Claude Code Skill实战:构建标准化代码讲解工作流
Claude Code Skill机制将AI代码讲解从随缘输出变为标准化流水线
文章介绍了Claude Code的Skill机制如何解决AI代码讲解输出不稳定的痛点。Skill通过YAML元数据定义触发条件、Markdown正文定义行为规范,将代码讲解固化为"类比开场→流程图→分步拆解→踩坑提醒"四步标准流程,实现自动触发、输出稳定、团队共享,帮助测试开发工程师快速理解代码、生成边界测试思路并统一评审规范。
代码讲解的痛点:每次提问都像开盲盒
测试开发工程师在日常工作中,经常需要快速理解他人编写的代码逻辑。很多人已经习惯借助AI模型来解释代码,但问题也随之而来——每次让模型解释一段代码,输出质量就像开盲盒:有时候啰嗦半天说不到点上,有时候直接甩一堆术语,新人看不懂,老同事看了想打人。
更关键的是,每次都要临时编写一大段提示词,输出结构完全随缘,无法形成团队统一的规范。那有没有一种方法,能让模型的代码讲解稳定得像流水线一样?答案是:Claude Code 的 Skill(技能)机制。
Claude Code Skill是什么?一句话讲清楚
Skill 是 Claude Code 提供的一种结构化能力定义方式,本质上是将你的最佳实践和方法论固化为一个可复用的模板。你可以把它理解为:把团队里最强的那个代码讲解员的方法论,封装成一个一键调用的标准流程。
要理解 Skill 的定位,需要先了解 Claude Code 本身。Claude Code 是 Anthropic 推出的面向开发者的命令行 AI 编程助手,它直接运行在终端环境中,能够读取项目文件、理解代码上下文并执行操作。Skill 机制是 Claude Code 中的一项高级特性,其底层原理类似于 System Prompt 的结构化封装——通过 YAML 元数据定义触发条件,通过 Markdown 正文定义行为规范,使模型在特定场景下自动加载预设的指令集。这种设计借鉴了软件工程中"配置即代码"(Configuration as Code)的思想,将原本散落在对话中的临时指令提升为可版本控制、可协作维护的工程资产。
与普通的提示词不同,Claude Code Skill 具备以下特点:
- 自动触发:模型根据上下文判断何时启用该 Skill,无需手动指定
- 输出稳定:每次按照预设的结构和规范输出,告别随缘式回答
- 团队共享:一次定义,全组复用,统一代码评审标准
从零搭建代码讲解Skill:完整实操指南
目录结构与核心文件
整个 Skill 的核心就是一个文件,结构非常简洁。文件分为上下两部分:
- 上半部分(YAML 头):定义
Name和Description,这两个字段决定了模型在什么场景下自动触发这个 Skill - 下半部分(Markdown 正文):用 Markdown 写死你的讲解规范,定义输出必须遵循的标准流程
Skill 文件中的 YAML 头部采用了 Front Matter 格式,这是一种广泛应用于静态站点生成器(如 Jekyll、Hugo)和文档系统中的元数据定义方式。它以三条短横线(---)作为分隔符,将结构化的键值对嵌入到 Markdown 文件的头部。在 Claude Code Skill 中,Name 字段用于标识技能名称,Description 字段则充当语义匹配的关键依据——模型会将用户的输入意图与 Description 进行语义比对,当匹配度超过阈值时自动激活该 Skill。这种设计使得触发逻辑既灵活又可控,无需用户记忆特定的命令关键词。
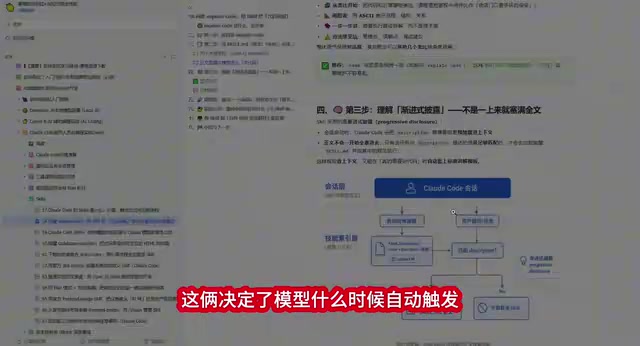
讲解规范的四步标准流程
这个代码讲解 Skill 定义了一套严格的输出标准,模型必须按以下顺序执行:
第一步:类比开场。 用生活中的场景做类比,帮助读者快速建立直觉理解。比如讲解一段 Bearer Token 鉴权代码时,模型会用"夜店保安查手环"来做类比——保安(服务器)检查你的手环(Token),手环有效就放行,过期就拒绝入场。
第二步:画流程图。 用字符化的方式绘制代码的分支逻辑图,把 Substring、条件判断等关键节点标注得明明白白,让复杂逻辑一目了然。
第三步:分步拆解。 逐行或逐块解释代码的实现细节,确保每个关键操作都有清晰说明。
第四步:列出新手踩坑榜。 主动列出常见的易错点和边界情况,这部分对测试用例设计尤其有价值。
实际效果演示:Bearer Token鉴权代码讲解
以一段 Bearer Token 鉴权代码为例,启用 Skill 后模型会主动提醒:"Bearer 后面有个空格,别截成六位"——这种细节,普通问法根本不会主动提及。
这里有必要补充一下 Bearer Token 的技术背景。Bearer Token 是 OAuth 2.0 授权框架中最常用的令牌类型,定义在 RFC 6750 规范中。其工作原理是:客户端在 HTTP 请求的 Authorization 头部携带格式为 Bearer <token> 的字符串,服务端解析该头部、提取 Token 并验证其有效性。这里有一个极易被忽略的细节——Bearer 与 Token 之间必须有一个空格(即第7个字符位置),如果使用 substring 截取时硬编码了错误的偏移量,就会导致 Token 解析失败。这类格式解析问题在实际生产环境中是高频 Bug 来源,也是安全测试中必须覆盖的边界场景。
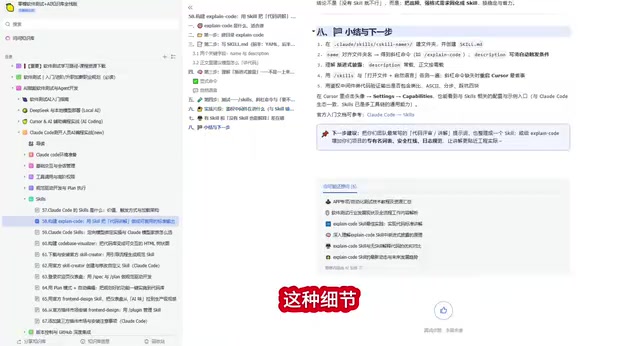
这就是 Claude Code Skill 的核心价值:它不仅回答你问的问题,还会基于预设规范主动补充你可能忽略的关键信息。
测试开发工程师的三大实际收益
快速理解待测代码
面对陌生的业务代码,不用再硬啃源码。模型先用类比帮你建立心智模型,再用流程图梳理逻辑分支,大幅降低理解成本。对于测试开发来说,理解代码是编写高质量测试用例的前提,这一步的效率提升直接影响整体产出。
自动生成边界测试思路
Skill 输出中的"新手踩坑榜"部分,本质上就是边界条件的集合。每一条常见坑点都可以直接转化为边界测试用例,省去了人工分析边界条件的时间。例如"Bearer 后面有空格"这个提示,直接对应一个测试场景:当 Token 前缀格式不正确时,系统是否能正确拒绝。
这背后对应的是软件测试中经典的边界值分析法(Boundary Value Analysis, BVA)。该方法基于一个经验性结论:大量缺陷集中出现在输入域的边界附近,而非中间区域。例如对于 Bearer Token 的解析,边界条件包括:Token 为空字符串、仅包含 Bearer 而无后续内容、Bearer 后有多个空格、Token 中包含特殊字符等。传统做法需要测试工程师凭经验逐一识别这些边界,而 Skill 通过预设的"踩坑提醒"环节,让模型系统性地枚举这些场景,本质上是将边界值分析的思维过程自动化了。
团队代码评审规范统一
在代码评审场景中,团队每个人使用同一个 Skill,输出格式完全一致。新人不再需要反复请教老同事"这段代码什么意思",也省去了翻来覆去解释同一个问题的时间成本。
Skill与普通提示词的核心区别
有人可能会说:不用 Skill 也能让 AI 解释代码啊。确实可以,但两者的差距体现在长期使用中:
| 维度 | 普通提示词 | Claude Code Skill |
|---|---|---|
| 触发方式 | 每次手动输入 | 自动识别触发 |
| 输出结构 | 随缘,不可控 | 固定模板,稳定输出 |
| 复用性 | 一次性使用 | 团队共享,长期复用 |
| 维护成本 | 每次重写 | 一次定义,持续迭代 |
Skill 的本质是将隐性知识显性化、将个人经验组织化。它把最佳实践从个人脑袋里提取出来,变成团队可共享的标准化资产。
这一理念源自日本学者野中郁次郎(Ikujiro Nonaka)提出的 SECI 知识转化模型。该模型将知识分为隐性知识(Tacit Knowledge,存在于个人经验和直觉中)和显性知识(Explicit Knowledge,可以被文档化和传播的知识),并定义了社会化、外化、组合化和内化四种转化路径。Skill 机制恰好对应了"外化"这一环节——将资深工程师脑中"怎样讲清楚一段代码"的方法论,转化为结构化的模板文件。在软件工程团队中,这种知识资产化的实践能有效降低人员流动带来的知识流失风险,也是 DevOps 文化中"一切皆代码"理念在知识管理层面的延伸。
总结:让AI代码讲解从随缘走向标准化
Claude Code 的 Skill 机制为测试开发工程师提供了一种将代码讲解流程标准化的方法。通过定义清晰的输出规范——类比、流程图、分步拆解、踩坑提醒——可以让 AI 的代码解释从"随缘输出"变成"流水线生产"。
对于测试开发团队而言,这不仅是效率工具,更是知识管理工具。将团队中最优秀的代码分析方法论固化为 Skill,让每个成员都能以统一的高标准输出,这才是 AI 辅助开发的正确打开方式。
核心要点
- Claude Code的Skill机制可以将代码讲解流程标准化,输出稳定如流水线
- 代码讲解Skill遵循四步规范:类比开场→流程图→分步拆解→踩坑提醒
- Skill与普通提示词的核心区别在于自动触发、输出稳定和团队可复用
- 对测试开发的三大价值:快速理解代码、自动生成测试思路、统一团队规范
- Skill的本质是将团队最佳实践从隐性知识转化为可共享的标准化资产
相关推荐
 教程攻略
教程攻略Cursor+Codex双IDE协同:开源项目二开实战方法论
基于实战经验总结的开源项目二次开发完整方法论,详解Cursor+Codex双IDE协同工作流,涵盖二开七环节、MVP验证、AI读源码技巧,帮助开发者三天跑通项目、两周完成业务集成。
 教程攻略
教程攻略Cursor多Agent实战:50分钟搭建Next.js全栈博客
使用Cursor IDE多Agent协作模式,50分钟内从零搭建全栈博客。涵盖Next.js、Clerk认证、Supabase数据库集成,详解4个AI Agent分阶段开发流程与关键避坑经验。
 教程攻略
教程攻略从零搭建AI软件工厂:Cursor工程师的多Agent协作实战经验
Cursor工程师Eric分享AI软件工厂构建实战:从自动化六层级、护栏设计、并行Agent管理到规模化扩展,详解如何用多Agent协作实现7×24小时高效软件开发。