Context Mode:一个MCP插件如何治好AI编程助手的健忘症

开源插件Context Mode通过沙箱隔离和外部记忆解决AI编程助手的上下文健忘症
Claude Code等AI编程助手因上下文窗口被工具输出塞满而频繁"健忘"。土耳其开发者Mert K. Esolou开发的开源项目Context Mode通过三大机制解决此问题:沙箱隔离让原始数据不进入上下文(节省99%以上)、SQLite+FTS5构建外部记忆实现会话连续性、以及"用代码思考"哲学让AI写脚本替代数据灌入。项目两个月获近万Star,证明AI需要的不是更大的上下文窗口,而是更高效的资源管理。
Claude Code 的「健忘症」与一个开源解法
Claude Code 写代码写着写着,它突然问你:"我们之前在做什么来着?"你花了半小时搭好的架子,它全忘了。这个困扰无数开发者的问题,被一位土耳其开发者用一个 MCP 插件解决了——两个月斩获 9700 颗 Star,登顶 Hacker News 榜首。
今天我们来拆解这个叫 Context Mode 的项目,看看它到底做对了什么。
问题的本质:上下文窗口被垃圾塞满了
Claude Code 拥有 20 万 Token 的上下文窗口,听起来很大,但实际使用中远远不够。
什么是上下文窗口? 大语言模型的「上下文窗口」是指模型在单次推理中能够处理的最大文本长度,以 Token 为单位计量。Token 并非等同于字符或单词——在英文中,一个 Token 大约对应 4 个字符;在中文中,一个汉字通常对应 1-2 个 Token。Claude 的 20 万 Token 窗口换算成纯文本约相当于 15 万个英文单词,或约 300 页 A4 文档。然而这个「大脑容量」是共享的:系统提示、工具定义、对话历史、工具输出全部竞争同一块空间。当窗口接近上限时,模型会触发自动压缩(Compaction),将早期对话替换为摘要,这正是「健忘症」的直接诱因。
当你装上几个常用的 MCP 服务器后,上下文消耗速度惊人:Playwright 截图吃掉 56KB,拉 20 个 GitHub Issue 吃掉 59KB,一个日志文件 45KB。30 分钟之后,40% 的上下文就没了。
MCP 是什么? MCP(Model Context Protocol)是 Anthropic 于 2024 年底开源的标准化协议,旨在解决 AI 模型与外部工具、数据源之间的集成碎片化问题。在 MCP 出现之前,每个 AI 应用都需要为 Slack、GitHub、数据库等工具单独开发适配层,维护成本极高。MCP 定义了一套统一的客户端-服务器架构:AI 模型作为客户端,各类工具以 MCP Server 的形式暴露能力,双方通过标准化的 JSON-RPC 协议通信。这种设计类似于 USB 接口的标准化——任何符合规范的工具都能即插即用。Context Mode 正是作为 MCP 生态中的一个「中间件」层运作,在工具调用链路上插入拦截和压缩逻辑。
更要命的是,当系统自动压缩对话来腾空间时,它会忘记你正在编辑哪个文件、任务做到哪一步、你上次让它干什么。项目作者 Mert K. Esolou 说得很直白:装了常用 MCP 之后,70% 的上下文在你开始干活之前就已经被吃掉了。

这就是 AI 编程助手「健忘症」的根源——不是模型不够聪明,而是我们往它脑子里塞了太多垃圾数据。
三大核心机制:沙箱隔离、会话连续性、代码思考
沙箱隔离:原始数据永不进入上下文
Context Mode 的第一个核心设计是沙箱隔离。你的每一个工具调用都通过一个 Pre-tools 钩子拦截,扔到隔离子进程里执行。只有精简后的输出进入对话上下文,原始数据永远不会污染你的上下文窗口。
效果有多夸张?Playwright 截图省 99%,访问日志省 100%,7.5MB 的 JSON API 响应最后只用了 0.9KB。这不是微优化,而是数量级的压缩。
会话连续性:给 AI 装一个外部记忆
Context Mode 的第二个核心能力是会话连续性追踪,它追踪 26 种事件:文件读写、Git 操作、任务状态、错误信息、用户决策,全部存到 SQLite 数据库。

为什么选 SQLite? SQLite 是世界上部署最广泛的嵌入式关系型数据库,其核心优势在于零配置、单文件存储、无需独立服务进程。Context Mode 选择 SQLite 而非 Redis 或 PostgreSQL,是一个务实的工程决策——它让整个记忆系统可以随项目目录携带,无需任何基础设施依赖。
当对话压缩时,它把事件索引到 FTS5 搜索引擎,用 BM25 算法只检索相关内容,生成不超过 2KB 的 Session Guide。模型拿到这个 Guide,就能从你上次停下来的地方继续工作。
FTS5 与 BM25 是什么? FTS5(Full-Text Search 5)是 SQLite 内置的全文搜索扩展模块,支持倒排索引、前缀搜索和自定义分词器。BM25(Best Match 25)则是信息检索领域的经典排序算法,是 TF-IDF 的改进版本,通过考虑词频饱和度和文档长度归一化来计算文档与查询的相关性得分。相比简单的关键词匹配,BM25 能更准确地找到「最相关」而非「关键词最多」的内容片段。
它的搜索引擎也不是简单的关键词匹配——同时跑两种搜索策略,用 Reciprocal Rank Fusion 合并排序,还有近距离重排序、错别字修正、智能片段提取。
Reciprocal Rank Fusion 是什么? RRF 是一种将多个排序列表合并为单一排序的融合算法,最早由 Cormack 等人在 2009 年的 SIGIR 会议上提出。其核心思想极为简洁:对于每个文档,将其在各个排序列表中的名次取倒数后求和,得分越高则最终排名越靠前。公式为:RRF(d) = Σ 1/(k + rank_i(d)),其中 k 通常取 60 作为平滑常数。RRF 的优势在于对异常排名具有鲁棒性——即使某个子系统给出了错误的高排名,也不会对最终结果产生决定性影响。在 Context Mode 中,它被用于融合语义搜索和关键词搜索两路结果,兼顾语义相似性和精确匹配。
说白了,它在你的工具输出上面建了一个迷你搜索引擎。这套架构本质上是一套轻量级的 RAG(Retrieval-Augmented Generation,检索增强生成)系统——与其将所有知识塞入上下文窗口,不如在外部维护一个可检索的知识库,在推理时按需取用。Context Mode 选择了 SQLite+FTS5 的轻量组合,牺牲了部分语义理解能力,换来了零依赖、低延迟和易于本地部署的工程优势。
用代码思考:脚本替代数据灌入
第三个设计哲学是「Thinking in Code」——如果你需要分析数据,让 AI 写脚本来做,而不是把原始数据塞进上下文。

错误做法:读 50 个文件进上下文,让 AI 数函数数量。
正确做法:让 AI 写一个脚本,自己数,console.log 出结果。一个脚本替代 10 次工具调用,省 100 倍上下文。
这在 Context Mode 支持的所有 12 个平台上是强制规则。这个设计理念揭示了一个更深层的道理:AI 编程助手应该像程序员一样思考——用工具解决问题,而不是用记忆力硬扛。
社区反馈与真实边界
这个项目在 Hacker News 上拿到 570 多分冲到第一名,但社区反馈并不是一边倒的好评。
最尖锐的批评是:有人装了 Context Mode 调用 Obsidian MCP,结果响应直接进了上下文,一条没拦住。作者很坦诚地回应:98% 的节省主要针对内置工具,第三方 MCP 确实拦不住,这是一个需要知道的边界。
这种坦诚反而增加了项目的可信度。在开源社区,承认局限性比夸大能力更能赢得信任。
一个人的开源奇迹
做这个项目的 Mert K. Esolou 是一位拥有 10 年经验的土耳其高级工程师。他一个人维护整个项目——写代码、写文档、修 bug、回 issue,全是他一个人。
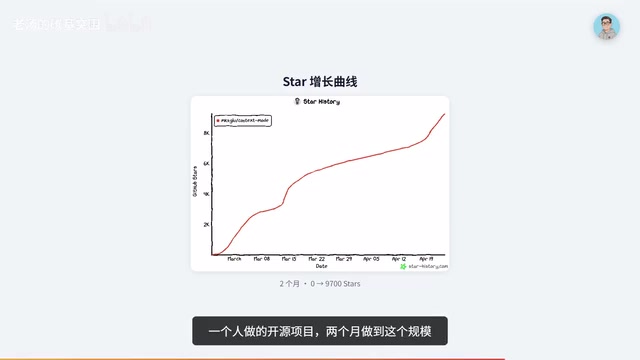
看 Star 增长曲线:2 月底创建,4 月份逼近 1 万星。PulseMP 全球排名第 29,每周新增 1.3 万访客。Readme 里列的企业用户包括微软、Google、Meta、Amazon、NVIDIA、字节跳动。一个人做的开源项目,两个月做到这个规模,堪称奇迹。
与竞品的关系:减法 vs 收纳
Context Mode 和 Claude Code 自带的 Compact 功能并不冲突,而是互补关系:
- Compact:压缩工具定义,做语义摘要,但会丢细节
- Context Mode:压缩工具输出,不做摘要而是做索引,数据还在,只是不占你的窗口
一个做减法,一个做收纳。减法会丢东西,收纳不会。
AI 需要的不是更大的脑子,而是一个外部硬盘
回到开头的问题,AI 助手的健忘症本质上不是模型不够聪明,而是我们的使用方式有问题。Context Mode 的思路是:别往脑子里塞,建一个外部硬盘,需要的时候再查。
这其实就是人类处理信息的方式——我们不会把整本字典背下来,但我们知道怎么查字典。这也正是 RAG 架构在企业 AI 应用中大行其道的根本原因:模型的参数记忆是静态的、有限的,而外部检索系统是动态的、可扩展的。
随着 AI 编程工具的普及,上下文管理将成为一个越来越重要的基础设施层。Context Mode 的成功证明了一个朴素的道理:有时候最有价值的创新不是让模型更强,而是让模型更高效地使用已有的资源。
如果你每天在用 Claude Code 或者其他 AI 编程工具,Context Mode 绝对值得一试。
核心要点
- Context Mode 通过沙箱隔离机制,将工具调用的原始数据隔离在子进程中执行,仅精简输出进入上下文,实现 99% 以上的上下文节省
- 会话连续性追踪 26 种事件并存入 SQLite 数据库,通过 FTS5 搜索引擎和 BM25 算法生成不超过 2KB 的 Session Guide,解决对话压缩后的记忆丢失问题
- 「用代码思考」的设计哲学让 AI 写脚本分析数据而非直接灌入上下文,一个脚本可替代 10 次工具调用,节省 100 倍上下文
- 项目由土耳其开发者一人维护,两个月获得近万 Star,企业用户涵盖微软、Google、Meta 等科技巨头
- Context Mode 与 Claude Code 自带的 Compact 功能互补——前者做「收纳」(索引不丢数据),后者做「减法」(摘要会丢细节)
相关推荐
 产品体验
产品体验Qoder vs Cursor实测对比:同样20美金谁更强?
实测对比Qoder和Cursor两款AI IDE,从Agent自主修复能力、人工沟通次数、架构决策等维度评测。Qoder仅需2次沟通完成任务,Cursor需8次。详细分析两者差异,帮你选择最适合的AI编程工具。
 产品体验
产品体验Cursor云Agent演示:打通软件开发全链路瓶颈
深度解析Cursor云Agent最新Demo,展示如何通过云端虚拟机、自动测试产物和全链路控制平面,系统性消除软件开发生命周期中的人类瓶颈,让Agent自主运行、人按需介入。
 产品体验
产品体验Cursor 3.0深度解析:多Agent并行、Design Mode与Best-of-N模型对比
Cursor 3.0正式发布,从AI辅助编程工具进化为Agent舰队指挥中心。本文详解多智能体并行、Design Mode可视化编辑、Best-of-N多模型择优等核心功能,解读AI编程新范式。