小米mimo-v2-tts踩坑实录:文档矛盾、标签误读、音频串流三大BUG

小米mimo-v2-tts因文档混乱、模型BUG和后端串流三大问题遭开发者集体吐槽
小米开源语音合成模型mimo-v2-tts发布后暴露三大严重问题:文档中括号语法描述与示例代码自相矛盾;模型将音频控制标签内容错误朗读出来,疑似过拟合导致泛化能力不足;后端服务疑似请求串流,返回其他用户的无关音频,存在数据隐私风险。产品完成度严重不足,建议开发者暂避生产环境使用。
mimo-v2-tts是什么?为什么开发者纷纷吐槽
小米近期发布的 mimo-v2-tts 是一款开源语音合成模型,上线后迅速引发了开发者社区的大量负面反馈。从文档逻辑自相矛盾,到模型本身存在严重BUG,再到后端服务疑似串流,这款TTS产品的完成度远低于预期。
本文将从开发者实际使用的角度,逐一拆解 mimo-v2-tts 目前暴露出的三大核心问题,帮助有意尝试的同学提前避坑。
TTS技术背景:音频标签控制为何如此关键
TTS(Text-to-Speech,文本转语音)技术经历了从拼接合成、参数合成到如今基于深度学习的端到端神经网络合成的演进历程。现代TTS系统通常支持通过特殊标记语言(如SSML,Speech Synthesis Markup Language)来控制语音的停顿、语速、音调、情感等维度。
音频标签控制本质上是一种「元指令」机制——模型需要在推理阶段区分「需要朗读的内容」和「需要执行的控制指令」,这对模型的指令跟随能力(Instruction Following)提出了较高要求。工业级TTS产品(如微软Azure TTS、Google Cloud TTS)通常会在训练数据中大量引入带标注的控制样本,并通过严格的回归测试确保标签解析的稳定性。正是因为这一机制的重要性,mimo-v2-tts 在这一环节的失稳才显得格外致命。
文档标注混乱:中括号还是圆括号,说法自相矛盾
对于一款面向开发者的TTS模型来说,文档清晰准确是最基本的门槛。但 mimo-v2-tts 的官方文档在最基础的语法标注上就翻了车。
文档正文中明确写道,音频标签控制使用中括号来标记。然而翻到下面的示例代码,所有示例却全部使用的是圆括号。描述和示例打架,开发者看完直接懵了——到底该用哪种括号?

这个问题看起来不大,但在需要精确控制语音输出的场景下,语法规范不统一会直接浪费大量调试时间。尤其是当你按照文档描述用了中括号却不生效,再换成圆括号又遇到下面要说的BUG时,排查成本会成倍增加。
值得注意的是,这类文档不一致问题往往暴露出更深层的工程文化问题:负责撰写文档的人员与实际开发模型的工程师之间缺乏有效的同步机制,或者文档在代码迭代过程中没有被同步更新。对于一个面向开发者社区的开源项目而言,文档即产品,这一环节的失误会直接影响第一印象。
核心BUG:音频标签内容被模型错误朗读
如果说文档混乱只是影响开发体验,那模型本身的行为不可预测就是真正的硬伤了。
按照文档示例使用圆括号进行音频标签控制时,mimo-v2-tts 有时会将括号内的控制标签内容直接朗读出来,而不是将其作为控制指令处理。
具体表现是这样的:
- 官方提供的5个示例文本均能正常工作,括号内的标签不会被朗读
- 但开发者自行编写的文本,括号内的标签内容却被当作正文念了出来
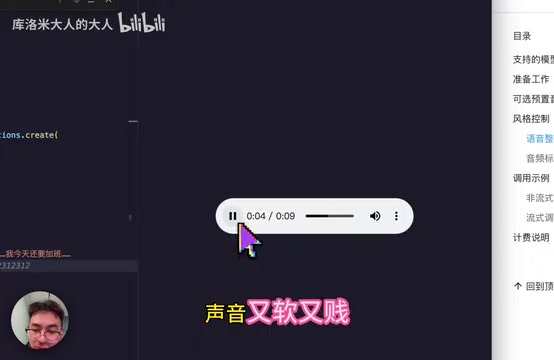
有开发者做了非常细致的排查,逐字节对比了官方示例和自定义文本中括号的ASCII编码,结果发现两者完全一致(均为EFBC88),排除了全角半角或字符编码差异的可能性。
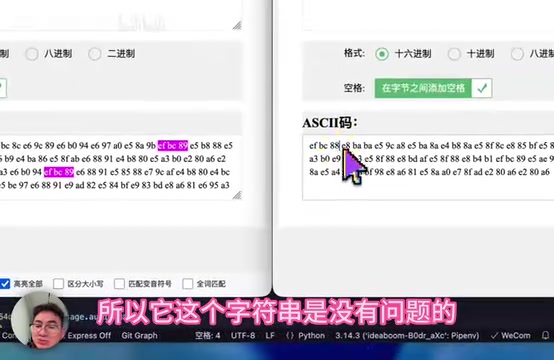
这就意味着问题确实出在模型本身,而不是输入数据的格式问题。从技术角度分析,这种「只对官方示例生效」的现象高度疑似模型在训练时对特定示例文本产生了过拟合(Overfitting)——模型记住了训练集中的特定样本模式,却没有真正泛化出「识别控制标签」的通用能力。一个TTS模型连「哪些内容该读、哪些不该读」都无法稳定判断,音频标签控制功能基本形同虚设。
后端疑似串流:调用返回完全无关的音频
前面的问题好歹还是模型能力层面的不足,接下来这个问题就更加离谱了——多次调用相同的代码,mimo-v2-tts 有时会返回与输入内容完全不相关的音频。
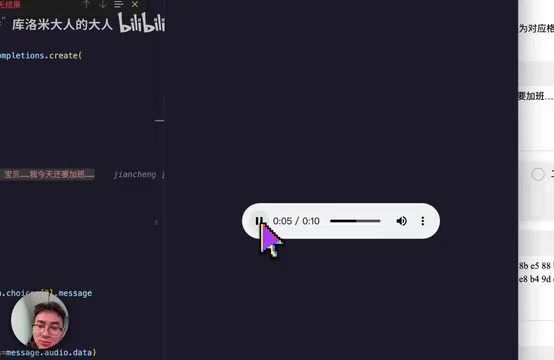
开发者实测发现,生成的音频内容和输入文本毫无关联,听起来像是别的用户请求的生成结果。这强烈暗示后端服务存在请求串流的问题。
从工程原理来看,请求串流(Request Cross-contamination)是分布式推理服务中一类严重的工程缺陷。在高并发场景下,如果服务端的请求队列、缓存或会话状态管理存在竞态条件(Race Condition),就可能导致用户A的生成结果被错误地写入用户B的响应缓冲区。这在流式输出(Streaming)架构中尤为常见,因为流式传输需要维护长连接和中间状态,一旦会话ID映射出错,数据就会「流错地方」。这类问题通常需要通过严格的并发压力测试才能在上线前被发现和修复。
这种问题放在生产环境中后果非常严重:
- 数据隐私风险:用户的文本内容可能通过音频泄露给其他人
- 服务可靠性归零:无法保证每次调用都能拿到正确的结果
- 安全隐患:如果部署到车载语音、智能家居等实时场景,返回错误内容的后果不堪设想
三大问题汇总与严重程度评估
把 mimo-v2-tts 目前暴露出的问题做一个整理:
| 问题层面 | 具体表现 | 严重程度 |
|---|---|---|
| 文档层 | 语法描述与示例代码使用的括号类型不一致 | 中 |
| 模型层 | 音频标签控制功能不稳定,括号内的控制内容有时会被错误朗读出来 | 高 |
| 服务层 | 后端请求疑似串流,返回其他用户的音频结果 | 极高 |
三个层面的问题叠加在一起,基本可以判断 mimo-v2-tts 在发布前没有经过充分的测试和质量把关。
值得一提的是,开源AI模型的发布通常分为「研究预览」和「生产就绪」两个阶段。研究预览阶段允许存在已知缺陷,但需要在README中明确标注局限性;而面向开发者社区的正式发布则应经过完整的测试流程,包括单元测试、集成测试、并发压力测试以及文档一致性审查。小米此次发布 mimo-v2-tts 的方式更接近前者,但缺乏相应的免责说明,导致开发者以生产级标准去评估一个研究阶段的产品,落差感因此被放大。
开发者该怎么办?避坑建议与后续展望
当前阶段的实用建议
考虑到上述问题的严重程度,建议开发者暂时不要在生产环境中接入 mimo-v2-tts。如果出于技术调研目的需要评估,可以参考以下做法:
- 只用官方示例文本测试:自定义文本大概率会触发标签朗读BUG
- 每次生成结果都做人工校验:不要信任单次调用的输出
- 持续关注官方更新:等BUG修复后再重新评估
对小米AI团队的期待
小米在AI领域投入不小,但从 mimo-v2-tts 的表现来看,模型产品化的流程还有很大的改进空间。一个合格的TTS产品上线前,至少应该做到:
- 文档经过严格的一致性审查,描述和示例不能自相矛盾
- 模型行为的边界测试要覆盖充分,不能只保证官方示例能跑通;尤其需要针对「指令跟随泛化能力」进行系统性评估,而非仅验证少数固定样本
- 后端服务的稳定性必须经过压力测试和并发测试验证,请求隔离机制需要在上线前得到充分验证
把一个明显没有经过充分测试的产品推向开发者社区,短期消耗的是用户信任,长期影响的是小米在AI领域的技术口碑。希望团队能尽快定位并修复这些问题,让 mimo-v2-tts 真正成为一个可用的开源TTS工具。
核心要点
- mimo-v2-tts文档存在语法描述与示例不一致的问题,中括号和圆括号混用让开发者困惑
- 模型核心BUG:音频标签控制功能不稳定,括号内的控制内容有时会被错误朗读出来,疑似训练数据过拟合导致泛化能力不足
- 后端服务疑似存在请求串流问题,会返回与输入内容完全无关的其他用户音频,涉及数据隐私风险
- 经ASCII编码对比验证,问题确认出在模型本身而非输入数据格式
- 产品完成度严重不足,建议开发者暂时避免在生产环境中使用,等待官方修复后重新评估
相关推荐
 产品体验
产品体验Qoder vs Cursor实测对比:同样20美金谁更强?
实测对比Qoder和Cursor两款AI IDE,从Agent自主修复能力、人工沟通次数、架构决策等维度评测。Qoder仅需2次沟通完成任务,Cursor需8次。详细分析两者差异,帮你选择最适合的AI编程工具。
 产品体验
产品体验Cursor云Agent演示:打通软件开发全链路瓶颈
深度解析Cursor云Agent最新Demo,展示如何通过云端虚拟机、自动测试产物和全链路控制平面,系统性消除软件开发生命周期中的人类瓶颈,让Agent自主运行、人按需介入。
 产品体验
产品体验Cursor 3.0深度解析:多Agent并行、Design Mode与Best-of-N模型对比
Cursor 3.0正式发布,从AI辅助编程工具进化为Agent舰队指挥中心。本文详解多智能体并行、Design Mode可视化编辑、Best-of-N多模型择优等核心功能,解读AI编程新范式。