OpenAI、谷歌等巨头。专家模式(Expert Mode)通常调用更大参数量或更长推理链的模型,计算成本显著高于快速模式(Quick Mode)。DeepSeek采用的MoE(Mixture of Experts,混合专家)架构虽然在推理效率上有创新——每次推理只激活部分专家网络而非全部参数,但面对爆发式增长的并发请求,硬件瓶颈仍然是制约服务扩展的根本因素。智能搜索功能需要模型在生成回答前先执行网络检索、信息整合等额外步骤,进一步增加了每次请求的算力消耗。
在美国对华芯片出口管制的大背景下,中国AI公司获取高端GPU(如NVIDIA H100/H200)的渠道受限,这使得算力资源的紧张程度更加突出。美国商务部自2022年起实施的出口管制持续升级,不仅限制了芯片本身的出口,还限制了使用这些芯片的云计算服务向中国实体提供。虽然华为昇腾等国产替代方案正在发展,但在软件生态成熟度(CUDA生态的先发优势)、绝对性能和供应量方面仍存在差距。
不过需要注意的是,快速模式下仍然支持以上功能,不受影响。DeepSeek选择优先保障快速模式的完整功能,本质上是在有限资源下的优先级取舍——确保大多数用户的基本体验不受影响,同时牺牲高成本功能来维持系统整体的稳定性和可用性。如何平衡服务质量与用户规模,仍是其需要解决的核心问题。
总结
从今日的动态来看,AI编程工具的竞争正在加剧(XAI、OpenAI同日发力),AI智能体正从对话走向实际操作(Gemini Spark、Codex Computer Use),而具身智能领域也在持续推进。各家厂商都在寻找差异化的竞争路径:XAI以价格优势切入开发者市场,谷歌以生态整合构建护城河,OpenAI以跨平台覆盖扩大用户基数,通应实验室则在具身智能的前沿技术上寻求突破。开发者和用户将从这场竞争中持续受益。
核心要点
核心要点
相关推荐
AI Agent核心架构拆解:从概念到企业级智能体搭建
深度解析AI Agent智能体的三大核心架构:感知模块、大脑模块与行动模块,详解RAG记忆系统、工具调用机制及Chain of Thought推理能力,附企业级智能体开发技能路线图。
200行Python代码从零搭建AI Agent智能体实战教程
用200行Python代码从零搭建AI Agent智能体,逐步拆解提示词、记忆、工具调用、RAG检索增强和Skill技能五大核心模块,适合Python开发者快速入门Agent开发。
Anthropic撤回Claude隐形限制AI研究者的争议政策
Anthropic因Claude Fable/Mythos模型隐形限制前沿LLM开发请求的政策遭社区强烈反对后迅速撤回。本文详解事件始末、隐形安全措施的争议本质、Anthropic的修正方案及对AI行业透明度的深远启示。