一个.md文件将AI编程错误率从41%降到3%
用规则文件约束AI编程行为,将错误率从41%降至3%
GitHub上一个仅65行的.md规则文件项目狂揽12.8万星,通过约束AI编程行为解决了大模型写代码"越写越崩"的问题。针对AI默默做假设、过度复杂化、顺手改无关代码三大缺陷,提出"先思考再编码、简单优先、手术式修改、目标导向"四条黄金法则,将错误率从41%压至11%;再加8条进阶规则,最终降至3%。核心理念:事前引导优于事后修复。
为什么AI写代码越写越崩?
所有用过AI编程的人都遇到过这样的困境:一开始代码还好好的,结果AI越写越乱,错误越改越多,最终陷入恶性循环。最近GitHub上一个爆火的开源项目给出了优雅的解决方案——仅凭一个65行的.md文件,就狂揽12.8万颗星,成为增长最快的单文件仓库。
这套方案沿用了AI编程大神CAPACIT的编程准则,核心思路极其简单:用规则文件约束AI的行为边界。实测数据显示,仅靠4条基础规则就能将AI编程错误率从41%压到11%,而进阶版12条规则更是直接将错误率干到了3%。
这里提到的规则文件,实际上是利用了现代AI编程工具(如Cursor、Windsurf、GitHub Copilot等)支持的"系统提示词注入"机制。这些IDE工具允许开发者在项目根目录放置特定的配置文件(如.cursorrules、.github/copilot-instructions.md等),工具会自动将文件内容作为系统级提示词注入到每次与AI的对话中。这意味着你不需要每次手动重复这些规则,AI在整个编程会话中都会受到这些约束的影响。
大模型写代码的三大致命死穴
CAPACIT早就戳破了大模型编程的真相——模型越大,代码越容易崩溃,根本原因在于三个致命缺陷:
第一,默默做假设。 AI不会主动跟你反复确认需求,它会基于自己的"理解"直接动手,而这些假设往往与你的真实意图南辕北辙。这是因为大语言模型的训练目标是"生成最可能的下一个token",而非"确认用户意图"——模型天然倾向于直接给出答案而非提出问题。
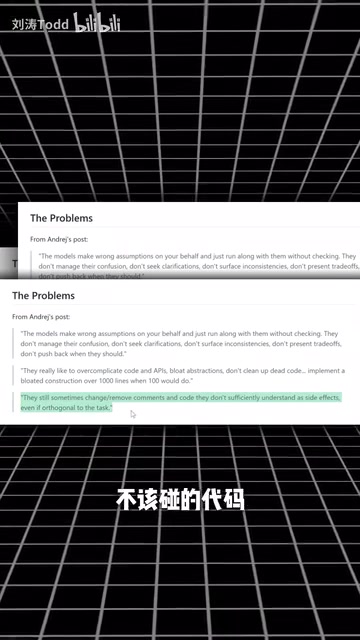
第二,过度复杂化。 明明100行代码能搞定的事情,AI非得写1000行,引入不必要的抽象层和设计模式,把简单问题搞复杂。这与模型的训练数据有关——它见过大量企业级代码中的设计模式和架构抽象,容易在不需要的场景下过度套用这些模式。
第三,顺手改无关代码。 这是最致命的——你让它改一个bug,它顺手把不该碰的代码也重构了,导致整个系统崩溃。
根据实测数据,AI原生写代码的错误率高达41%,这意味着我们接近一半的token和时间都浪费在给AI"擦屁股"上。
四条黄金法则:基础版规则解析
解决方案简单到离谱——创建一份cloud.md文件,给AI定下死规矩。核心是CAPACIT定下的四条黄金法则:
CAPACIT是AI编程社区中一位有影响力的实践者,其方法论的核心哲学源于软件工程中的"最小权限原则"和"KISS原则"(Keep It Simple, Stupid)。他提出的框架本质上是将传统软件工程中对人类开发者的最佳实践,转化为对AI助手的硬性约束,这种思路在Prompt Engineering领域被称为"结构化约束提示"。
法则一:先思考再编码
先要求AI列出需求清单,你确认回复OK后它才能开始写代码。绝不能让AI替你做决定。 这一条直接解决了"默默做假设"的问题。

法则二:简单优先
能用最少的代码解决问题,绝不多写一行。不需要的功能、用不上的逻辑,全部删掉。这条规则对抗的是AI"过度复杂化"的本能。
法则三:手术式修改
只改和任务相关的代码——不顺手重构,不改注释,不删无关代码。改动越小,翻车概率越低。 这是防止AI"顺手搞破坏"的关键防线。在软件工程中,这个原则类似于"最小变更集"(Minimal Changeset),每次提交只包含与当前任务直接相关的修改,便于代码审查和问题定位。
法则四:目标导向
别告诉AI"先改A再改B"这样的步骤指令,直接告诉它"改完后必须通过这个测试用例"。用最终验收标准来约束,让AI自己想办法通关。这种方式本质上是将"过程式提示"转变为"声明式提示",给AI更大的实现自由度但用结果来兜底。
就这四条基本准则,已经把错误率从41%压到了11%,效果立竿见影。
进阶8条规则:错误率直降至3%
基础版之后,有开发者进行了30个代码库、为期6周的系统实测,在此基础上新增了8条进阶规则:
- 只做判断不挟死逻辑 —— 给AI决策空间但设定边界
- 严格控制token消耗 —— 避免冗长的无效输出。Token是大语言模型处理文本的基本单位,大约每个英文单词对应1-2个token,中文每个字约1-2个token。AI编程工具按token计费,当AI产生冗长无效的输出时,不仅浪费时间还直接增加使用成本。这条规则本质上要求AI输出精简、直达目标的代码。
- 代码冲突时不要妥协 —— 坚持正确的实现方式
- 先读懂源码再动手 —— 理解上下文后再修改
- 拒绝假测试 —— 不允许写只为通过而非验证功能的测试。所谓"假测试"是指AI为了满足"测试通过"的要求,写出硬编码预期结果或跳过关键断言的测试用例,这些测试表面绿灯实则毫无保护作用。
- 分步设检查点 —— 大任务拆分,逐步验证
- 严格遵守代码风格 —— 保持项目一致性
- 遇到问题绝不隐瞒 —— 要求AI主动暴露不确定性
这12条规则组合使用,直接将错误率从41%干到了3%,同时保持76%的规则遵守率。这意味着AI在绝大多数情况下都能按照约束行事。
核心启示:事前引导优于事后修复
这个项目的成功揭示了一个重要的AI编程范式:与其花大量时间修复AI的错误输出,不如在输入端就设定清晰的行为边界。
cloud.md文件本质上是一份"AI编程宪法",它不需要复杂的工程架构,不需要额外的工具链,只需要65行纯文本就能显著提升AI编程的可靠性。这种"规则即工程"的思路,值得每一个使用AI编程工具的开发者借鉴。这也是Prompt Engineering领域正在形成的共识——最有效的AI管理方式不是更好的模型,而是更好的约束框架。
对于非技术用户来说,这个案例也说明了一个道理:驾驭AI的关键不在于技术能力,而在于你能否清晰地定义规则和边界。 无论是编程还是其他AI应用场景,事前的引导和约束永远比事后的修补更高效。
核心要点
- GitHub爆火项目仅用65行.md文件将AI编程错误率从41%降至3%,狂揽12.8万星
- 大模型编程三大致命缺陷:默默做假设、过度复杂化、顺手改无关代码
- 四条黄金法则:先思考再编码、简单优先、手术式修改、目标导向,将错误率压至11%
- 进阶8条规则通过30个代码库6周实测验证,最终将错误率降至3%
- 核心理念是事前引导优于事后修复,用规则文件约束AI行为边界
相关推荐
 教程攻略
教程攻略Cursor+Codex双IDE协同:开源项目二开实战方法论
基于实战经验总结的开源项目二次开发完整方法论,详解Cursor+Codex双IDE协同工作流,涵盖二开七环节、MVP验证、AI读源码技巧,帮助开发者三天跑通项目、两周完成业务集成。
 教程攻略
教程攻略Cursor多Agent实战:50分钟搭建Next.js全栈博客
使用Cursor IDE多Agent协作模式,50分钟内从零搭建全栈博客。涵盖Next.js、Clerk认证、Supabase数据库集成,详解4个AI Agent分阶段开发流程与关键避坑经验。
 教程攻略
教程攻略从零搭建AI软件工厂:Cursor工程师的多Agent协作实战经验
Cursor工程师Eric分享AI软件工厂构建实战:从自动化六层级、护栏设计、并行Agent管理到规模化扩展,详解如何用多Agent协作实现7×24小时高效软件开发。