Python+LangChain构建AI科研助手:接入MCP消除学术幻觉
用Python+LangChain+Consensus MCP构建无幻觉的AI科研助手
本文针对大模型在学术研究中编造虚假论文引用的幻觉问题,介绍了用Python、LangChain和Consensus MCP构建AI科研助手的完整方案。通过Pydantic定义结构化输出确保数据格式可控,先搭建CLI原型和Flask Web界面验证逻辑,再接入Consensus MCP服务器实时检索真实同行评审文献,从根本上消除学术幻觉。
为什么需要AI科研助手:大模型幻觉是最大障碍
撰写学术论文或毕业论文时,文献检索和趋势分析往往是最耗时的环节。如果能让AI自动搜索相关论文、提取关键公式、分析研究趋势,科研效率将大幅提升。然而直接使用大模型做学术研究存在一个致命问题——幻觉(Hallucination):模型可能编造根本不存在的论文和引用。
幻觉问题的根源在于语言模型的本质工作机制。LLM是一个概率预测系统,通过学习海量文本中的统计规律来预测下一个token,而非真正"理解"或"记忆"事实。当模型被要求生成论文引用时,它会根据训练数据中学到的"论文引用应该长什么样"来生成符合格式的内容——作者名、期刊名、年份、标题都会遵循合理的分布,但组合结果可能从未真实存在。这种现象在学术场景中尤为危险,因为生成的虚假引用往往具有极高的"可信外观",足以骗过粗心的读者甚至审稿人。
本文将详细介绍如何用Python + LangChain构建一个AI科研助手,分三步走:先搭建CLI原型,再套上Web界面,最后通过Consensus MCP服务器接入真实学术文献,从根本上解决幻觉问题。
技术栈与架构设计
整个项目的技术选型如下:
- LangChain:作为Agent框架,负责协调模型调用和工具使用
- OpenAI GPT-5:提供核心推理能力
- Pydantic:定义结构化输出模型,确保返回数据格式可预测
- Consensus MCP:接入真实的同行评审学术文献数据库
为什么需要结构化输出?因为前端展示结果时,必须确保模型返回的数据包含固定字段——论文标题、作者、年份、公式、趋势分析等。依赖模型随意生成的自由文本,UI根本无法稳定解析。
从架构层面看,本项目的核心思路是检索增强生成(RAG,Retrieval-Augmented Generation):将模型的"参数化知识"(训练时学到的推理能力)与"非参数化知识"(实时检索的真实文献)结合,前者负责理解研究问题和组织分析框架,后者负责提供可验证的事实依据。传统RAG需要开发者自行构建向量数据库和检索逻辑,而MCP协议将这些复杂性封装在服务器端,大幅降低了集成门槛。
第一步:用Pydantic定义结构化输出模型
首先安装依赖包:
pip install langchain[openai] pydantic python-dotenv
核心思路是先定义单篇论文(Paper)、公式(Formula)、趋势(Trend)的结构,再组合成完整的报告(Report):
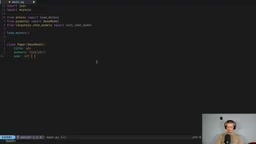
from pydantic import BaseModel, Field
from typing import List, Optional
class Paper(BaseModel):
title: str
authors: List[str]
year: int
venue: Optional[str] = None
url: Optional[str] = None
relevance: str = Field(description="Why this paper is relevant to the topic or research questions")
Pydantic结构化输出在工程层面解决了"最后一公里"问题。大模型默认返回自由文本,前端解析时需要依赖正则表达式或字符串匹配,极易因模型输出格式微小变化而崩溃。通过with_structured_output方法,LangChain在底层将Pydantic模型转换为JSON Schema,注入到模型的system prompt或function calling参数中,强制模型按照预定义的字段类型和约束生成输出。OpenAI的Structured Outputs功能(2024年推出)在API层面提供了语法级别的保证——模型输出会经过约束解码,确保100%符合Schema,而非仅靠prompt引导的"尽力而为"。
公式模型包含名称、LaTeX代码、描述和来源引用;趋势模型则包含标题、描述和参考文献。最终的Report模型将这些组合在一起:
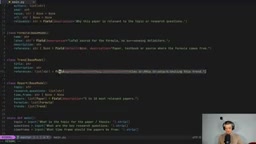
class Report(BaseModel):
topic: str
research_questions: str
timeframe: str
papers: List[Paper] = Field(description="5 to 10 most relevant papers")
formulas: List[Formula]
trends: List[Trend]
第二步:构建CLI原型与Web界面
CLI版本的核心逻辑
初始化聊天模型时,通过with_structured_output方法强制模型按照Report模式返回数据:
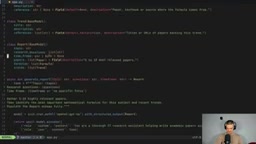
from langchain.chat_models import init_chat_model
model = init_chat_model("openai:gpt-5").with_structured_output(schema=Report)
result = await model.ainvoke([
{"role": "system", "content": "You are a thorough research assistant..."},
{"role": "user", "content": task}
])
用户输入研究主题、研究问题和时间范围后,模型会返回一个完整的JSON对象,包含论文列表、公式和趋势分析。
用Flask搭建Web界面
这里使用Claude Code快速生成了Flask应用的前端界面,包含输入表单和结果展示页面。重点不在于前端设计,而在于验证后端结构化输出的逻辑是否正确。
测试暴露的严重问题
测试结果令人担忧:当搜索"2026年的推荐系统论文"时,模型返回的论文链接几乎全部无效——有的指向404页面,有的跳转到购物网站。这些论文很可能根本不存在,完全是模型的幻觉产物。公式部分也不够精准,比如返回了余弦相似度这种并非"beyond accuracy"的指标。
这正是纯大模型做学术研究的致命缺陷:它无法区分记忆中的真实知识和自己编造的内容。模型在生成"看起来合理"的论文引用时,并没有任何内部机制来验证这些引用是否真实存在——它只是在做统计意义上的"合理续写"。
第三步:接入Consensus MCP消除学术幻觉
Consensus MCP是什么
Consensus是一个基于同行评审学术文献的搜索引擎。通过MCP(Model Context Protocol)服务器,AI Agent可以直接调用其API搜索真实论文。MCP是Anthropic于2024年底提出并开源的标准化协议,旨在解决AI模型与外部工具、数据源之间的集成碎片化问题。在MCP出现之前,每个AI应用都需要为不同的外部服务编写定制化的集成代码,维护成本极高。MCP定义了一套统一的客户端-服务器通信规范,使得任何支持MCP的AI框架都能即插即用地接入任何MCP服务器——类似于USB接口统一了硬件连接标准。目前已有数百个MCP服务器覆盖文件系统、数据库、搜索引擎、学术数据库等场景。
接入Consensus MCP意味着模型不再依赖自身的参数化记忆,而是实时检索真实的学术数据库,从源头杜绝幻觉。
代码改造的三个关键步骤
首先安装MCP适配器:
pip install langchain-mcp-adapters
关键改动有三处:
- 从简单聊天模型升级为LangChain Agent:因为现在需要调用MCP提供的搜索工具
- 配置MCP客户端:通过
mcp-remote处理认证和通信 - 使用tool_strategy替代with_structured_output:让Agent在使用工具的同时保持结构化输出
LangChain Agent基于ReAct(Reasoning + Acting)范式构建,允许模型在推理过程中动态决定是否调用外部工具以及调用哪个工具。其工作循环为:模型接收任务→思考是否需要工具→调用工具获取结果→将结果纳入上下文继续推理→重复直至生成最终答案。与简单的链式调用(Chain)不同,Agent具备条件分支能力,可以根据中间结果决定下一步行动,特别适合
相关推荐
 教程攻略
教程攻略Cursor+Codex双IDE协同:开源项目二开实战方法论
基于实战经验总结的开源项目二次开发完整方法论,详解Cursor+Codex双IDE协同工作流,涵盖二开七环节、MVP验证、AI读源码技巧,帮助开发者三天跑通项目、两周完成业务集成。
 教程攻略
教程攻略Cursor多Agent实战:50分钟搭建Next.js全栈博客
使用Cursor IDE多Agent协作模式,50分钟内从零搭建全栈博客。涵盖Next.js、Clerk认证、Supabase数据库集成,详解4个AI Agent分阶段开发流程与关键避坑经验。
 教程攻略
教程攻略从零搭建AI软件工厂:Cursor工程师的多Agent协作实战经验
Cursor工程师Eric分享AI软件工厂构建实战:从自动化六层级、护栏设计、并行Agent管理到规模化扩展,详解如何用多Agent协作实现7×24小时高效软件开发。