小米MiMo-V2.5 Pro实测:代码能力比肩GPT-5,附免费Token申请攻略

小米MiMo-V2.5 Pro开源模型代码生成能力跻身全球顶尖梯队
小米发布的MiMo-V2.5 Pro开源模型在基准测试中接近GPT-5.4、Claude Opus 4.6等顶尖闭源模型水平。实测中,它能在几分钟内生成功能完整的射击游戏,还能一句话生成可交互的管理系统原型,代码生成质量和多模块协调能力相比上一代大幅提升。作为免费开源模型,其性价比优势突出,配合百万亿Token创作者计划,开发者可零成本使用。
小米最近放出了MiMo-V2.5 Pro模型,作为MiMo系列的最新版本,这款模型在代码生成、系统开发方面的表现相当抢眼。B站UP主小刘对它做了一轮全面实测,还分享了百万亿Token创作者计划的申请攻略。下面结合实测结果,聊聊这款模型的真实水平。
MiMo-V2.5 Pro基准测试:跻身全球顶尖梯队
MiMo-V2.5 Pro在多项基准测试中跑出了相当亮眼的分数,和GPT-5.4、Claude Opus 4.6这些全球头部模型放在一起比,部分指标甚至排在前列。从公开数据来看,这款小米出品的开源模型已经有了和国际一线闭源模型正面掰手腕的底气。
这里有必要解释一下基准测试的含义。基准测试(Benchmark)是AI领域评估模型能力的标准化测试集,通常涵盖数学推理(如MATH、GSM8K)、代码生成(如HumanEval、MBPP)、通用知识问答(如MMLU)等多个维度。模型在这些测试中的得分可以横向对比不同模型的能力水平。然而,基准测试存在固有局限:测试集可能被训练数据覆盖导致"数据泄露",且标准化题目无法完全模拟真实开发中的复杂需求、模糊指令和多轮交互场景。因此业界越来越重视"Vibe Check"——即通过真实任务体验来评估模型的实际可用性。
所以基准测试终归只是一个参考维度,模型好不好用还得看实际任务。接下来看看它在真实开发场景里到底表现如何。
实测一:AI生成射击游戏,几分钟搞定
测试者先拿MiMo-V2.5 Pro生成了一款射击小游戏。整个过程不到几分钟,生成的游戏就包含了完整的核心功能:
- 射击机制:玩家可以正常开枪射击
- 敌人生成:野怪自动刷新出现在场景中
- 计分系统:击杀野怪后实时累积分数
- 受击特效:被敌人攻击后有清晰的视觉反馈
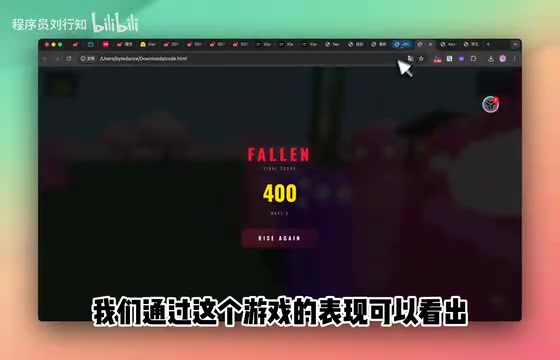
和上一代MiMo模型比,V2.5 Pro的进步非常明显。之前的版本生成游戏时经常翻车——野怪显示异常、跳跃功能直接失效之类的问题层出不穷。而新版本一次生成就能拿到功能完整、可以直接玩的游戏,说明模型在代码逻辑理解和多模块协调上确实有了质的提升。
值得深入理解的是,AI生成一个完整的游戏远不止写出单个函数那么简单。它需要模型同时理解并协调多个代码模块之间的依赖关系——比如射击游戏中,碰撞检测模块需要与敌人生成模块共享坐标数据,计分系统需要监听击杀事件,受击特效需要与生命值系统联动。这种"多模块协调"能力是衡量代码大模型实力的关键指标。早期模型往往能写出单个功能片段,但模块间的接口对接和状态管理容易出错,导致生成的程序"看起来有代码但跑不起来"。MiMo-V2.5 Pro在这方面的进步,反映出其在长上下文理解和代码架构规划能力上的显著提升。
实测二:一句话生成可交互的管理系统原型
更让人意外的是MiMo-V2.5 Pro在系统级开发中的表现。测试者只输入了一句话——"帮我生成一个自媒体管理系统",模型就交出了一套完整的原型。
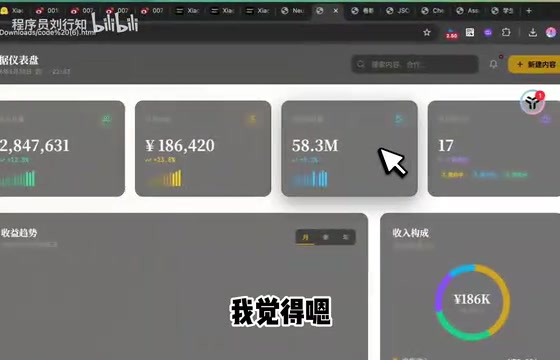
生成结果有几个突出的亮点:
- 每个页面都能点击交互,不是静态截图式的页面
- 多个菜单之间的导航逻辑完整串通
- 一次生成直接可用,不需要来回调试修改
要理解这个成果的技术含量,需要了解传统原型开发的流程。传统的系统原型开发通常需要产品经理用Figma或Axure等工具绘制线框图,再由前端工程师用HTML/CSS/JavaScript实现可交互的原型,整个流程可能耗时数天。AI模型直接通过自然语言生成可交互的HTML原型,本质上是将"需求描述→界面设计→前端编码"这三个环节压缩为一步完成。这里的关键技术挑战在于:模型不仅要理解用户的业务需求,还要自动规划页面结构、设计导航逻辑、编写事件处理代码,并确保所有页面之间的状态传递和路由跳转正确无误。能够一次性生成多页面可交互系统,说明模型具备了相当程度的"全栈工程思维"。
这一点特别值得说道。测试者提到,用DeepSeek V4等国内其他模型跑同样的需求,往往只能生成静态页面,交互能力缺失。Claude Opus 4.6虽然也能做到类似效果,但MiMo-V2.5 Pro作为一款开源免费模型就能达到这个水平,性价比优势太明显了。
说到开源与闭源的差异,这里有必要补充一下当前的竞争格局。开源模型指权重和架构公开、任何人可以下载部署的模型,代表如Meta的LLaMA系列、阿里的Qwen系列;闭源模型则仅通过API提供服务,核心技术不公开,代表如OpenAI的GPT系列、Anthropic的Claude系列。开源模型的优势在于零成本使用、可本地部署保护数据隐私、可针对特定场景微调;闭源模型通常在综合能力上领先,但使用成本高且存在数据安全顾虑。MiMo-V2.5 Pro作为开源模型能逼近闭源顶尖水平,意味着开发者可以在不支付高昂API费用的情况下获得接近一线的代码生成能力,这对整个行业的技术民主化具有重要意义。
除此之外,测试者还用它生成了JSON格式化工具、学生管理系统等多个项目,整体表现流畅稳定。所有测试都是直接在官网选择MiMo-V2.5 Pro模型、用HTML输出即可体验,上手门槛极低。
MiMo-V2.5 Pro综合评价:国产开源模型代码能力新标杆
根据实测体验,测试者给出了自己的主观排名:MiMo-V2.5 Pro的综合代码能力仅次于Claude Opus 4.7和GPT-5.4/5.5,稳居第一梯队。虽然和GPT-5.4相比还有一定差距(主要体现在复杂场景的灵活性上),但考虑到这是一款开源且完全免费的模型,这个成绩已经相当能打了。
具体来看,MiMo-V2.5 Pro的核心优势在于:
- 前端代码生成质量高:一次出活就能用,交互逻辑完整不缺胳膊少腿
- 自然语言理解能力强:简单一句话描述就能生成复杂系统
- 相比上一代进步巨大:之前版本的各种毛病基本都修好了
目前的不足主要是:和GPT-5.4这类顶尖闭源模型相比,在某些复杂任务上的鲁棒性和灵活度还有提升空间。
百万亿Token创作者计划:免费额度申请教程
小米目前推出了百万亿Token创作者计划,开发者可以提交自己的项目来申请免费使用额度。具体申请流程如下:
- 提交项目:在小米官方平台提交你正在开发或计划开发的项目
- 等待审核:平台会评估项目价值后给予批准
- 获得额度:审核通过后每月可获得约200-300元的Token使用额度
- 按月续申:每个月都可以重新提交申请
这里有必要解释一下Token经济的概念,以便理解这个计划的实际价值。Token是大语言模型处理文本的基本单位,中文大约每1-2个字对应一个Token,英文大约每个单词对应1-1.5个Token。使用大模型API时,费用按输入和输出的Token数量计算。以GPT-4级别模型为例,每百万Token的费用通常在几美元到几十美元不等,一个复杂的系统开发对话可能消耗数万Token。对于频繁使用AI辅助编程的开发者来说,月度Token费用可能达到数百甚至上千元。小米推出的百万亿Token创作者计划,本质上是通过补贴开发者使用成本来构建生态——吸引更多开发者基于MiMo模型构建应用,从而扩大模型的影响力和应用场景覆盖面。
据测试者反馈,目前这个计划的审核通过率非常高,他用大号和小号分别申请都顺利通过了。拿到的Token可以直接接入Claude Code等开发工具中使用,全程零成本。对于个人开发者和小团队来说,这是一个非常值得抓住的羊毛机会。
总结:值得一试的免费代码生成利器
MiMo-V2.5 Pro的发布,标志着国产开源大模型在代码生成领域迈上了一个新台阶。它不仅在基准测试中和全球顶尖模型站在同一水平线上,在实际开发任务中也拿出了令人信服的表现。再加上百万亿Token免费额度计划的加持,这款模型对国内开发者来说实用价值极高。
如果你正在找一款免费、好用的AI代码生成工具,MiMo-V2.5 Pro绝对值得试一试。
相关推荐
 产品体验
产品体验Qoder vs Cursor实测对比:同样20美金谁更强?
实测对比Qoder和Cursor两款AI IDE,从Agent自主修复能力、人工沟通次数、架构决策等维度评测。Qoder仅需2次沟通完成任务,Cursor需8次。详细分析两者差异,帮你选择最适合的AI编程工具。
 产品体验
产品体验Cursor云Agent演示:打通软件开发全链路瓶颈
深度解析Cursor云Agent最新Demo,展示如何通过云端虚拟机、自动测试产物和全链路控制平面,系统性消除软件开发生命周期中的人类瓶颈,让Agent自主运行、人按需介入。
 产品体验
产品体验Cursor 3.0深度解析:多Agent并行、Design Mode与Best-of-N模型对比
Cursor 3.0正式发布,从AI辅助编程工具进化为Agent舰队指挥中心。本文详解多智能体并行、Design Mode可视化编辑、Best-of-N多模型择优等核心功能,解读AI编程新范式。