Claude Code实战工作流:从需求拷问到AFK智能体自动编码
引言:从哲学到实战
很多关于AI编程的内容都停留在理念层面——"把AI当作初级开发者"、"专注于架构而非实现"。但真正的问题是:具体怎么做? 一位资深开发者最近公开了他使用Claude Code构建真实功能的完整工作流,从模糊的需求到可运行的代码,每一步都有据可循。
这个案例的核心项目是一个课程视频管理器,已有约1200次提交、637个已关闭的Issue。技术栈为React Router + TypeScript + Node + Drizzle ORM + PostgreSQL,配合大量Vitest测试。这不是一个Demo项目,而是一个真正在生产环境中运行的工具。
值得一提的是,这套技术栈的选择本身就颇具深意。Drizzle ORM是近年来在TypeScript生态中快速崛起的类型安全ORM框架,与Prisma等竞品不同,它采用了更贴近SQL原生语法的API设计,开发者可以用TypeScript写出几乎等同于原始SQL的查询语句,同时享受完整的类型推断。这种设计哲学使得它在需要精细控制数据库操作的场景中特别受欢迎。而React Router在v7版本后与Remix框架合并,成为一个全栈框架,支持服务端渲染和数据加载,这解释了为什么该项目能用它同时处理前后端逻辑。配合Vitest这一以极快启动速度著称的测试框架,整套技术栈为AI辅助开发提供了快速反馈的基础设施。
第一阶段:Grill Me——用拷问式对话提炼需求
从模糊想法到精确定义
这次要构建的功能围绕"幽灵课程"(Ghost Course)的概念展开。在原有系统中,课程分为"幽灵"和"真实"两种状态——幽灵课程只存在于数据库中,真实课程则同时映射到文件系统。实际使用中的痛点包括:
- 创建真实课时必须先创建幽灵课时,再手动实体化(Materialize),流程繁琐
- 删除真实课时不能直接操作,必须先转换为幽灵状态
- 无法创建"幽灵课程"——一门尚未映射到文件系统的规划中课程
这些需求一开始非常粗糙,开发者直接对着Claude Code口述想法,然后进入"Grill Me"(拷问我)模式,让AI反过来提问,逐步厘清需求边界。
AI提出的关键问题
Claude Code在探索代码库后,提出了一系列精准的问题:
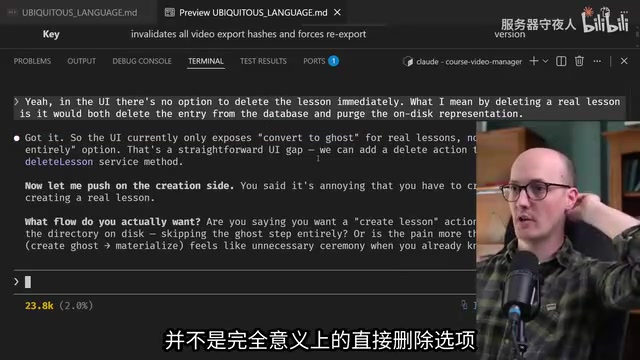
"从代码来看,课程写入服务中删除课时已经可以同时处理幽灵和真实课程。UI里有什么东西强制走先转换为幽灵再删除的流程吗?"
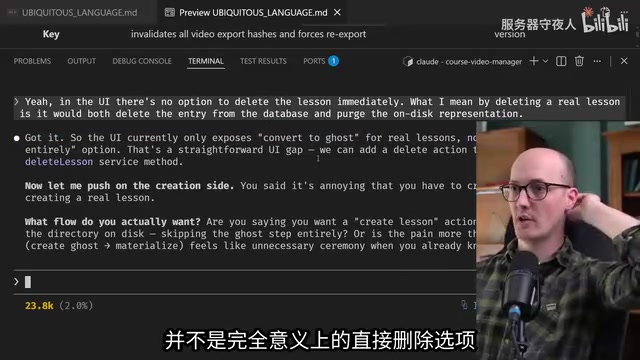
这个问题直接定位了问题本质——不是后端逻辑缺失,而是UI没有暴露直接删除的入口。接着AI又问了一个更深层的问题:
"幽灵课程没有文件路径,其中的章节与课时都会因为必要性而成为幽灵。当你说幽灵课程可以有真实的课时时,在没有文件系统的情况下'真实'意味着什么?"
这迫使开发者澄清了一个关键的设计决策:在幽灵课程中创建真实课时时,应该触发一个实体化级联(Materialization Cascade)——弹窗要求输入文件路径,然后一次性将课程、章节、课时全部实体化。
实体化级联这一概念背后隐藏着经典的分布式一致性挑战。当一个操作需要同时修改数据库记录和文件系统时,就面临事务边界的问题。数据库支持事务回滚,但文件系统操作(创建目录、写入文件)通常不支持原子性回滚。后续QA阶段发现的"非Git仓库中实体化失败导致不同步"问题,正是这一挑战的典型表现。在有Git的场景下,可以利用Git的版本控制能力作为补偿机制:先执行文件操作,如果数据库事务失败则通过git reset回退文件变更。这种补偿事务(Compensating Transaction)模式是处理跨系统一致性的常见策略,也被称为Saga模式的简化版本。
通用语言:人机沟通的基石
整个Grill Me对话过程中,开发者特别强调了领域驱动设计(DDD)中的通用语言概念。他维护了一份"Ubiquitous Language"文档,定义了"幽灵实体"、"实体化"、"实体化级联"等术语。这样做的好处显而易见:
- AI在搜索代码时能精确理解术语含义
- 后续对话中可以用"实体化级联里有个bug"这样简洁的表述
- 函数命名变得自然而一致
通用语言(Ubiquitous Language)是Eric Evans在《领域驱动设计》一书中提出的核心概念之一。其核心思想是:开发团队与业务专家之间应该建立一套共享的、严格定义的术语体系,这套术语不仅用于日常沟通,还应直接反映在代码的命名中——类名、方法名、变量名都应与通用语言保持一致。在传统团队中,通用语言解决的是人与人之间的沟通歧义问题;而在AI辅助开发的语境下,它的价值被进一步放大。大语言模型依赖上下文理解语义,当代码库中的命名与文档中的术语高度一致时,模型能更准确地定位相关代码、理解业务意图,并生成符合项目惯例的新代码。这本质上是将DDD的协作理念从人-人扩展到了人-AI。
这22分钟的拷问环节,本质上完成了传统开发中需求评审会议的全部工作。
第二阶段:从PRD到Issue的自动化拆解
自动生成产品需求文档
拷问结束后,开发者让Claude Code将对话整理成PRD(产品需求文档)。由于整个Q&A过程中问题和答案紧密相邻,注意力机制能很好地捕捉上下文关联,生成的PRD质量相当高。
这里提到的注意力机制(Attention Mechanism)是Transformer架构的核心原理。它允许模型在处理序列中的某个位置时,动态地"关注"序列中其他所有位置的信息,并根据相关性分配不同的权重。在Grill Me对话中,问题和回答在文本序列中物理位置相邻,这意味着当模型生成PRD时,每个需求点都能高效地"回看"到对应的问答上下文,而不会因为信息分散在长文本的不同位置而丢失关联。这也解释了为什么将需求讨论集中在一轮连续对话中完成,比分散在多个会话中效果更好——前者保持了上下文窗口内信息的局部性。
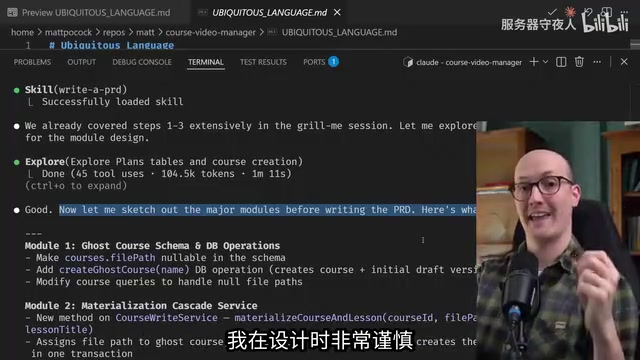
PRD中特别有意思的是模块化设计部分。AI清晰地勾勒出了各个模块需要的变化:
- 课程写入服务新增
materializeCascade方法 - 数据库Schema中课程的
filePath字段改为可空 - 两个新的API端点:直接创建真实课时、直接删除真实课时
- UI层:实体化模态框、两种创建按钮、删除操作
开发者审查时关注的是接口设计而非实现细节——确保可测试性,确保未来的AI智能体能理解模块职责。
拆解为可执行的GitHub Issue
PRD被自动拆解为4个独立的Issue,每个Issue包含:
- 用户故事
- 验收标准
- 阻塞关系
- 测试决策
测试决策的加入尤为关键——它引导后续的AI智能体倾向于采用TDD方式工作,在编码前先建立测试反馈循环。测试驱动开发(TDD)要求在编写功能代码之前先编写测试用例,遵循"红-绿-重构"的循环:先写一个失败的测试(红),再写最少量的代码让测试通过(绿),最后重构代码保持整洁。这种方法论与AI智能体编码有天然的协同效应——对于AI来说,测试用例提供了一个明确的、可机器验证的成功标准。智能体不需要人类实时判断代码是否正确,只需运行测试套件即可获得即时反馈。Vitest以极快的启动速度和热模块替换能力著称,使得AI智能体在每次代码修改后都能在秒级获得测试结果,大幅加速了这一自动化迭代循环。
第三阶段:AFK智能体——离开键盘让AI干活
Sandcastle架构详解
开发者搭建了一套名为"Sandcastle"的AFK(Away From Keyboard)智能体运行环境。核心架构如下:
- Docker容器挂载当前工作目录
- Claude Code在容器内运行,读取GitHub Issue并逐个实现
- 生成的提交被提取为补丁,应用到本地仓库
- 循环执行,最大迭代次数设为100
将AI智能体运行在Docker容器中,这一设计选择有多重考量。Docker容器提供了进程级别的隔离,确保AI智能体的文件系统操作不会意外破坏宿主机环境。通过挂载工作目录(volume mount),容器内的代码变更可以实时同步到宿主机,而补丁提取机制则提供了额外的安全层——不是直接让AI修改本地仓库,而是先生成补丁文件(patch),再由自动化脚本选择性地应用。这种"沙箱"模式在AI自主编码场景中至关重要,因为大语言模型可能执行意料之外的命令(如误删文件、修改系统配置),容器化将潜在损害限制在可控范围内。100次最大迭代的设定则是一种成本控制机制,防止智能体陷入无限循环消耗API调用额度。
启动命令简单到只需pnpm wealth,然后开发者就可以离开去喝茶、散步、甚至和家人聊天。
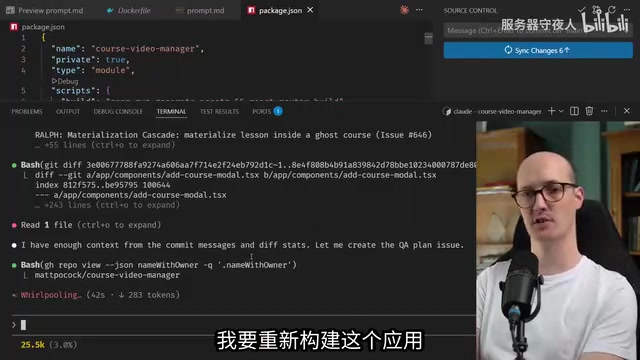
大约一个半小时后回来,智能体已经完成了5轮迭代,生成了6次提交,每次都附带详细的提交信息。
白班与夜班:人机分工的隐喻
这种工作模式被形象地称为"白班"和"夜班":
- 白班(人类):思考、拷问、整理PRD、拆解Issue、做QA验收
- 夜班(AI智能体):读取Issue、编写代码、运行测试、提交代码
核心洞察在于:一旦完成思考和需求定义,人类的工作基本就完成了,直到需要对输出做质量保证。
第四阶段:QA循环——发现AI无法预见的边界情况
反馈驱动的迭代测试
开发者让Claude Code基于最近的提交生成QA计划,然后逐项手动测试。很快就发现了多个问题:
- 添加课程的模态框出现了不必要的"幽灵/真实"标签页切换
- 创建幽灵课程后没有自动导航到新页面,模态框也没关闭
- 缺少加载状态,用户体验混乱
更严重的是一个之前完全没想到的边界情况:如果课程仓库不是Git仓库,实体化过程中某一步失败后,文件系统和数据库会进入不同步状态。这正是前文提到的分布式一致性问题在实际场景中的浮现——没有Git作为补偿事务的回退机制,文件系统的变更无法原子性地撤销,一旦级联操作中途失败,系统就会处于"半实体化"的不一致状态。
"这类事情让我开始思考——纯靠前期规划是行不通的。当你处在QA循环中不断迭代时,你会遇到这些奇怪的边界情况,这在之前真的很难提前规划。"
并行创建Issue与自动修复
每发现一个问题,开发者通过反馈按钮自动创建GitHub Issue,然后AFK智能体在后台持续修复。8分钟内创建了6-7个Issue,智能体同步处理。最终经过8轮迭代、14次提交,功能基本完成。
核心方法论总结
这个案例展示的不是某个神奇的Prompt技巧,而是一套完整的人机协作工程方法:
- Grill Me需求拷问:让AI反向提问,把模糊想法变成精确需求(约22分钟)
- 通用语言维护:建立领域术语文档,确保人机沟通零歧义
- PRD自动生成:利用对话上下文自动输出产品需求文档
- Issue自动拆解:将PRD分解为可独立执行、包含测试决策的任务
- AFK智能体执行:Claude Code在Docker中自主完成编码与测试
- QA迭代循环:人工测试 → 创建Issue → 智能体修复 → 再测试
整个过程中,开发者几乎没有看过一行代码。他关注的是输入(需求定义)和输出(功能表现),而非实现过程。这或许就是AI时代软件工程师角色转变的一个缩影:从写代码的人,变成定义问题和验证结果的人。
核心要点
相关推荐

AI零代码复刻《杀戮尖塔》:从架构到美术的完整实践
B站UP主使用Godot引擎和AI工具链,全程零代码复刻经典卡牌肉鸽游戏《杀戮尖塔》。详解架构文档先行、AI迭代编程、美术素材批量生成的完整工作流,项目已开源。
Claude一句话生成10款网页游戏:零代码AI编程实战
用Claude Code一句自然语言提示词生成2048、五子棋、俄罗斯方块等10款网页游戏,全程零代码开发并部署上线。详解AI编程实战流程、工具选择与核心认知转变。

克隆成功App月入3.5万美元:独立开发者验证式创业方法论
前验光师零基础自学编程,通过克隆已验证的成功应用,运营三款产品月入3.5万美元。详解他的四步筛选法、数据驱动验证流程和递进式获客策略。