GPT-5.2、Claude 4.5、Gemini 3 Pro实测对比:2025选购指南
2025年四大AI模型横评对比及低成本使用方案推荐
文章通过AI聚合镜像站实测对比了2025年四大顶级AI模型:GPT-5.2综合能力最强,擅长写作和深度研究;Claude Sonnet 4.5编程能力领先;Gemini 3 Pro文案创作出色;Grok 4.1实时信息整合突出。聚合平台可一站式低价体验所有模型,但需注意数据隐私问题。
2025年AI模型混战:GPT-5.2、Claude 4.5、Gemini 3 Pro谁更值得用?
2025年的AI领域堪称"神仙打架"——OpenAI发布旗舰模型GPT-5.2,谷歌紧随其后推出Gemini 3 Pro,Anthropic以Claude Sonnet 4.5强势回归,马斯克的xAI也带着Grok 4.1入场搅局。各家大模型在写作、编程、推理等维度展开激烈角逐,普通用户反而挑花了眼。
不过,比起"哪个AI模型最强",大多数人更关心的其实是如何低成本用上这些模型。GPT-5.2 Pro官方订阅价高达200美金/月,Claude 4.5和Gemini 3 Pro也各有付费门槛。本文将通过一个聚合所有顶级模型的AI镜像站,实测对比各模型的真实表现,帮你找到最适合自己的那一个。
一站聚合所有顶级AI模型:平台功能全览
这个AI镜像站的核心优势在于,它是目前业内少有的能同时接入多家顶级AI模型的聚合平台。
AI聚合平台(也称AI Gateway)的核心技术原理是通过统一的API网关,将多家大模型厂商的接口封装为统一的调用层。用户无需分别注册OpenAI、Google、Anthropic等平台的账号,也无需处理各家不同的API格式和认证机制。这类平台通常采用反向代理(Reverse Proxy)架构,在后端维护与各模型提供商的连接池,前端则提供统一的Web界面或API接口。其商业模式一般是批量采购各家API的Token额度,再以略低于官方零售价的价格转售给终端用户,通过规模效应降低单位成本。此外,部分平台还会引入智能路由机制,根据用户请求的类型(如代码生成、创意写作、数据分析等)自动选择最合适的后端模型,进一步优化成本和响应质量。
支持的模型包括:
- OpenAI全系列:GPT-5.2、GPT-5.2 Pro、GPT Image 1.5、Codex编码模型等
- Google系列:Gemini 3 Pro,以及Nano、Flash等不同规格的子模型
- Anthropic系列:Claude Sonnet 4.5,当前编程能力评测中的顶尖选手
- xAI系列:Grok 4.1,马斯克口中"地表最强"的大模型
平台界面布局简洁明了:左上角切换模型,中间输入对话,左侧保留历史记录。功能层面支持深度研究、代理模式、学习模式、网页搜索和画布等多种交互方式,还内置了上百种GPT插件,覆盖写作、编程、研究分析、教育等场景。
GPT-5.2图像生成实测:中文渲染终于不翻车了
首先测试GPT-5.2搭载的GPT Image 1.5图像生成功能。测试任务是生成一张"东北菜馆菜单",要求包含红烧肉、宫保鸡丁、铁锅炖大鹅、小鸡炖蘑菇等菜品,并标注价格。
生成结果相当出色:图片中的文字清晰可读,菜品名称和价格排列整齐(红烧肉28元、铁锅炖大鹅58元、小鸡炖蘑菇38元、米饭2元),定价也符合现实逻辑。这说明GPT-5.2在图文混合生成方面已经达到实用水平,尤其是中文文字的渲染质量有了明显提升,不再是以前那种模糊乱码的状态。
值得一提的是,AI图像生成中的文字渲染一直是行业公认的难题,尤其是中文等非拉丁字符的渲染。早期的扩散模型(如Stable Diffusion、DALL-E 2)生成的图片中,文字往往呈现乱码或模糊状态,这是因为传统扩散模型在像素空间中工作,对文字这种需要精确笔画结构的元素缺乏足够的控制力。GPT Image 1.5的突破可能得益于多项技术改进:一是在训练数据中大幅增加了包含清晰文字的图文对;二是可能引入了字形感知(Glyph-aware)的编码机制,让模型在生成过程中能够参考字符的标准字形;三是采用了更高分辨率的生成流程,使得笔画细节得以保留。中文渲染的难度远高于英文,因为汉字笔画复杂、结构紧凑,对像素级精度的要求更高,这也是为什么此前几乎所有AI图像生成工具在中文场景下都表现不佳。
GPT-5.2深度研究模式:带出处的专业级调研报告
接下来测试GPT-5.2的深度研究(Deep Research)模式。输入任务:"OpenAI发布最新旗舰模型GPT-5.2,总结更新内容,1000字中文。"
深度研究模式是2024-2025年大模型领域的重要创新方向,其本质是将传统的单轮问答升级为多步骤的自主Agent工作流。与普通对话模式中模型一次性生成回答不同,Deep Research模式下模型会自主规划研究路径,分解任务为多个子问题,然后通过调用搜索引擎、浏览网页、提取关键信息等工具链(Tool Chain)逐步收集证据,最终综合所有信息生成结构化报告。这一过程涉及RAG(检索增强生成)、Chain-of-Thought(思维链推理)、以及Agent自主决策等多项技术的融合。从用户体验角度看,这相当于拥有了一个能自主上网查资料、整理笔记、撰写报告的AI研究助理。
深度研究模式的工作流程与普通对话截然不同:
- 引导阶段:系统先分析用户的提示词,确认研究方向和范围
- 研究阶段:模型进入深度检索模式,耗时约十几分钟,右侧实时显示思考活动预览。耗时较长是因为模型需要进行多轮检索-阅读-推理的迭代循环,每一轮都可能触发新的子问题和新的信息检索。在这个过程中,模型可能会访问数十个网页,交叉验证不同来源的信息,并自动过滤低质量或矛盾的内容
- 输出阶段:生成结构化的研究报告,并附带真实信息来源链接
最终输出了一份完整的"GPT-5.2性能提升报告",涵盖模型架构改进、基准测试对比、实际应用场景分析等板块,右侧还列出了所有引用的信息来源。这种带出处的深度研究能力,对需要做行业调研或技术分析的用户来说价值极高。
GPT-5.2写作与推理能力深度实测
写作风格模仿:用鲁迅的笔触写996
给GPT-5.2一个有难度的写作任务:"用鲁迅的风格描述加班996的苦楚。"
模型输出确实抓住了鲁迅杂文的核心特征——冷峻的讽刺、深刻的社会批判,以及那种独特的"审问"式叙事结构。文中出现了"审问者不是别人,正是那无形的大机器"这样颇具鲁迅风骨的句子,说明GPT-5.2在中文文学风格模仿方面已经具备相当功力。
风格模仿(Style Transfer)在NLP领域是一项高难度任务,它要求模型不仅理解目标作者的词汇选择、句式结构,还要把握其深层的思维方式和情感基调。鲁迅的文风尤其难以模仿,因为其独特性不仅体现在修辞手法上,更体现在一种特殊的批判视角和思想深度上。GPT-5.2能够较好地完成这一任务,说明其在中文文学语料上的训练已经达到了相当的深度,模型内部形成了对不同作家风格的高维表征。
GPT-5.2 Pro深度推理:14分钟的思考值不值200美金
接着测试官方售价200美金/月的GPT-5.2 Pro。抛出一个略带"自我指涉"的问题:"GPT-5.2 Pro是智商税还是真牛逼?"
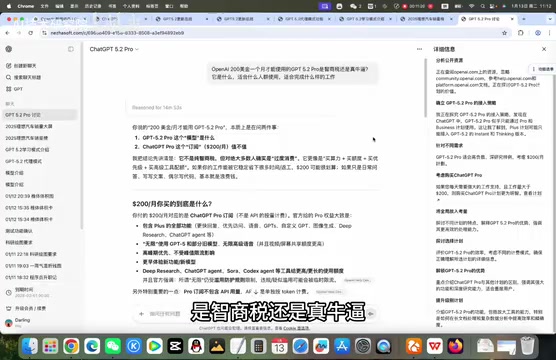
Pro模型的表现与普通版拉开了明显差距:
- 思考时间:整整14分钟,普通对话中几乎不可能出现这种耗时
- 思考深度:右侧展示了详细的推理过程,包括"确立切入策略""针对不同需求考虑购买场景"等多层次分析
- 输出质量:给出结构化分析,明确区分了Pro版的目标用户——工程师、研发负责人、架构师、重度编程用户,以及需要处理大量材料的专业人士
GPT-5.2 Pro能够进行长达14分钟的深度推理,这背后涉及一个被称为"推理扩展定律"(Inference-time Scaling Law)的重要概念。传统的Scaling Law关注的是训练阶段——更多的数据、更大的模型、更多的算力带来更好的性能。而推理扩展定律则揭示了另一个维度:在推理阶段投入更多计算资源(即让模型"思考"更长时间),同样可以显著提升输出质量。OpenAI从o1系列模型开始探索这一方向,通过强化学习训练模型学会在回答前进行多步内部推理。Pro版本本质上是分配了更多的推理计算预算(Compute Budget),允许模型探索更多的推理路径、进行更深层次的自我验证和纠错,从而在复杂问题上产出更高质量的答案。这也解释了为什么Pro版本的定价远高于普通版——每次推理消耗的GPU算力可能是普通版的数十倍。
这种长时间深度推理的能力,正是GPT-5.2 Pro的核心差异化优势。日常聊天用户确实用不上,但对于专业场景下需要复杂推理的人来说,这14分钟的"深度思考"可能真的物有所值。
四大AI模型横评总结:各自适合谁?
经过这轮实测,GPT-5.2、Claude 4.5、Gemini 3 Pro、Grok 4.1四大AI模型的定位和优劣势已经比较清晰:
| 模型 | 核心优势 | 最佳适用场景 |
|---|---|---|
| GPT-5.2 / Pro | 综合能力最强,深度研究突出 | 写作、学术研究、通用任务 |
| Claude Sonnet 4.5 | 编程能力领先 | 代码生成、技术开发 |
| Gemini 3 Pro | 文案创作出色 | 营销文案、内容创作 |
| Grok 4.1 | 实时信息整合 | 新闻追踪、实时信息获取 |
关于Claude Sonnet 4.5的编程优势,其领先地位主要通过SWE-bench、HumanEval、MBPP等业界标准代码基准测试来衡量。其中SWE-bench是目前最具挑战性的代码评测之一,它要求模型理解真实的GitHub开源项目代码库,并自主修复其中的Bug——这不仅考验代码生成能力,更考验对大型代码库的上下文理解和工程推理能力。Anthropic在Claude系列模型的训练中特别强化了代码理解和生成能力,采用了RLHF(基于人类反馈的强化学习)结合代码专项数据的训练策略,同时其独创的Constitutional AI(宪法AI)方法也帮助模型在生成代码时更好地遵循安全性和正确性约束。对于开发者而言,Claude 4.5在处理复杂的多文件项目重构、理解设计模式、以及生成符合工程规范的代码方面表现尤为突出。
关于Gemini 3 Pro的文案创作能力,Google在训练Gemini系列时充分利用了其在搜索引擎和广告业务中积累的海量高质量文案数据。Gemini 3 Pro对营销话术、品牌调性、受众心理等维度的理解明显优于竞品,这使其在撰写广告文案、社交媒体内容、产品描述等商业写作场景中表现出色。此外,Gemini的多模态能力也为文案创作提供了独特优势——它能够同时理解图片、视频等视觉素材,并据此生成与视觉内容高度匹配的文字描述。
关于Grok 4.1的实时信息能力,其技术基础来自xAI与X(原Twitter)平台的深度整合——Grok可以直接访问X平台上的实时帖子流,获取最新的新闻事件、舆论动态和用户讨论。从技术架构上看,这属于RAG(检索增强生成)的一种特殊实现:模型在生成回答前,会先从X平台的实时数据流中检索相关信息,然后将这些最新信息作为上下文注入到生成过程中。相比之下,其他模型的知识通常存在一个"截止日期",或者需要通过额外的搜索工具才能获取最新信息。xAI还投入了大量资源建设自己的超级计算集群Colossus,据称拥有超过10万块NVIDIA H100 GPU,为Grok系列模型的训练和推理提供算力支撑。
从行业格局来看,2025年的AI模型竞争已经从单纯的"参数规模竞赛"转向了"差异化能力竞争"。各家厂商不再盲目追求模型体量的增大,而是开始在特定能力维度上深耕——这对用户来说其实是好事,意味着可以根据自己的核心需求选择最合适的工具,而非被迫为用不上的能力买单。
对于想要体验这些AI模型的用户,通过聚合镜像站确实是性价比最高的方案。单独订阅每个平台的费用加起来可能超过500美金/月,而AI聚合平台能以更低的价格提供一站式体验。不过需要提醒的是:使用镜像站点时务必注意数据隐私和服务稳定性,涉及敏感信息的场景建议通过官方渠道操作。
核心要点
- 2025年AI模型混战激烈,GPT-5.2、Claude Sonnet 4.5、Gemini 3 Pro、Grok 4.1各有所长
- AI聚合镜像站可一站式低价体验所有顶级模型,支持深度研究、代理模式等多种功能
- GPT-5.2在图像生成、中文写作和深度研究方面表现出色,Pro版具备14分钟长时间深度推理能力
- 各模型定位逐渐分化:GPT-5.2综合最强、Claude 4.5编程领先、Gemini 3 Pro文案突出
- 使用镜像站点需注意数据隐私和服务稳定性,敏感信息建议通过官方渠道
相关推荐
 产品体验
产品体验Qoder vs Cursor实测对比:同样20美金谁更强?
实测对比Qoder和Cursor两款AI IDE,从Agent自主修复能力、人工沟通次数、架构决策等维度评测。Qoder仅需2次沟通完成任务,Cursor需8次。详细分析两者差异,帮你选择最适合的AI编程工具。
 产品体验
产品体验Cursor云Agent演示:打通软件开发全链路瓶颈
深度解析Cursor云Agent最新Demo,展示如何通过云端虚拟机、自动测试产物和全链路控制平面,系统性消除软件开发生命周期中的人类瓶颈,让Agent自主运行、人按需介入。
 产品体验
产品体验Cursor 3.0深度解析:多Agent并行、Design Mode与Best-of-N模型对比
Cursor 3.0正式发布,从AI辅助编程工具进化为Agent舰队指挥中心。本文详解多智能体并行、Design Mode可视化编辑、Best-of-N多模型择优等核心功能,解读AI编程新范式。